Artificial Intelligence Opportunities for State and Local DOTs: A Research Roadmap (2024)
Chapter: Appendix B: Literature Survey of AI Tools
NCHRP 23-12
ARTIFICIAL INTELLIGENCE OPPORTUNITIES FOR STATE AND LOCAL DOTS – A RESEARCH ROADMAP
Appendix B: Literature Survey of AI Tools
Prepared for NCHRP
Transportation Research Board
of
The National Academies of Sciences, Engineering, and Medicine
TRANSPORTATION RESEARCH BOARD OF THE NATIONAL ACADEMIES OF SCIENCES, ENGINEERING AND MEDICINE PRIVILEGED DOCUMENT
This document, not released for publication, is furnished only for review to members of or participants in the work of NCHRP. This document is to be regarded as fully privileged and the dissemination of the information included herein must be approved by NCHRP.
Abhijit Sarkar
Calvin Winkowski
Han Xu
Balachandar Guduri
Aditi Manke
Matthew Camden
Virginia Tech Transportation Institute
Blacksburg, VA
Permission to use an unoriginal material has been obtained from all copyright holders as needed
Introduction
AI is a research field in computer science. As one of the pioneers in AI, McCarthy (2004) stated, “[AI] is the science and engineering of making intelligent machines, especially intelligent computer programs. It is related to the similar task of using computers to understand human intelligence, but AI does not have to confine itself to methods that are biologically observable” (p. 2).
Over the years, several ML algorithms have been developed to help machines to learn and often to achieve a perception and performance similar to a human. These methods are widely used in industry and in daily life to perform tasks that may take a human a longer time, or where a human may introduce subjective biases. Therefore, over the years, many ML methods have been proven effective in bringing efficiency and increasing accuracy. While ML is more of a research field in computer science, the fundamentals and domain of developments of ML overlaps with multiple other fields of study, including statistics, control systems engineering, information theory, computer programming, psychology, and mathematics. The application domains also expand to many interrelated fields of study such as computer vision, image processing, natural language processing (NLP), communication science, manufacturing, robotics, high-performance computing, data engineering, and transportation research, to mention a few. Therefore, although AI can often be referred to as a field of computer science, it cannot be studied or implemented without understanding the overlapping nature and dependencies with other fields of research (see the AI Literature Review Report deliverable for this project for more details). In this report, our primary focus is the modern development and tool sets related to AI that can benefit state and local DOTs.
Modern development of AI and ML has several components. Most of the modern ML models are based on data-driven approaches. In most of the algorithms developed currently, a machine learns by examples and their associated annotations, similar to a human. This is often referred as supervised learning. Machines can also learn in an unsupervised manner from data where specific annotations are not provided. In the last 30 years, several ML models and philosophies have been developed for addressing both supervised and unsupervised methods. These includes basic models like logistic regression, decision trees, k nearest neighbor, naïve Bayes, etc. More advanced methods like random forests, support vector machines (SVMs), probabilistic graphical models, and neural networks have been developed to address issues with generalization, performance, and speed of operations. However, most of these methods were based on intermediate features that are crafted manually. Also, these methods could not be scaled while learning from large-scale data. Hence, these algorithms were limited to a small domain of applications. However, an ideal ML algorithm should generalize across all domains of applications and should perform with the highest accuracy and speed across all variations. DNN-based methods largely address these issues and help with real-time inference by learning from large-scale data. Also, DNNs are efficient in generating a large number of features that are not manually crafted, hence eliminating a large portion of human bias. The modern revolution in AI was mainly fueled by the advent of DNNs and their variants (see Appendix A for more details). However, in recent years, we have observed that real-world problems vary by different data modalities, data volumes, and accuracy requirements. Therefore, a variety of ML methods may be employed depending on these variabilities. While DNN-based methods can be used to solve several problems and components of the problem, often a simple logistic regression method may provide adequate accuracy for the targeted application. Therefore, in this report we have not limited ourselves to the DNN-based methods, but we have explored all possible solutions that are part of data engineering, data processing, statistical analysis, and advanced analytics. We specifically concentrate on AI tool sets that facilitate data-driven (often big data) techniques and methods to reflect recent trends in AI research.
Data-driven AI Ecosystem

The overall AI ecosystem comprises multiple components as shown in Figure 26. While data reside at the center of the system, they are often augmented by input from humans either in a supervisory role or a supportive role as a facilitator. A human is often required for data annotations and validations. The other key components are the data management and the execution of advanced analytics methods such as ML tools. Any AI practice uses continuous improvement through advancements in data collection, development processes, domain expertise, and AI research. Data are collected through a data collection effort or through a public or private data set, then organized onto a data platform where humans can annotate or leverage existing AI tools to enhance AI annotations. Models are trained and tuned using domain expertise. Even minor domain-specific modifications can significantly improve the performance of algorithms for a specific domain. Trained models are validated against collected test data and other data collections on the data platform. Inferencing for unannotated data generates new results that can then be used to analyze collected data in new ways. Human annotation may be used to enrich the results at much lower cost than a completely human process. Finally, the new annotations are added into the data platform and combined with other AI-generated data and collected data to produce analysis for managing infrastructure, developing policy, making business decisions, or automating processes.
Insights from the analysis of the data combined with AI results can improve future data collection. Results from algorithm validation are especially useful to identify underrepresented scenarios in the data that can be improved through new collection protocols or specific collection efforts. As the domain knowledge advances, with help from AI, new insights can be brought into the algorithms to improve performance. Lastly, pure and applied AI research pushes the envelope of related tasks and creates new algorithm classes and techniques that can be adapted into the developed processes.
Workflow of AI Development
A data-driven AI project can have multiple connected and interdependent components. We can broadly categorize them in six major steps, as shown in Figure 27. A project starts with the business understanding
and goes through different analytics methods before it reaches final deployment. Each of these steps involve a number of key personnel from the institutional hierarchy, including managers, engineers, software developers, domain experts, and end users. Similarly, each of the steps may involve different sets of AI tools. We describe each of the steps briefly in this section.

- Step 1 – Business Understanding: Typically, a project starts from a business understanding and list of requirements. These should lead to a well-defined problem statement. However, the success of an AI project depends on the availability of the right data and a team with the right sets of knowledge and skills. As part of the proposal, the team should identify a good data source and team members who can perform this task. Often this team may involve a third-party solution provider.
- Step 2 – Data Understanding: As most current AI projects are data driven, the next step is to closely study the data and relate them to the problem statement. This step helps to understand key points: 1) if some key data component is missing, 2) if data have been collected properly, 3) if the volume of data is adequate for the project, 4) the noise content of the data set, and 5) the information content of the data set. Understanding the noise and information content are possibly the most important steps in the process. If the noise is too high, then the team should go back to the business
- proposal step and reconsider getting a new source for the data set. Understanding the information content includes statistical analysis of the data, data visualization, and sometimes data transformation.
- Step 3 – Data Preparation: Once the team is satisfied with the available data set, the next step is to prepare the data for AI-based training and modeling. This step often involves data annotations and creating a data structure appropriate for the training. In general, this process requires a high-level of understanding of the ML models that are being used. For example, if the project aims to use convolutional neural networks (CNNs), this step should prepare the annotations, images/videos for training and testing, and structure according to that purpose.
- Step 4 – Modeling: This step mainly involves applying the AI-based methods to the data and training a model for the targeted goal. One of the major goals of this step is to develop a model that can generalize to a data set outside the training set. This way, if during the deployment phase, the system encounters a previously unseen example, it can still provide a right decision. Most of the tasks under this step include fine-tuning model parameters and test variants of model architectures. The team should also confirm that the training process follows standard protocols and can reach a desired accuracy and performance benchmark. This step requires high-performance computing resources to handle high-volume data. Most recent deep learning-based methods require graphics processing unit (GPU) computing resources.
- Step 5 – Evaluation: The evaluation step mainly focuses on understanding the performance of the developed model by testing it on independent sets of data points. Most of the AI process has standard metrics for evaluation. For example, precision, recall, and F-score are some of the metrics used for evaluating performance of classification algorithms. These metrics are used systematically to understand overall efficacy of the algorithm. This step also includes testing on different variants of data. For example, a camera pedestrian detection algorithm can be tested on daytime and nighttime examples to compare the performance using an annotated set of testing examples. Ideally, a model should perform uniformly across all variations of the data, However, comparison of results shows the limitations and scope of the model. If the evaluation shows poor performance, the team should go back either to the model development phase or in the data preparation phase.
- Step 6 – Deployment: The last step of the process is deployment of the AI model. Once the team is satisfied with the evaluation and understands the scope of the model, it is deployed for the required application. In recent years, deployments are executed in cloud-based systems, computing clusters, and through edge computing solutions. For edge computing, the team often needs to prioritize computing resources, software platforms, computing time, and reproducibility. The team may need to use a more adaptable software platform for deployment, and this can be different from the development platform. The team may also need to prune the model (parameters) to fit the constraints of deployment. Often, a separate evaluation step is involved as part of deployment because the original model may be modified during this step. Scaling the deployment is typically straightforward, as the tools used for development are often the best for deployment on server computing and cloud computing; however, many cloud computing vendors are offering custom silicon for faster, more affordable inferencing, which means a significant change to the model.
Key Components of AI Tools
The AI development lifecycle requires adequate tool sets and software to execute efficiently. In the last two decades, many tools have been developed under different platforms. The challenges of AI development are not limited to developing the algorithm; they are intimately tied to managing data and computing at scale. It is impossible to discuss one without the other, and ultimately this drives the discussion around
understanding value and feasibility. This section of the report summarizes the process of AI and the required tools to accomplish AI-related tasks. The main four directions for our review include:
- AI software platforms: We looked at all the software platforms and frameworks used in development, testing, and deployment of AI systems. In this case, we also included traditional ML-based frameworks that are still used by the AI community. The platforms include development platform and language, cloud-based solution services, edge computing and real-world deployment, and open-source toolboxes. We also looked at different visualization and summarization platforms (e.g., Tableau) that may be beneficial for communicating AI-based results.
- Big data management: We live in an era of big data where we collect data from different modalities. For statewide application, it is expected to collect and manage big data. In our survey, we have mainly looked at data management tools, data collection sensors, and data storage mechanisms. We have further investigated their operation modality, security, and limitations.
- Big data processing: It is necessary to understand how to process big data effectively and efficiently. Today, we extensively use high-performance computing through parallelized CPU and GPU computing. However, such processing needs proper coordination, appropriate preprocessing, and scheduling of the data and algorithm. The AI process includes large-scale training and inference, which need to be efficient.
