Reliability and Quality of Service Evaluation Methods for Rural Highways: A Guide (2024)
Chapter: 3 Automobile Travel Time Reliability

CHAPTER 3
Automobile Travel Time Reliability
3.1 Introduction
Before the HCM 6th edition, predicting travel time reliability (TTR) would typically involve microsimulation with extensive new data collection and calibration of the simulation model. With methodologies in HCM7 Chapter 11, Freeway Facilities, and Chapter 17, Urban Streets, it is now possible to predict the reliability effects of infrastructure investments without developing a microsimulation model (TRB 2022).
The HCM7 covers various performance measures that can be obtained from the distribution of travel times along a facility and in some cases, the vehicular volumes matching travel time observations. Some of the measures discussed in the HCM7 (TRB 2022) are as follows:
- 95th percentile TTI (also known as Planning Time Index or PTI): the ratio of 95th percentile travel time to free-flow travel time.
- 50th percentile TTI: the ratio of median (50th percentile) travel time to free-flow travel time.
- Level of Travel Time Reliability (LOTTR) (80th percentile travel time divided by 50th percentile travel time).
- Reliability Rating: how often the facility performs satisfactorily. Often defined as the fraction of facility VMT operating below a TTI of 1.33.
- Failure and On-Time Measures (%).
- Misery Index: average of the worst 5% TTIs.
- Semi-standard Deviation: standard deviation from TTI = 1.
- Standard Deviation.
- %VMT at TTI > 2.
Figure 3.1 illustrates how these measures may be obtained from a distribution of travel times.
In addition to the guidance on measuring past reliability performance, the HCM7 provides methods to evaluate changes in reliability that may result from changes to the facility (e.g., the addition of a lane). The HCM7 method is heavily reliant on generating hundreds of analysis scenarios with differing demand, weather, work zones, and incident conditions. The core HCM7 procedures are then applied to those scenarios to obtain distributions of various performance measures, including those described. HCM7 Exhibit 11-7 Freeway Reliability Methodology Framework provides an overview of this approach, which is conceptually similar to that of arterials (TRB 2022).
For agencies with limited data, the HCM7 provides defaults that can serve as a starting point for predicting reliability:
- HCM7 Exhibit 11-20 has default capacity adjustment factors by weather condition.
- HCM7 Exhibit 11-21 has default speed adjustment factors by weather condition.
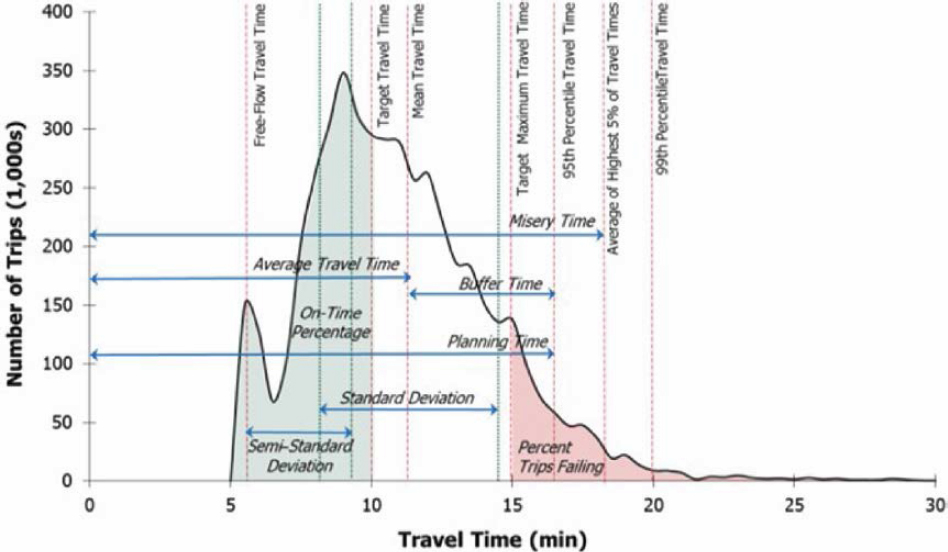
Figure 3.1. Derivation of time-based reliability performance measures from the travel time distribution.
- Volume 4 Technical Reference