- Cost and benefit: The AI community has been an open community, and that has helped the field to grow. As a result, several AI-based solutions are available open source for research. However, as we move toward more application-focused solutions, enterprises are making more options for paid solutions available. Slowly, subscription- and pay-per-use-based solutions are available from some groups, as are standalone solutions. Availability often depends on the exact solution and the volume and complexity of the intended applications.
AI Software Platforms
Software is an important part of the AI development pipeline. In the overall development of any AI-based project, Step 2 through Step 5 (see Figure 27) are dependent on software development and implementations. In this section, we will mainly discuss some of the key aspects of AI and how different software platforms provide tools and application.
Traditional ML-based Solutions
Current AI development depends on how we develop ML models using traditional methods like SVMs and random forest.
Python Libraries
A Python library is a collection of codes or modules that implement a specific function or operation. It contains modules of exact syntax and semantics of Python language that provide access to system functions such as I/O and other core modules. Programmers can easily implement some operations by importing the functions from the libraries, and thus programming becomes easier. Here we introduce some commonly used libraries:
NumPy4: The name “NumPy” stands for “Numerical Python,” which is an open-source Python library used for data analysis and scientific computing. It provides a huge library of high-level mathematical functions to do operations on large matrices and multi-dimensional data efficiently. NumPy can be regarded as the basis of Python data computing because of the robust data analyses and ML frameworks that use NumPy at the bottom.
Pandas5: This is a data structure and analysis tool built on top of Python. The core of Pandas is an efficient and easy-to-use data type: DataFrame, which is suitable for manipulating data in the Python language environment. Under this data structure, we can clean, organize, summarize, merge, transform, and calculate the data.
SciPy6: SciPy is a software package that builds on NumPy for mathematics, science, and engineering and handles optimization, linear algebra, integration, interpolation, fitting, special functions, fast Fourier transforms, signal processing, image processing, ordinary differential equation solving device, etc.
Scikit-learn (or Sklearn)7: This library is designed to be used in conjunction with the Python numerical science libraries NumPy and SciPy. It is an ML toolbox based on the Python language. Sklearn encapsulates commonly used ML methods, such as classification, regression, clustering, dimensionality reduction, model evaluation, data preprocessing, etc. Programmers only need to call the corresponding interface to implement such operations.
MATLAB® Toolboxes
MATLAB is a proprietary programming language-based computing environment that MathWorks developed. It provides a platform managed by an enterprise. It can be used by beginner to intermediate users of applications, and comes with targeted customer support. Unlike open-source platforms, MATLAB has version control and dependency of the functions across toolboxes. Simulink® and other GUI-based tools provide simulations, quick demonstration, and testing, including to novice programmers. MATLAB provides various toolboxes and functions targeted for specific applications. These functions and applications can work independently as well as with each other. MATLAB comprises several toolboxes
___________________
targeted for specific applications like image processing, statistics, ML, signal processing, etc. Each of these toolboxes has multiple functions. The parallel processing toolbox helps to run MATLAB on computing clusters.
The signal processing toolbox provides functions and applications to process time series or sequential data streams for trend analysis, spectral analysis, and feature engineering. Vehicular data like speed, acceleration, etc., are time series data. The signal processing toolbox helps to process these data, use filters to eliminate noise, and study critical characteristics of this data stream. Many AI-based methods use multimodal data, including time series data.
The Statistics and Machine Learning Toolbox provides functions and applications that can be used for data science applications, where a user can summarize, analyze, and model the multimodal data (Step 2 in Figure 27). The statistics part of the toolbox helps to create descriptive statistics, sample the data using probability distribution functions, conduct analyses of variance and covariance, and perform parametric and nonparametric hypothesis tests. Hypothesis tests such as distribution (e.g., Anderson-Darling and one-sample Kolmogorov-Smirnov), location (e.g., z-test and one-sample t-test), and dispersion (e.g., Chi-square variance) tests determine whether data come from a population with a specific distribution, mean, and variance, respectively. In the ML part, the toolbox provides supervised, semi-supervised, and unsupervised ML algorithms, including SVMs, neural networks, boosted decision trees, k-means, and other clustering methods. It provides various regression models to fit the data using supervised learning. Classification algorithms allow us to classify data and build models using supervised and semi-supervised learning algorithms to handle binary and multiclass problems. The clustering methods based on unsupervised learning techniques help to identify natural groupings and patterns in the data. These models can be built interactively using the Classification and Regression Learner apps or programmatically using AutoML. Furthermore, the toolbox provides intermediate steps such as principal component analysis (PCA), regularization, dimensionality reduction, and feature selection methods that allow the identification of significant variables with the best predictive power. Additionally, it contains a variety of functions that handle out-of-memory issues.
The Mapping Toolbox helps transform data from various sources into geographic coordinates and create map displays from more than 60 map projections. This toolbox allows a user to process and customize the data using trimming, interpolation, resampling, coordinate transformations, spatial resolution adjustment, and other techniques. It supports various file formats such as shapefile, GeoTIFF, KML, and VMAP0 for importing and exporting data.
The Control Systems Toolbox provides algorithms and apps for systematically analyzing, designing, and tuning linear time-invariant (LTI) control systems. It allows defining multi-inputs and multi-outputs (MIMO) and single-input and single-output (SISO) systems as a transfer function, state-space, zero-pole-gain, or frequency response model. The Linear System Analyzer app allows the investigation of the system’s behavior, which can be analyzed and visualized using step response and Bode plot in the time and frequency domains. The Bode loop shaping and the root locus method help to tune the system’s compensator parameters interactively to achieve a specific open-loop response. The toolbox allows automatic tuning of SISO and MIMO compensators in a closed feedback loop. Furthermore, it allows tuning by specifying multiple tuning objectives, such as reference tracking, disturbance rejection, and stability margins. Additionally, this allows validating system design by verifying LTI model characteristics such as rise time, overshoot, settling time, gain and phase margins, etc.
The Optimization Toolbox provides functions to solve various optimization problems for finding parameters that minimize or maximize objectives while satisfying constraints. It includes solvers for linear programming (LP), mixed-integer linear programming (MILP), quadratic programming (QP), second-order cone programming (SOCP), nonlinear programming, constrained linear least squares, nonlinear least squares, and nonlinear equations. It allows users to formulate the continuous or discrete optimization problems using functions and matrices or variables and expressions and solving these in serial or parallel order. The toolbox contains functions that perform design optimization tasks, including parameter
estimation, component selection, and parameter tuning. The toolbox has automatic differentiation of objective and constraint functions that helps to find optimal solutions faster and more accurately.
R Packages
R is a programming language mainly developed for statistical data analysis. R constitutes several associated packages that help in exploratory data analysis and ML-based tasks. Some of the most popular and widely used packages are caret, nnet, E1071, tidyr, mlr3, and xgboosts. The caret package is used for classification and regression-based training and evaluations. E1071 is used for different ML tool sets including clustering methods, SVMs, naïve Bayes, and Fourier transform, among others. The nnet package is used for simulation and testing with neural network-based models. The tidyr is a package that is used for data processing, wrangling, and basic analysis. The mlr3 and xgboosts packages provide tools and functions for several ML and gradient boosting-based algorithms.
Deep Learning Frameworks
Deep learning-based models demand a specific types of software platforms as the overall architecture are different from any of the previously developed algorithm. The extensive use of convolution, requirements of transferability, requirements for flexible design by developers prompted many researchers and enterprises to create new and novel development environments. Therefore, starting from the advent of DNNs, a number of new programming frameworks became popular like Caffe, Torch, TensorFlow, Keras. Each one of them have been successful in their own terms and have been a reliable platform for training and testing of DNN models. With the popularity of python as programming language many of these systems were adapted in Python-based framework. Currently the two of the most popular frameworks, TensorFlow, and PyTorch, use python as its programming environment. In this section we discuss some of these frameworks.
PyTorch: Development8
PyTorch is a deep learning library in academia and industry. It is developed by Facebook AI Research Group and is a Python implementation of the Torch library. As a port of the classic ML library, PyTorch provides Python language users a choice for writing code. PyTorch functionality includes the following:
- Simplicity: The design of PyTorch pursues the least amount of encapsulation and tries to avoid repetitive manufacturing. Unlike other neural network frameworks, its design follows the three low-to-high abstraction levels of tensor → variable → nn.Module, representing high-dimensional arrays (tensors), automatic derivation (variables), and neural networks (layers/modules), respectively. These three abstractions are intricately linked and can be modified and manipulated at the same time. Another benefit of a clean design is that the code is easy to understand. Less abstraction and more intuitive design make the source code of PyTorch quite easy to read.
- Speed: The running speed of the framework has a great relationship with the coding level of the programmer, and the algorithm implemented with PyTorch is considered fast.
- Ease of use: PyTorch has an object-oriented interface design of PyTorch that comes from Torch. The application programming interface (API) design and module interface are consistent with Torch. PyTorch’s interface is in line with people’s thought processes as it allows users to focus on realizing their ideas as much as possible—that is, what they think is what they get—without thinking too much about the constraints of the framework itself.
___________________
TensorFlow: Inferencing9
TensorFlow is a software framework to implement ML algorithms and develop models designed by the Google team. It combines computational algebra with optimization techniques to facilitate the computation of many mathematical expressions. It contains a concept called tensors, which are used to create multidimensional arrays and optimize and evaluate mathematical expressions. This library includes programming support for DNNs and ML techniques and highly scalable computing capabilities with various data sets. TensorFlow uses GPU computing and automated management. It also includes features that optimize the same memory and usage data. TensorFlow’s functionality includes the following:
- Ease of use: The TensorFlow workflow is easy to understand. Its API remains highly consistent, which means there is no need for a user to learn a new set of information from scratch when trying out different models. TensorFlow integrates seamlessly with NumPy, making it easy for most data scientists who understand Python. Unlike other libraries, TensorFlow does not account for compilation time. This allows users to validate their ideas without dedicated waiting time. There are currently a variety of high-level interfaces built on top of TensorFlow, such as Keras, which allows users to take advantage of TensorFlow even if they do not want to implement the entire model by hand.
- Flexibility: TensorFlow can run on machines of different types and sizes. This makes TensorFlow useful on supercomputers, embedded systems, or any other computer in between. The distributed architecture of TensorFlow enables model training on large-scale data sets to be completed in a reasonable time utilizing a CPU, GPU, or both.
MXNet
MXNet is an open-source deep learning framework used to train and deploy DNNs. It is extensible, allows fast model training, and supports multiple languages. The framework has dataflow graphs like Theano and TensorFlow and is well configured for multi-GPU configurations. It has high-level model building blocks like Lasagne and Blocks and runs on any hardware imaginable (including mobile phones). MXNet’s functionality includes the following (Chen et al., 2015):
- Extensibility: MXNet can be distributed to dynamic cloud architectures via distributed parameter servers and can achieve linear scale with multiple GPUs/CPUs.
- Flexibility: MXNet supports both imperative and symbolic frameworks. This makes it possible for developers getting started with deep learning to use imperative programming and easier to debug, modify hyperparameters, etc.
- Multiple language support: MXNet supports development in C++, Python, R, Scala, Julia, Perl, MATLAB, and JavaScript.
- Supporting Internet-of-Things (IoT) and edge devices: In addition to processing multi-GPU training and deploying complex models in the cloud, MXNet can also generate lightweight neural network models that can run on low-power edges such as smartphones or laptops and process data remotely in real time.
Caffe
Caffe, the full name of Convolutional Architecture for Fast Feature Embedding, is a deep learning framework with expressiveness, speed, and modular thinking (Jia et al., 2014). Although its kernel is written in C++, Caffe has Python and MATLAB-related interfaces. Caffe supports many types of deep learning architectures for image classification and image segmentation, and it supports the design of CNNs, region-based CNNs (R-CNNs), LSTM networks, and fully connected neural networks (FCNs). Caffe supports
___________________
accelerated computing kernel libraries based on GPUs and CPUs, such as NVIDIA cuDNN and Intel MKL. Caffe’s functionality includes the following:
- Get started quickly: Models and corresponding optimizations are given in text rather than code. Caffe provides the definition of the model, optimization settings, and pre-trained weights, which allows a user to get started immediately.
- Fast: This framework can run models with massive amounts of data. Caffe is used in combination with cuDNN to test the AlexNet model, and it takes 1.17 ms to process each image on K40.
- Modular: Caffe is easy to expand to new tasks and settings. Programmers can use the layer types provided by Caffe to define their own models.
- Openness: The framework uses open code and reference models for reproduction.
MATLAB
The deep learning toolbox by MATLAB contains various tutorials and examples from data to deployment for users with coding experience from beginners to advanced engineers to create and modify DNNs with ease. The toolbox provides various materials to teach users how to train the models from scratch. Also, various pre-trained deep learning models are available to explore and download. With this toolbox, it is easy to practice coding for deep learning applications such as image recognition, visual inspection, LiDAR, automated optical inspection, classifying images from a webcam, visualizing network features, classifying data using LSTM networks, etc., using step-by-step video tutorials. This toolbox incorporated specialized functionality for various applications such as computer vision, reinforcement learning, signal processing, radar, LiDAR, and wireless. Deep learning for computer vision contains several examples and tutorials for semantic segmentation, object detection, and image recognition. Some are image and video labeling, image datastore, image and compute vision-specific processing techniques, and the ability to import deep learning models from TensorFlow-Keras and PyTorch for image recognition. Using MATLAB, Simulink, and the Reinforcement Learning Toolbox™, users can explore and practice complete workflow with examples for simple control systems, autonomous systems, robotics, and scheduling problems. This toolbox provides opportunities to develop predictive models to solve various signal-processing applications. It enables the application of AI techniques to radar and LiDAR applications. To leverage model architectures developed by various community members, this toolbox contains simple models (e.g., AlexNet, VGG-16, VGG-19, GoogleNet), higher accuracy models (e.g., ResNet-50, Inception-v3, Densenet-201, Xception), models for edge deployment (e.g., SqueezeNet, MobileNet-v2, ShuffLeNet, EfficientNet-b0), and models from other frameworks. Developers can seek help, the latest insights, and information from the deep learning community and experts. MATLAB provides a 30-day free trial for exploring this toolbox.
Open-source Toolboxes
Recent AI and ML development is largely owed to large-scale open-source development platforms and source codes. Many researchers have open sourced their code base for non-commercial purposes, which has helped the research community immensely in terms of reproducibility of research and developing new algorithms on top of existing methods. This is one of the major reasons for the large growth of the AI community. In this section, we provide examples of such open-source code bases that can be used for different tasks.
OpenMMlab10
OpenMMLab is an open-source algorithm platform of MMLab, a joint laboratory of the Chinese University of Hong Kong and SenseTime. OpenMMLab is a computer vision algorithm system and framework involving more than 20 research directions, more than 300 algorithms, and more than 2,300 pretraining models. After years of development, OpenMMLab has gradually formed a complete system and organizational structure, which can provide open basic technical support, interface standards, and algorithm frameworks. These open resources have been actively used and contributed by more and more AI researchers and have had an important impact on the development of the AI community. Most of OpenMMLab’s libraries are based on the deep learning PyTorch framework. The algorithms are at the forefront of current technologies and have much documentation. OpenMMLab is mainly targeted for computer vision-based work and covers object detection, semantic segmentation, action recognition, LiDAR data processing, optical character recognition, body pose estimation, etc. All these algorithms are under the same ecosystem, which helps researchers with development and testing.
Detectron211
Detectron2 is Facebook AI Research’s next-generation open-source object detection system, a complete rewrite of the previous version of Detectron. With this framework, users can train various state-of-the-art models for detection tasks such as bounding box detection, instance and semantic segmentation, and panoptic segmentation. There are many pre-trained models in the framework that can “plug and play.” The design based on PyTorch can provide a more intuitive imperative programming model, so developers can iterate model design and experiment more quickly.
Starting with Detectron2, Facebook introduced a custom design that allows users to insert customizations into almost any part of the object detection system. Its scalability also makes Detectron2 more flexible. Detectron2 was rewritten from the ground up to resolve several implementation issues in the original Detectron, making it faster than the original Detectron.
OpenCV
OpenCV (Open-Source Computer Vision Library) is an open-source computer vision library whose main algorithms involve image processing, computer vision, and ML-related methods. Many commonly used computer vision algorithms are implemented in its source code files. OpenCV can be used to develop real-time image processing, computer vision, and pattern recognition programs.
OpenCV consists of a series of C functions and C++ classes, and it has C, C++, Python, and Java interfaces. The current software development kit (SDK) already supports application development in languages such as C++, Java, and Python. Currently, the newly developed algorithms and module interfaces of OpenCV are based on C++. It covers computer vision applications such as industrial product inspection, medical imaging, drone flight, unmanned driving, security, satellite map and electronic map stitching, information security, user interface, camera calibration, stereo vision, and robotics.
OpenCV was originally initiated and developed by Intel Corporation, licensed under the BSD license, and can be used for free in commercial and research fields. Currently, the American robotics company Willow Garage provides the main support for OpenCV.
___________________
Statistical Analysis Platforms
SAS
SAS is a command-driven statistical software used for data analytics and visualization. It can perform advanced analysis, business intelligence, predictive analysis, and data management. The statistical software provides more than 90 prewritten procedures for data analysis. The tools provided to meet some of the statistical needs include analysis of variance, regressions, Bayesian inference, and model selection for large data sets.
SAS also supports AI technologies such as ML, computer vision, NLP, forecasting, and optimization. For example, the visual data mining and ML in SAS help identify common variables across multiple models and important variables that are selected across all models, and they help in the assessment of results for all models.
R
R is an open-source programming platform that is freely available. One of the strong points of using R is its data visualization tool. Packages that are available for visualization include ggplot2, Lattice, ggvis, googleVis, rcharts, and many others. R allows users to build two-dimensional graphs as well as three-dimensional models. It also supports various data structures, operators, and parameters (e.g., arrays, matrices, and loops) and can be easily integrated with other programming languages like C, C++, and Fortran.
R allows users to perform multiple ML operations like classification, regressions, data cleaning, or data wrangling. Packages that can be used to implement ML in R include: DataExplorer, Dalex (Descriptive Machine Learning Explanations), Kernlab, rpart, etc.
Python
R is a comprehensive tool for pure statistical analysis. However, Python-based methods are used to build a complex analysis pipeline that requires multiple components such as statistics, image processing, control, etc. There are several packages used for statical analysis-based methods. Numpy, Scipy, Pandas, and Statsmodel are some popular ones used for statistical analysis. Pandas mostly helps in data preparation and framework creation. Scipy has capabilities of all statistical processes, including hypothesis testing, t-test, etc. Numpy and Statsmodel help in developing linear models and analysis of variance types of operations. Overall, Python is a comprehensive package that can be used as an add-on for statistical analysis.
Development and Deployment
Initial development of AI models is an iterative process that requires reevaluation after changes are made to optimize the model for the constraints of the specific problem, but most often the focus is on accuracy and speed. While objectives like reproducibility, running on edge computing hardware, and code sharing are considerations during the development phase, they are often solved in the deployment phase.
- Robot Operating System (ROS): ROS is a C++ and Python framework used to build robotics applications. It has found use in edge computing and data collection because of its focus on portability and support for a variety of sensors and devices. At its core, ROS is a message passing system and suite of compatible libraries that enable developers to easily collect data from vision, LiDAR, and other sensors, process, and store that data, visualize the data, and perform real-time decision making. In the AI space, ROS is used in both data acquisition and building responsive AI tools.
- C, C++: Many AI libraries in Python, R, or MATLAB are written in C or C++ natively for performance purposes. The user-facing libraries are wrapped around these optimized functions and data structures to simplify development. When deploying an AI model, some developers choose to port the entire code base to C++ to get the best performance possible, especially if operating on low resource systems like edge computing devices.
- Docker, Singularity: Docker and Singularity are two tools that build software images complete with all the dependencies of the developed code. They serve a similar role as virtual machines but do not emulate hardware, meaning they execute just as fast as native code. An image built on one machine could then be run anywhere else with Docker or Singularity without having to install dependencies. In the AI space, libraries develop so quickly that the version from 2 years ago may no longer be available or work with other versions. These containerizations allow executing code in the exact environment in which the code was known to work and executing it on any new machine. Many open-source AI models and frameworks are starting to support Docker to easily deploy their software.
- GitHub, Atlassian, GitLab: A code repository to track changes to algorithms is critical to reproducibility and managing changes in deployed systems. Being able to easily revert to a previous version of the code is necessary for any production deployment of code. These tools also provide mechanisms for code review, discussion, user feedback, and bug reporting. Lastly, these platforms can be used for continuous integration and deployment. This automates testing code changes and deploying changes to production systems, enabling agile development.
- Linux: Linux is the de facto standard operating system for developing and deploying AI models. Windows support in AI libraries, if it exists, is typically lower priority. Linux’s open-source code base has allowed it to stay at the forefront of high-performance computing and edge computing. Additionally, it was the first and is currently the only operating system to support the features necessary for container tools like Docker.
- Windows: Windows is the most common desktop platform, and many users want to develop, deploy, and visualize results on Windows systems. Web-based tools like Jupyter Notebook and Google Colab have made access to Linux computing easier from Windows. Additionally, Windows has begun supporting a Linux compatibility layer called WSL, which has recently been able to do GPU computing. These all still depend on a Linux computing environment but are becoming more accessible from Windows systems.
- Interactive Code Notebooks: Interactive code notebooks like Google Colab and Jupyter Notebook are interactive cell-based approaches to developing code. They allow easily modifying “cells” of code and executing them without restarting the entire process. This means length sections of code, like training or data preparation, can be run once while evaluation or other parts of the code are being developed. These have become popular in the data analysis space because of their ease of use and integration with visualization in a web-based frontend.
Visualization and Analytics Software
Visualization is a very important part of the AI process. This is particularly relevant for data understanding, model evaluation, and performance measures. Visualization can play a role in all sections of an AI pipeline. Data visualization is widely used to study and understand the quality of the data even before any ML processes begin. Data visualization of statistical measures, clustering of data, and pattern analysis of data and features are helpful. The most prominent use of data visualization is in the analysis and summarization of results. Several programming environments and solution systems provide tools for
pattern analysis and data quality assessment. Solutions like Power BI and Tableau provide interactive data visualization tools that can be standalone, web-based, and collaborative. Figure 28 shows an example of a dashboard that summarizes multimodal data in different attribute-based analyses, including map data. This integration and visualization provide an understanding of the solution across all levels of user (developer, user, management). In this section, we provide brief descriptions of some of these tools.
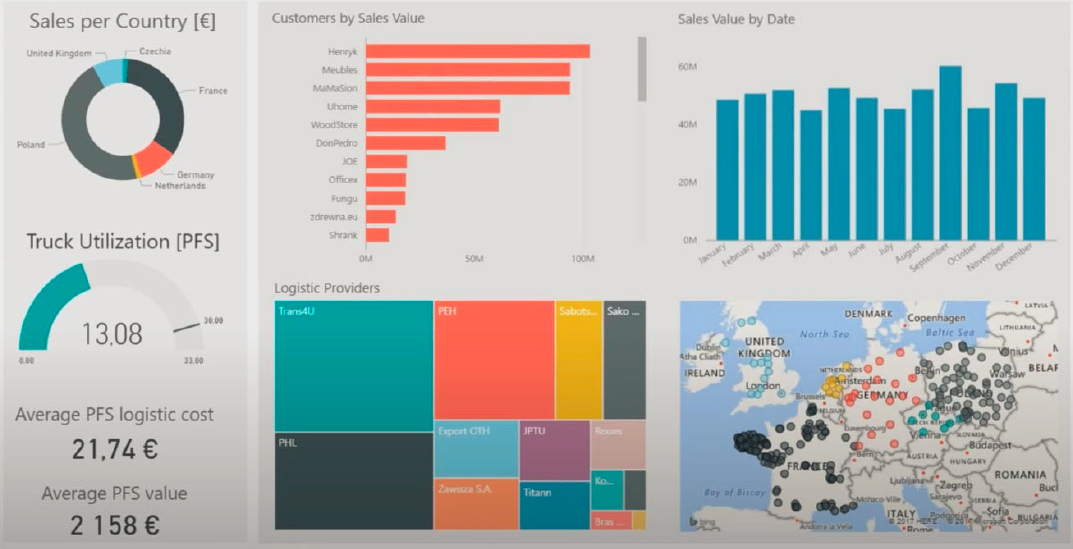
- Power BI: Power BI is a business analytics solution that can visualize data and share perceptions. It can process data from multiple sources and convert them into dashboards and business intelligence reports. Power BI consists of interactive UI/UX features that can make ideas visually appealing. Power BI facilitates real-time stream analytics. It has capability to fetch data from multiple sensors and social media sources to have access to real-time analytics, which aids in making quick business decisions.
- Tableau: Tableau is a data visualization tool utilized for data analytics and business intelligence. Some of the features include a dashboard, sharing and collaboration, advanced visualizations, licensing views, and real-time analysis. It has the capability to pull data from any platform. Tableau can extract data from databases such as Excel, PDF, Oracle, or web pages.
- Plotly: Plotly is a web-based interactive data visualization framework. Plotly visualization can be built with minimal code and no web development knowledge. It uses code patterns similar to other data plotting and visualization frameworks but makes it easy to add interactivity into those visualizations. These include animations, tool tips, interactive elements, and form elements that automatically update visualizations. Plotly can help build dashboards and reports for exploring data.
-
Python libraries
- Matplotlib: Matplotlib is a comprehensive library for creating static, animated, and interactive visualizations in Python. It is an open-source library that can draw high-definition graphics such as histograms, pie charts, scatter plots, etc.
- Seaborn: Seaborn is an advanced visualization Python library based on Matplotlib. It provides reasonable choices for plot style and color defaults. Seaborn should be considered a complement to Matplotlib, not a replacement. At the same time, it is compatible with data structures of NumPy and Pandas and statistical models such as SciPy. Mastering Seaborn can help users observe data and charts more efficiently and understand them more deeply.
- Python Imaging Library (PIL): PIL is already the de facto image processing standard library for the Python platform. PIL is powerful, but the API is easy to use. Since PIL only supports Python 2.7 and is not fully functional so a group of volunteers created a compatible version based on PIL, named Pillow, which supports the latest Python 3 and adds many new features. Therefore, users can install and use Pillow directly.
- SciPy/Numpy: SciPy is a collection of scientific computing libraries that include linear algebra, signal processing, and optimization algorithms. It is built on top of the Numpy library, which allows Python to use array manipulation code written in C so that it is space and time efficient while maintaining the ease of use of Python. Most AI and ML code in Python depends on Numpy or SciPy.
- MATLAB toolbox: MATLAB is an easy-to-use environment that combines programming, computation, and visualization. The built-in graphics make it easy to visualize the two-, three-, and four-dimensional data and gain insights from them. MATLAB includes high-level functions for customizing graphics, image processing, image filtering and segmentation, and animations. The graphs from the vectors and matrices can be made with GUI plotting tools interactively or via command interface by entering graphic commands. It contains several scalar and vector volume visualization techniques for exploring volumes with slice planes, connecting equal values with isosurfaces and isocaps, displaying streamlines, stream ribbons, and stream tubes to illustrate the flow direction, creating stream particle animations, and showing cone plots to visualize vector fields. The toolbox contains other visualization techniques, including slicing, color mapping, contouring, and oriented glyphs.
- R packages: Shiny is an R-based package that helps to generate interactive data visualizations, including web-based services. These systems use the backend of the R programming language and can integrate results generated from other data analytics and ML toolboxes. This package is free and can be integrated with R-studio. This is a useful tool for data scientists who know the programming language of R.
- ArcGIS (geospatial tools): ArcGIS is a geospatial interactive toolbox that helps to visualize results on a geographic location-based platform. Metadata and other modalities can be brought into the system, and their patterns can be analyzed. ArcGIS provides additional tools for finding patterns in the data, three-dimensional GIS capabilities, analysis of remote sensing data, and a collaborative platform. ArcGIS can also communicate with other data visualization platforms, including Microsoft Power BI. Some of the map-related attributes can also be generated through other software tools like Google Map API, Google Earth, QGIS, and OpenStreetMap.
Data Annotation Tools
Data annotation is a process of labeling data such as text, image, video, or time series data so that ML systems can understand the data, learn to recognize them, and predict them. The annotation process allows ML to evolve quickly and produce useful research data points. Several data annotation tools are available in the market; some are commercially available for lease and purchase, and others are open-source and freeware. The critical elements related to annotation tools are listed in Figure 29.
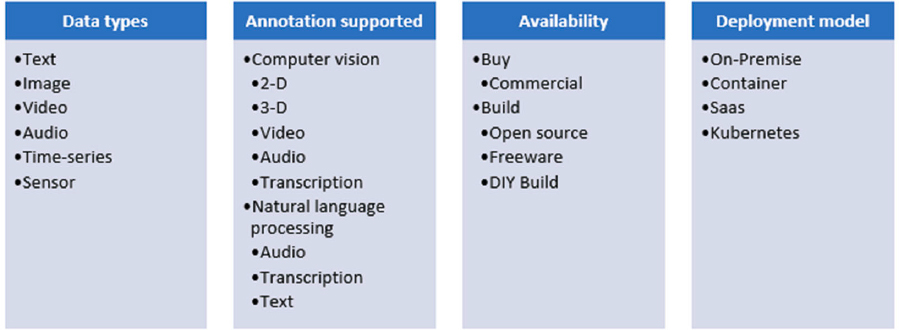
The critical features to consider for choosing the right annotation tool are as follows:
-
Data set management
- Ability to import and export a high volume of data
- Support various file formats
- Data processing features such as searching, filtering, sorting, cloning, and merging data sets
- Support data storage capabilities for local, network, and cloud storage
-
Annotation methods
- Selecting tools based on the specific type of labeling depending on the data type
- Auto-labeling using AI to assist human labelers or fully automated labeling without human touch
-
Data quality control and Workforce management
- Real-time feedback and initiating issues tracking during annotation for managing the quality control and verification process of data
- Capability to assign tasks to the workforce
- Monitoring worker performance using productivity analytics by measuring time spent on the assigned tasks
-
Security
- Ability to protect sensitive protected personal information (PPI) or intellectual property (IP)
- Ability to access the data securely using a VPN
- Ability to maintain various regulatory compliance requirements, such as the Health Insurance Portability and Accountability Act (HIPAA), System and Organization Controls (SOC) 1 and 2, Payment Card Industry Data Security Standard (PCI DSS), or Statement on Standards for Attestation Engagements no. 16 (SSAE 16) regulations
-
Build vs. Buy
- Easy to start and continuous third-party support
- Level of controllability end to end for the workflow of the annotation process
- Funding resources to support or avoid upfront development and ongoing expenses
- Depending on the growth phases of the organization, such as start, scale, and sustain
Figure 30 provides a list of commercially available data annotation tools that are a good choice if the organization is at the growth or enterprise level.

The open-source data annotation tools provide the freedom to modify the source code and tailor it to specific needs. These tools can provide more control over features and integration at the expense of development and operating costs. On the other hand, these tools may have a poor workflow, work management, and security. For AV applications, open-source tools allow tuning annotation models to improve accuracy by
customizing the accuracy thresholds and security features. Figure 31 provides a snapshot of the available open-source data annotation tools.

Computer Vision Annotation Tool
A current trend in processing data for AI learning is the use of crowdsourced data annotation services. Popular services include Amazon Mechanical Turk, Google Cloud AI Platform Data Labeling, and Scale Data Labeling services. These platforms offer researchers the opportunity to engage an on-demand workforce to apply labels and annotations to data sets.
Benefits of crowdsourced data annotation include workforce availability, efficiency in handling micro-tasks, and, in some cases, personnel cost reduction. Negatives of using crowdsourcing for these tasks center around quality control: using a workforce outside of the researcher’s supervision may limit the ability to achieve results that are consistent and repeatable.
An alternative to crowdsourced data annotation is the use of in-house annotation tools. Computer Vision Annotation Tool (CVAT) is free, open-source software developed by Intel. CVAT is distributed under the MIT license and is available through GitHub. The software excels at object detection, image classification, and image segmentation. While there is a web version of CVAT, the locally installed version is needed to process large data sets efficiently.
CVAT is free, in continuous community development, and available for third-party integrations; however, open-source software does not have dedicated customer support and could have performance issues as the source code is revised. There are no official task workflows; rather, users depend on community-created tutorials. The abilities of CVAT continue to grow, but the current state of the software does not have some of the advanced filtering and sorting options found in commercial software packages.
In all data annotation scenarios, training for data quality is paramount. ML predictions rely on accurate labels being supplied. The greater the quality of data annotation, the greater the ability of AI to evolve and perform at maximum precision.
SuperAnnotate12
SuperAnnotate is another image annotation tool that streamlines and automates computer vision workflows for end-to-end image and video annotation. This platform creates larger volumes of high-quality training data sets using tool sets like vector annotations (boxes, polygons, lines, ellipses, key points, and cuboids) and pixel-accurate annotations using a brush. Tools available in the Vector editor annotate the image and videos with high accuracy. Pixel-accurate annotations divide the image into multiple segments in no time in semantic or instance mode, depending on the project requirements. This platform offers various solutions apart from image annotation, such as video annotation, text annotations, project management, data curation, quality management, SDK integration, and annotation services marketplace. The annotation marketplace offers various annotations service support to projects of all sizes across various industries, from AVs and medical imaging to security and surveillance. One of the features of this platform is that it offers an AI solutions team to oversee the annotation pipeline to smooth project delivery. It also supports various file formats through image conversion. This platform aims to provides high security and complies with various regulations: General Data Protection Regulation (GDPR), SOC 2, HIPAA, PCI DSS, International Organization for Standardization/International Electrotechnical Commission (ISO/IEC) 27001, ISO/IEC 27017, ISO/IEC 27018, and ISO 9001. It also offers a free 14-day trial to explore various products and services. Pro and enterprise plans offer the product demo through their website by request.
Supervisely13
Supervisely is a web-based platform running through interactive apps powered by Python to label images, videos, LiDAR three-dimensional sensor fusion, and Digital Imaging and Communications in Medicine (DICOM) volumes for medical multi-slice scans. The image labeling suite contains various usual and “smart” labeling tools based on a collection of class-agnostic neural networks for interactive AI-assisted labeling. It also offers a data transformation language tool and enables three-dimensional point cloud visualizations. Various companies and researchers use this platform for annotation and managing data sets, data, user collaboration and training neural networks, unlimited customization and variability through apps and custom extensions with Python and VueJs, and enterprise-grade solutions with high security and privacy through HIPAA compliance. Limited image, video, and three-dimensional sensor fusion labeling per day is free for the community plan, and a 30-days free trial plan is available for the enterprise plan.
LabelMe14
LabelMe is a free and open online annotation tool for digital image labeling created by the MIT Computer Science and Artificial Intelligence Laboratory. It supports six annotation types: polygon, rectangle, circle, line, point, and line strip. This platform only supports JSON format for importing and exporting the data sets.
___________________
Scale AI15
Scale AI is a data platform that annotates large volumes of the three-dimensional sensor, image, and video data using ML-powered pre-labeling and an automated quality assurance system for the most safety-critical applications. This platform offers data set management, document processing, and AI-assisted data annotations targeted toward data processing for autonomous driving. This platform provides solutions for retail and e-commerce, defense and logistics industries, and various applications such as AVs, robotics, AR/VR, document processing, and content and language processing. It can be used for various computer vision tasks, including object detection and tracking, image classification, text recognition, prediction and planning, audio transcription and categorization, multi-source (combined satellite and other sensor data) mapping, and map updates.
V716
V7 is an automated annotation platform combining data set management, model management, image annotation, video annotation, various labeling services, document processing, and autoML model training. This platform enables images, video, DICOM medical data, microscopy images, PDFs, and three-dimensional volumetric data. The key feature is that auto-annotation speeds up the annotation much faster using AI models without prior training. It is free for educational purposes and offers a pricing quote upon request for startups, business, and pro versions.
Solution-based Systems
Many of the AI-based tools and services described in the previous section have been developed independently and with a specific focus. Because of this, some applications face compatibility problems and need additional coordination between the platforms. For example, CVAT is an image annotations platform, while PyTorch is a Python-based deep learning development framework. Output from CVAT can be used to develop computer vision-based models in PyTorch, but it needs additional coordination for these tools to communicate. Some third-party solution providers are specifically working in this area to create this coordination and offer an end-to-end solution for development, testing, and evaluation.
- Superb-AI17 is a training data platform for computer vision that automates data preparation and labeling, manages images and videos, and finds annotation services. It creates and curates computer vision data sets for companies at all stages. Some of the data operations it provides are auto data curation for test and training data sets, edge case detection to increase the ML model’s scope and range, data debugging with advanced quality assurance automation, and semantic search to explore and visualize data sets with in-house embedding models. It offers a free trial.
- Amazon Web Service (AWS)18 is a large infrastructure-as-a-service (IaaS) provider with comprehensive tools and third-party integrations. AWS offers computing, database, storage, and content delivery services, networking, security, robotics, analytics, and ML. In addition, AWS also offers web and mobile apps, developer tools, management tools, IoT, security, and enterprise apps. It offers a free tier to explore more than 100 products for building on AWS using three types of free offers depending on the product used. AWS provides a short-term free trial for a particular service, 12 months of free service after the initial sign-up date, and specific products have a free tier that does not expire and is available to all AWS customers.
___________________
15 http://labelme.csail.mit.edu/Release3.0/https://scale.com/
- Microsoft Azure AI19 is a portfolio of cloud-based AI services designed for developers and data scientists to build and deploy their AI solutions. It is a significant player in the AI market and offers a range of services, such as anomaly detectors, ML, cognitive search, computer vision, language understanding, genomics health bot, translator, speech-to-text, and speaker recognition. Using Azure Machine Learning and Azure Databricks, the ML model can be quickly built and trained with low-code and no-code tools like automated ML and a drag-and-drop interface, deployed at scale with Azure Kubernetes Service (AKS) and optimized machine inferencing with ONNX Runtime. It supports various operating systems, the latest tools like Jupyter and Visual Studio Code, alongside various open-source frameworks and languages, including Mlflow, Kubeflow, ONNX, PyTorch, TensorFlow, Python, and R. The services are free for the first 12 months after initial sign-up, and more than 40 other services are always free. Pricing for Virtual Machines starts from $13 per month, and SQL database starts from $4.99 per month.
- Oracle AI20 is a family of AI, ML, and AI apps for software as a service (SaaS) with open-source frameworks or prebuilt models for various operations and applications. It offers various pre-trained AI models that can be custom trained with an organization’s data. Oracle Digital Assistant contains a collection of specialized bots that focus on specific tasks, such as tracking inventory, submitting timecards, creating expense reports, and checking sales forecasts. Other AI services offer text analysis at scale, real-time speech recognition, image recognition, anomaly detection, and time-series predictions with explainability. Oracle ML services offer data scientists the ability to build, train, and deploy custom learning models using JupyterLab notebook environments and access hundreds of popular open-source tools and frameworks. Oracle database supports various data operations using SQL, R, Python, REST, AutoML, and no-code interfaces. Data Labeling provides labeled data sets to train AI and ML models more accurately. It also provides Virtual Machines for Data Science, GPU-based environments preconfigured with popular integrated development environments, notebooks, and ML frameworks. Oracle AL offers free AI model training to apps with up to 1,000 or more transactions depending on the service. It also provides accessible model building but charges for computing and storage. Oracle offers a free pricing tier for most AI services and $300 in free credits with a trial account to try additional cloud services. The pricing for economical ML compute and deploy models starts from $0.007 per hour and $0.076 per hour, respectively.
- Vertex AI21, the next generation of the Google Cloud AI platform, combines AutoML and AI with a custom coding platform into a unified API, client library, and user interface. With the AutoML option, data scientists can leverage the train, evaluate, and deploy models and request predictions at scale without written code on image, tabular, text, and video data sets. However, the AI platform allows customers to train the model with custom codes. The main components of the Vertex AI are model training, model deployment for prediction, data labeling, and feature store. Feature store is a fully managed repository where the user can ingest, serve, and share ML feature values within the user’s organization. The Google Cloud console, Cloud Client Libraries, REST API, Jupyter Notebook-based Vertex AI Workbench, Deep Learning VM Images, and Deep Learning Containers are several tools a customer can use to interact with Vertex AI. Cloud-based ML, customer sentiment analysis, spam detection, recommendation systems, and purchase prediction are some of the critical features. It offers a state-of-the-art security system, pricing schemes, and pay-as-you-go pricing based on monthly usage. It offers more than 20 free products, including compute engine
___________________
19 https://azure.microsoft.com/en-us/solutions/ai/
- and cloud storage for all customers, and $300 in free credits to explore various products in Google Cloud.
- H2O AI Cloud22 platform started as an open-source platform based on AutoML. Its stated mission is to democratize AI and accelerate AI results over 10 times faster, to operate AI across organizations and departments with trust and confidence, and to simplify and scale AI with one platform that operates across clouds, on-premises environments, and data sources. H2O claims to provide AI solutions for data users of more than 20,000 global organizations in industries such as financial services, government, healthcare, retail, communication, and insurance. H2O AI Cloud has two deployment options: a Hybrid option to operate in any cloud or on-premises IT environment and a Full Managed option for the easiest way to get started and securely operate the platform. A 14-day free trial option is available.
- IBM Watson23 provides AI tools to help organizations predict future outcomes, automate complex processes, and optimize employees’ time. It is one of the core services of IBM Cloud Pak for Data. Together with IBM Watson Machine Learning and IBM Watson OpenScale, Watson Studio provides tools for finding AI solutions for risk and compliance, return-to-workplace, financial operations, advertising, business automation, customer service, healthcare, IT operations, video streaming, and hosting. IBM Watson has developed prebuilt applications for financial, travel, healthcare, retail, services, security, and supply chain sectors. IBM Cloud Pak for Data can deploy private clouds (inside the firewalls), hybrid clouds, AWS, Microsoft Azure, and Google Cloud. A free trial of IBM Watson Studio on Cloud Pak for Data is available to explore.
- Intel AI24 aims to decrease the time between AI development and deployment at scale using Intel’s portfolio of hardware, software, and partner solutions for the entire data pipeline. It claims to accelerate building and deploying AI applications at scale using Intel Xeon Scalable processors and Intel-optimized AI software. Some features it offers are simplifying AI with acceleration, streamlining development with popular AI models and framework optimization, securing data at the electron level, and developing and running open-source distributions confidently. Intel provides AI products such as Intel AI Analytics Toolkit based on Python accelerated end-to-end data science and ML pipeline, Intel Distribution of OpenVINO Toolkit for deploying high-performance inference applications from devices to the cloud, and BigDL for scaling AI models to big data clusters with thousands of nodes for distributed training or inference. Intel provides software optimization for deep learning frameworks such as TensorFlow, PyTorch, Apache MXNet, and PaddlePaddle and ML frameworks such as Scikit-learn and XGBoost. Intel claims these optimizations deliver orders of magnitude of performance gains over the stock implementation of the same frameworks. Intel is working with various OEMs to accelerate the performance-per-watt, flexibility, scalability, functional safety, and security for automotive-grade advanced driver-assistance system and autonomous driving sensor applications like sensor ingest, preprocessing, and acceleration using reprogrammable field-programmable gate arrays. Intel offers various computer vision products, including Intel Video AI Box, a preprocessing AI appliance that can easily be integrated with existing infrastructure to deliver deep learning and analytics insights. The details of Intel AI’s free trial and pricing have not been listed on the website.
- NVIDIA DRIVE25 is an end-to-end software platform for data ingestion, curation, labeling, training, and validation through simulation for self-driving cars and AVs. It is an open AV
___________________
22 https://h2o.ai/platform/ai-cloud/
24 https://www.intel.com/content/www/us/en/artificial-intelligence/overview.html
- development platform with high-performance computing, imaging, and AI for software developers worldwide. This company aims to develop solutions for the transportation industry with continuous improvement, deployment through over-the-air updates, and delivery at scale. The company states that infrastructure includes the complete data center hardware, software, and workflows for developers to create autonomous driving technology from raw data collection through validation. The NVIDIA DGX system provides computing power for large-scale training and optimization of deep learning. NVIDIA DRIVE Constellation makes physics-based simulations for testing and validating AVs before they are released to the market. The NVIDIA DRIVE AGX platform processes large volumes of sensor data and makes real-time driving decisions for AVs. NVIDIA DRIVE Hyperion is a production-ready AV platform containing NVIDIA Orin-based AI compute with a complete sensor suite. It contains two software suites, DRIVE AV for autonomous driving and DRIVE IX for driver monitoring and visualizations, which can be updated with OTA. The AI driving assistant platforms, NVIDIA DRIVE Concierge and NVIDIA DRIVE Chauffeur, provide various intelligent services to the driver. NVIDIA DRIVE Map is a multimodal mapping platform with four localization layers—camera, LiDAR, radar, and global navigation satellite system—that the company claims to enable the highest levels of autonomy while improving safety. NVIDIA DRIVE has partnered with various car and truck makers, mobility services, high-definition mapping companies, software companies, TIER1 suppliers, sensor companies, and research institutions to integrate GPU technology and AI to leverage deep learning, NLP, and gesture control technologies for autonomous driving. The details of free trials and pricing have not been listed on the website.
- Autoware26 is an open-source software project for autonomous driving built on ROS. It enables commercial deployment of autonomous driving on a scale for various vehicles and applications. It supports perception, planning, and control in a modular architecture with interfaces and APIs. The initial version of Autoware was released in 2015, incrementally adding features and functionality for more complex operational design domains (ODDs) to achieve Level 4 and Level 5 autonomous driving. The previous version of Autoware supports autonomous valet parking, cargo delivery, and autonomous baggage handling vehicles operating in and around airport terminals. In 2022, Robotaxi functionality and Bus on public road support have been introduced in core/universe architecture. Autoware provides an Open AD Kit that contains a reference framework for software-defined vehicles to accelerate the development of optimized hardware and software solutions for autonomous driving. This kit contains cloud-native development pipelines and/or tools, autonomous driving microservices integrated into Autoware OSS, middleware and operating system solutions, and heterogenous compute platforms. The initial release of this kit includes cloud and edge solutions from ADLINK, ARM, AutoCore, AWS, SUSE, and Tier IV.
___________________
AI Data Management
The black box nature of deep learning has introduced many new types of structured and unstructured data into AI algorithm development. Deep learning’s success at learning on data with complex internal relationships and the model’s relative opaqueness means many data modalities store far more information than a human would need to perform the same task. A human can easily recognize a face in a grainy low-light highly compressed image, but deep learning models struggle with noise in the image. In Figure 32, the same model was run on two images. To a human, both images clearly present a face, but the right image is more compressed, and the algorithm fails to identify the face in it. When managing data for AI training and inferencing, it is important to consider tradeoffs in the storage format, the storage system, and the conditions of collection.

Complete data pipelines will rarely rely on only a single type of data. Most will touch several, but the AI component may only deal with one. An important tradeoff is deciding how much data to provide the model and when to use a first principles approach to data fusion. It is possible to feed map and image data into a graph CNN to make predictions about driving conditions; however, most map-based analysis has clear algorithms based on the data, and performance with a non-AI method will be better.
Data Provider
There are many sources of data that state and local transportation agencies may use to create AI data sets. Some of these sources of data may reside within the local, state, or federal data collection systems to improve the efficiency and safety of the U.S. roadway network. However, there are other data providers that are owned by private companies. Below are a sample of data providers transportation agencies might leverage in AI programs.
- Traffic Management Systems: Many municipalities, regional transportation commissions, and states collect vast amount of data via a traffic management system. Traffic management systems often combine data from many other data sources described below. Data in traffic management systems include video data captured via roadway cameras, locations of work zones, traffic congestion, public transportation timing, traffic signals, incident response, and weather. These data are accessible through an agency’s private database.
- Vehicle Telematic Providers: There are many private telematics providers that collect vehicle data via sensors and GPS. Some example telematics data providers include Geotab and Speedgauge.
- Although these data are private, agencies may be able to gain access to the data for a cost. These data include speed, location, and rates of acceleration. Many telematics providers capture video data directly from the vehicle.
- Police Crash Reporting: Every state maintains a database of police-reported crashes. These data provide insight into location, severity, and contributing factors of traffic incidents. These data are publicly available.
- Federal Data: The U.S. DOT maintains several data sets related transportation safety and efficacy. Some examples include the Fatality Analysis Reporting System, Crash Investigation Sampling System, Crash Report Sampling System, Motor Carrier Management Information System, and National Performance Management Research Data Set. These data are publicly available.
- Road Weather Information Systems: State and local municipalities often use road weather information systems to measure and track current and future atmospheric conditions to assess inclement weather and implications for visibility and pavement conditions. These data are available through an agency’s private database.
- Hospital and Emergency Medical Service Records: Data included in medical and emergency medical services databases may be available to assess roadway safety and factors that contribute to traffic incidents. These data may be available by working with the emergency medical services system.
Data Modality
Vision Data
The most recognizable vision data are images and videos, but this category also includes other forms of vision data like LiDAR and multimodal cameras. The primary concerns with these data are compression, preprocessing, and visualization. These are all potentially very large data sets, with prominent data sets exceeding hundreds of terabytes in size. It is impossible to store large quantities uncompressed and, in the case of LiDAR data, even process them uncompressed.
Compression algorithms are not optimized for computer vision tasks, but for human perception. They remove high-frequency elements of the images and preserve color differences that humans perceive well. Because of the opaqueness of AI models, it is difficult to know what compression optimized for AI models would look like. For LiDAR, where machine tasks are more common than human tasks, state-of-the-art compression performs computer vision tasks to identify things like the ground plane and objects in order to use different compression algorithms for each. In general, the best strategy is to preserve as much of the image as possible, well beyond what a human would need to perform the task.
Compression requirements make edge computing reproducibility difficult. On-vehicle algorithms have access to raw video and LiDAR data, but it is impossible to store that uncompressed to reproduce results from the vehicle post hoc. In such a safety critical environment, reproducibility is key, and this area of research is still rapidly developing. In a similar vein, visualizing the results of computer vision tasks means storing annotated images or videos. For video or image data, that doubles the storage requirement. For LiDAR data, video visualization is still large, though it is smaller than the original data. Interactive visualizations are popular for LiDAR because of the three-dimensional nature, but it requires significant computing time to render them.
Preprocessing vision data is best done on the fly, as it is computationally much cheaper than the model processing but can be difficult to tune correctly. Many models require different normalization conditions or perform better in a different color space than where the data are stored. Noise reduction and luminosity
changes can also help improve the performance of a model. On the training side, processes like random cropping and flipping can increase the diversity of the training set and improve generalizability.
Text Data
Text data sources are highly variable and include optical character recognition forms, social media data, content submitted via online forms, and published media. Often meaning is highly context dependent; a newspaper article describing a bad experience will be expressed using very different language than an angry tweet. Because of that, metadata are some of the most important parts of working with text data. Text data sets are relatively small, but it is common for these data sets to be multimodal, or at least easily connected to other data modes like audio data. Scanned forms have images, online posts have an important time dimension, and reviews or complaints have important geographic information. In transportation a variety of systems use text data. This includes document management, document summarization (e.g., summary of police accident report), developing recommendation systems, chatbot systems for customer supports, and automatic transcription of key records to mention a few.
Map Data
Geographical information system (GIS) and map data have a huge ecosystem of data sources and tools, and the data management problems largely exist around sourcing and accessing high-quality data. APIs like HERE and Google Maps Platform provide rich, accurate, and up-to-date data on demand, extending beyond traditional geospatial metadata to include images and reviews of points of interest based on location. A variety of tools, both open source and commercial, help transform, manage, and store geospatial data, while interactive and visualization work is often done with tools like ArcGIS and QGIS, and large-scale programmatic processing during AI development and deployment may leverage functions in spatially enabled databases, like PostGIS. As the transportation system is a geospatial system, many transportation problems benefits from the geospatial information of systems and dynamics. This may include the traffic patterns, traffic congestion, asset localization etc.
Time Series Data
Time series data management depends significantly on how the data are being utilized. Many applications build AI models with the intention of deploying them on live data, receiving a stream of time series data, and making high-speed decisions based on those results. These models use stream processing solutions like Apache Flink. Processing done post hoc is typically iterative, and there is an expansive software ecosystem around time series processing and data storage. Ultimately, most time series analyses start with a CSV file, but as the data sets grow more quickly, storage mediums like Parquet or Arrow are needed. Massive data sets or those accessed by many people outside of the hosting organization may leverage databases or APIs to provide data. Ideally, any data sampled over time in transportation research can be reflected as time series data. Therefore, many of the data collected, accessed, and sampled by transportation agencies fall under this category.
Data Sharing
Data are often thought of as collections of data points or representations of measurements, but in the AI space where models are complex, difficult to create, and can be enhanced independently of any code base that leverages them, the models are another data point. This is especially poignant when it comes to data sharing. Practices vary widely among AI developers on sharing models and code. Many in research freely share code and models, where others, especially in sensitive fields like deep fakes, may share only the code. Industry is much less likely to share models or even details about the performance of the model compared
to the state of the art. AI-as-a-service providers rarely share details about how the models were created or their performance characteristics.
This limited sharing leads to problems with reproducibility. Validating models or algorithms without access to trained model parameters is very difficult. Some models train using controlled unclassified information, personally identifiable information, or proprietary data and can share the model, but not the training data.
AI competitions are popular among the research community and publish large training data sets. These are standard starting points for building algorithms and can be augmented with additional sensitive data to get application specific.
Large-scale Data Collection, Storage, and Management
Recent methods in AI excel at making predictions on data that defy first principles analysis. These are large data with complex internal relationships. AI algorithms are opaque, and when developing and storing data sets it is best to provide as much clean data as possible, relying on the learning in the algorithm to distinguish between useful and irrelevant information. Furthermore, the AI training itself requires large data sets to learn relationships in the first place. The propensity toward large data sets and complete data points means storage requirements are significant.
Data Collection
Large-scale data collection takes significant planning, coordination, and continuous validation. Sufficient storage is required prior to data collection, so being able to predict data collection sizes and the resources required to ingest the data is essential to a successful effort. Accurate prediction requires expertise, experience, and familiarity with the objectives of the effort to make trade-off decisions. For large efforts, recollection is impossible, so it is best to start with a smaller pilot collection or build in regular validation points to the collection plan.
Data Extract, Transform, Load
Large, structured data sources require an extract, transform, and load (ETL) process. This processes the collected data from the original data sources and extracts them for data cleaning and restructuring. This transformation step is critical to data cleaning, as this is where most of the critical metadata to make data quality determinations exist. AI algorithm development is so dependent on the data that this step can often determine success or failure of an effort. The data are then loaded into a data system like a database or standardized file structure for annotation and processing. The size of the data set has little effect on the complexity of the ETL process as it is almost entirely dependent on the data quality and the complexity of the ingested data.
Data Storage
The best storage solution will cater to the data’s size, the project’s performance requirements, and the algorithm’s access patterns. File and object are the standard mechanisms for storing structured or unstructured data. Directories full of CSV files or images organized by class or date work well for small-scale processes with less than 50,000 files. For a large number of files, object storage like Amazon Simple Storage Service (S3) will outperform file storage. Cost on data storage is driven by the total size and the desired performance. Using flash storage or high-performance cloud storage classes may improve the processing speed, but they will have no impact if computational resources are the reason for any delays. Piloting both the training and inferencing components of any AI pipeline is critical for guidance on choosing
the correct storage system. This can be done with naïve approaches first to understand the workload pattern and cost-benefit tradeoffs.
Some data, especially telemetry and GIS, benefit from indexing the data in a database. Tools to do this include TimescaleDB, PostGIS, tile servers, and traditional relational database management systems (RDMS). The advantage of using a structured data store like a database is greatly increasing data access speeds without requiring faster performing storage. These excel when the data store can perform some calculation to return less data than the entire data set. PostGIS, for example, can be queried to return all road segments with a certain curvature range in a set of cities much faster than checking the data with an algorithm. When working with metadata-rich data sets, databases provide the greatest value.
Metadata
Metadata are critical to creating AI data sets and validating models. They include information from data collection details to summary information about the contents. Sometimes the metadata are part of the data organization. For example, ImageNet stores image files in numbered directories, each of which corresponds to the class of object in the image. Time series data may store all the metadata along with the data, such as a row in a table containing columns for a temperature sensor, sensor errors, location, and time. Sophisticated or highly complex data sets may rely on one or more databases to track all the data, information, and results. Object storage systems like S3 can tag stored objects with metadata and later query objects by those metadata tags. This integrates the external metadata store with the data itself.
Performance
Performance requirements of large storage are entirely dependent on the application. The processing of large video data sets will often be bottlenecked by the available GPU resources, unless leveraging cloud resources to scale very widely. Data that have relatively low compute costs, like time series data, will strain the limits of all but the fastest storage. Data access will become a constraining factor of any system that exceeds a few terabytes as specialized systems are needed to store data of that size. Cloud services offer several significant advantages in ease of use and manageability but are more costly over time than dedicated storage systems.
Large1-scale Data Management
Managing large data sets at scale means certain operations are difficult or impractical and require a specific, intentional data management plan. Transferring hundreds of terabytes over the internet to a new site is all but impossible without costly dedicated high-speed links into a major internet exchange or one of the research networks like Internet2 or ESNet. Changing file permissions on more than a million files can take days or weeks. These need to be planned and funded for the lifetime of the data set. This requires a very forward-thinking view to support the data use.
Large-scale Data Processing on GPU/Edge/Cloud
Computing
Computing resources are important to consider when deciding what tasks are required, the speed and efficiency needed for those tasks, and the total cost of operation. CPUs are the core of every laptop/desktop computer. Designed to perform a wide variety of tasks, the usefulness of these chips is limited in the field of ML and AI. CPUs are suitable for some annotation and data inference tasks and can have their utility extended through parallel processing and clustering.
GPUs are specialized components that excel in advanced mathematical computations. GPUs, originally used for gaming systems, have evolved to become a cornerstone of ML. Unlike CPUs, which have steadily but slowly improved over time, GPU performance rapidly improves with each generation. These performance gains make new AI algorithms with more parameters viable and shorten the lifetime of GPUs. Depending on the GPU and when it was purchased in the product release cycle, they may not last more than 5 years before they are functionally obsolete. To extend beyond the limits of what a single machine can process, computing clusters orchestrate processing across a large set of systems. These require a scheduler to manage sharing of the cluster and automate starting and stopping processing. To have rapid, easily scalable computing services, several companies now offer cloud-based resources. Some companies include NVIDIA, AWS, Intel.ai, and Oracle.
Edge Computing
Edge computing, sometimes called IoT, moves computation away from central resources onto the devices doing data collection. This allows massive data reduction by transferring and storing only the results of AI algorithms. Sometimes this is done as a multi-stage pipeline where an algorithm is used to identify data of interest, or it reduces the data only partially, depending on a central resource to complete processing. It can solve many of the problems of large-scale data collection, but errors in the edge computing algorithm mean lost data or bad results, with no option of correction.
Cloud Computing
Cloud computing converts capital expenditures into operational expenditures. It amortizes the cost of maintaining large-scale systems relying on economies of scale to maximize the efficiency of their operation. To potential customers, this means large compute and storage resources are readily accessible with virtually no startup cost. In practice, fully utilized on-premises systems with existing support infrastructure become more cost effective in a matter of months. Still, for small use cases, during the startup phase of a major project, and for “bursty” systems whose maximum performance requirements far exceed their means, cloud computing is a smart tactical option.
Cost and Benefit
Several software tools are currently available to researchers. Each of them provides different sets of benefits to its users. The academic AI community has been very open about its work, including final software tools available through open-source platforms like GitHub for anyone with proper domain knowledge to use. In this section, we discuss the benefit of each such system and the sets of tools we described in the previous sections.
AI Software Tools
In this section, we discuss tool sets that provide platforms either for end-to-end solutions or to help a user customize their solutions. Many of these systems are cloud-based solutions. We have compared them in terms of their required cost, usability, and overall security. As discussed in Section 0, data security is an important component of the overall system. There are many protocols on data security. Depending on the sensitivity of the data, stakeholders should choose the tool sets that are most appropriate. A comparative analysis is shown in Table 17.
Table 17. A cost-benefit analysis of different AI-based tool sets available for use.
| Tool | Cost | Free trial | Security | Resources |
|---|---|---|---|---|
| Superb-AI | High | Available |
|
Data sets, Documents, Version History, Datacast, White papers, Blog Academy and Community support |
| AWS | High | Available |
|
Vast database of guides, API references, tutorials, projects, SDKs, and toolkits are available Training and certification Video tutorial for developers Amazon Builders’ Library |
| Azure AI | Moderate | Available |
|
Offers various digital media, training and certifications, analyst reports, white papers, e-books, videos Developer resources, documentation, and Quick start templates Provides community supports to develops and students |
| Oracle AI | Moderate | Available |
|
Documentation, cloud services, training, and |
| Tool | Cost | Free trial | Security | Resources |
|---|---|---|---|---|
|
GitHub for developers and students Resources in Python, JS, Java, .NET, php, Terraform, Apex, SDKs, GraalVM Various solutions for enterprise apps, ML/AI, web apps, containers, analytics, serverless, computing, etc. |
|||
| Vertex AI | Low | Available |
|
Available support from Google cloud and community Available various code samples Detailed console, libraries, and guide and references available |
| H2O AI | Open source | Available |
|
Data sets, Documents, Version History, Datacast, White papers, Blogs Various open-source algorithms Enterprise support |
| IBM Watson | Low | Available |
|
Cloud environment for public, private, or hybrid cloud Developer tools and documentation, technical paper, and digital media SDKs on GitHub Watson Assistant AI consulting services |
| Tool | Cost | Free trial | Security | Resources |
|---|---|---|---|---|
|
||||
| Intel AI | Not listed | Not listed |
|
Various ready-to-deploy AI software, hardware, and solutions. Digital media, technology sandbox, training portal for registered members |
| NVIDIA DRIVE | Not listed | Not listed |
|
Offers Deep Learning Institute (DLI) courses, drive videos, webinars, GPU Technology Conferences, Drive documentation NVIDIA Drive download available for members for the Developer Program |
| Autoware | Open source | - | No information is given |
|
Note. Some of these are commercial systems.
Big Data Management
In this section, we discuss the cost and benefit analysis of big data management and explore two options: if the DOTs want to collect and store data on their own premises or use cloud-based storage facilities. Storage cost has been significantly lower in recent years. In the meantime, the demand for storage requirements has increased mainly due to the introduction of high-quality sensors like high-definition cameras and LiDAR. In many cases, the data can be stored in a local facility through a large-scale storage system. The main advantage of such a system is that the collected data are readily available to the researchers over the local area network. Also, for the physical storage facility, the security of data is higher, given that proper security protocol is taken. However, these kinds of systems need experts in the IT and database management systems who can continually monitor the health and access of the system. On the other hand, a cloud-based service does not need experts for maintenance. The workload of an IT
professional is comparatively lower. However, the team needs to upload all the data to the cloud, which may need very high-speed internet service. If the data volume is too large, then the internet speed may hinder the process. Also, these systems may be costly in terms of keeping the data for a long period of time. However, if the team decides to use cloud-based computing resources, then this kind of cloud-based system may be easy to integrate. The comparative results are shown in Table 18.
Table 18. Cost-benefit analysis for big data management.
| Tool | Infrastructure/maintenance ↓ | Recurring Cost ↓ | Security ↑ | Knowledge for data management ↓ | Speed ↑ |
|---|---|---|---|---|---|
| Physical Storage | High | low | high | High | high |
| Cloud-based storage | low | Very high | low | low | low |
Note. The ↓ signifies lower value is better. The ↑ means higher value is better
Computing
In this section, we discuss options related to high-performance computing. Most recent AI-based solutions depend on GPU-based architecture. Although some of the algorithms can still run on CPU-based systems, their inference speed may also be limited by the CPU environment. Nevertheless, as in the last section, we mainly concentrate on on-premises computation versus cloud-based computation. GPUs are costly to buy, and processing large-scale data (in the range of terabytes) requires a very large-scale GPU computing resource. This may significantly impact the initial infrastructure cost. Also, this system needs dedicated IT personnel for managing, scheduling, and maintaining these GPUs. Finally, we have seen historically that, with accelerated research in high-performance computing, the GPU half-life is becoming shorter as new high-performing GPUs are available on the market. Despite all these limitations, having on-premises computational resources significantly reduces the recurring computational cost. It also reduces costs related to cloud-based storage and upload of large-scale data. The cloud-based systems can provide very large-scale computing resources, but their recurring cost and data storage costs are high. Therefore, the decision should be dependent on the specific application and GPU/CPU hours needed for the task. A comparative analysis is shown in Table 19.
Table 19. Cost-benefit analysis of computing resources for AI applications.
| Tools | Infrastructure/maintenance ↓ | Recurring cost ↓ | Security ↑ | Personnel knowledge base ↓ | Speed ↑ |
|---|---|---|---|---|---|
| On-premises CPU | medium | low | high | high | low |
| On-premises GPU | high | low | high | high | high |
| Cloud-based CPU | low | high | medium | low | medium |
| Cloud-based GPU | low | high | medium | low | high |
Note. The ↓ signifies lower value is better. The ↑ means higher value is better.
Outsourcing, Crowdsourcing, Knowledge Building
AI solutions can be applied in multiple ways. Some can be applied by outsourcing tasks to third-party specialized vendors (camera-based solutions). Others can be done through crowdsourcing (traffic data collection). A part of the task can also be done autonomously. Each option has pros and cons, as shown in Sections 0 to 0; in most cases, when someone needs to perform a task autonomously, they need a proper infrastructure and personnel who can operate and manage the system. In AI-based systems, often these are people who have a background in computer science, software engineering, or information technology. Also, they must be aware of any security threats for the system. However, once these requirements are met, the
recurring costs of the systems become lower. On the other hand, many of the cloud-based services offer ready-to-go platforms that require very low maintenance and may only need personnel with domain knowledge in AI. The main drawback in such systems is the recurring cost of the services, as they are often pay-per-use. While these two examples need experts in AI on the team in some capacity, I other possible solution is outsourcing tasks to a third-party vendor. Many enterprises are now developing capabilities to provide end-to-end solutions that include data collection, annotations, and analysis. In such scenarios, the DOTs need to acquire domain knowledge to understand the various components of the tasks and the main evaluation criteria in order to manage the project. We believe that a DOT should take a systematic approach to decide which option is better for the given problem, cost budget, and time budget.
Conclusion
AI stands to benefit a variety of transportation-related applications for DOTs. The scope of AI is enormous and includes road transport, safety, infrastructure management, and energy efficiency. AI has the potential to make traffic more efficient, ease traffic congestion, free up time spent driving, make parking easier, and encourage car- and ridesharing. As AI helps to keep road traffic flowing, it can also reduce fuel consumption caused by vehicles idling when stationary and improve air quality and urban planning (Niestadt et al., 2019). AI can be applied to use advanced sensors effectively for targeted applications. Automation in general can bring consistency, uniformity, and remove human bias. While AI may require an initial investment, it has the potential to ultimately reduce cost. Lastly, the application of AI may significantly reduce processing time for tasks and jobs that are repetitive and require significant manual labor. In summary, the implementation of AI by DOTs can not only improve performance and speed of operation, but it can also reduce the cost of operation and minimize bias.
Software and other tools are major components of AI development and application. One of the key factors in the AI revolution is the widespread availability of software platforms for seamless deployment and experimentation. Numerous application platforms have been developed by the AI industry, including Google, Facebook, DeepMind, and MATLAB, along with practitioners and developers from industry and academia. These platforms include Scikit-learn, OpenCV, NLTK, MATLAB image processing toolbox, PyTorch, Keras, TensorFlow, and MXNet. These tools, which are developed in diverse language platforms like Python, R, Java, and MATLAB, are widely used to implement traditional ML techniques, AI-based applications, and advanced DNN models. These models can efficiently communicate with GPU clusters and high-speed storage facilities. In recent years, cloud-based services have emerged to provide these application tools along with storage and computational resources. Such cloud-based services are now provided by Amazon (Amazon AWS), Google (Google Colab), Microsoft (Azure), and NVIDIA, among others.
In this report, we have provided a comprehensive review of different AI tools. We have first provided a comprehensive understanding of the overall data processing pipeline needed for any AI-based development and deployment. Then we discussed each key components of the process, including software tools, data management, and data processing. For the software-based tools, we have discussed all possible tool sets that may be required for advanced data analytics, including statistical analysis, traditional ML, and advanced ML such as DNN. We believe that these sets of tools and their comparative study will provide a comprehensive understanding to DOTs on the promises and challenges they may expect while implementing any AI-based systems. These tools will also help DOTs to understand the role of AI tools in any upcoming projects and the components needed for them. We believe that this document will also help them to understand the infrastructure and personnel needed to execute such data-driven AI tasks.
References
Antdata. 2021. Power BI Reporting Implementation–n - Power BI Reports with Antdata Developers and Consultants. https://antdata.eu/power_bi_implementation.html
Chen, T., M. Li, Y. Li, M. Lin, N. Wang, M. Wang, T. Xiao, B. Xu, C. Zhang, and Z. Zhang. 2015. MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems. In Neural Information Processing Systems, Workshop on Machine Learning Systems. https://github.com/dmlc/web-data/raw/master/mxnet/paper/mxnet-learningsys.pdf
CloudFactory. n.d. Data Annotation Tools for Machine Learning (Evolving Guide): Choosing the Best Data Annotation Tool for Your Project. https://www.cloudfactory.com/data-annotation-toolguide#:~:text=A%20data%20annotation%20tool%20is,training%20data%20for%20machine%20learning
Hinton, G. E., N. Srivastava, A. Krizhevsky, I. Sutskever, and R. R. Salakhutdinov. 2012. “Improving Neural Networks by Preventing Co-adaptation of Feature Detectors.” arXiv preprint arXiv:1207.0580.
Jia, Y., E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. 2014. “Caffe: Convolutional Architecture for Fast Feature Embedding.” Proceedings of the 22nd ACM International Conference on Multimedia, pp. 675-678.
McCarthy, J. (2004). What is Artificial Intelligence? http://www-formal.stanford.edu/jmc/whatisai.pdf
Niestadt, M., A. Debyser, D. Scordamaglia, and M. Pape. 2019. Artificial Intelligence in Transport: Current and Future Developments, Opportunities and Challenges [Briefing]. European Parliamentary Research Service. https://www.europarl.europa.eu/RegData/etudes/BRIE/2019/635609/EPRS_BRI(2019)635609_EN.pdf
SAE International. 2021. “SAE Levels of Driving Automation™ Refined for Clarity and International Audience.” https://www.sae.org/blog/sae-j3016-update
Volet, Y. 2018. CRISP-DM-01. https://emba.epfl.ch/2018/04/10/steps-successful-machine-learningproject/crisp-dm-01/
Appendix B1
CNNs
CNN is a powerful class of neural networks designed for processing image data. Models based on CNN architectures have dominated the field of computer vision. All academic competitions and commercial applications related to image recognition, object detection, or semantic segmentation today are based on this approach. CNNs require fewer parameters than fully connected architectures, and convolutions are also easily parallelized with GPUs. Therefore, CNNs can sample and calculate efficiently to obtain an accurate model. Over time, practitioners have increasingly used CNNs even on one-dimensional sequence-structured tasks such as audio, text, and time series analysis. With some clever tweaks, CNNs also work in graph-structured data and recommender systems.
Typically, CNNs can be construed by stacking some types of layers: convolutional layers, pooling layers, fully connected layers, and residual blocks.
Convolutional layer: The convolutional layers in a CNN extract features by convolving the input images with kernels. A kernel is a small matrix that is also called a convolution matrix or convolution mask. It slides over an input image and does dot production with it at each spatial location. The output of the production is called convolution features. The number of channels of the kernel must be the same as the input image, so a three-channel RGB input image will be convolved by a three-channel kernel. Convolution features will be transferred to activation function to add non-linearity.
Pooling layer: A pooling layer is always used to reduce the size of the input data following a convolutional layer. It compresses the data and reduces the number of features to speed up the calculation and prevent overfitting.
Fully connected layer: A fully connected layer is the end of a CNN. It combines the features extracted earlier and passed them to a classifier to do final prediction.
Residual Block: A residual block is a skip connection between the layers to facilitate better learning and reduce degradation in the learning process.
Recurrent Neural Network
A recurrent neural network (RNN) is improved from CNNs that specialized in processing sequences. Unlike the traditional neural networks, outputs from the hidden layers in RNNs will be passed to the next moment and involved in training, so the network will retain historical information from the previous moments. RNNs have natural advantages in sequence modeling and have good performance in many fields, including NLP and computer vision.
Auto-encoder
An auto-encoder is a neural network trained in unsupervised learning. Its basic idea is to directly use one or more layers of a traditional neural network to map the input data and obtain extracted vectors as features. It first learns an encoded performance of the input data and generates these input data as closely as possible with the encoded performance. The main uses of auto-encoders are dimensionality reduction, denoising, and image generation.





































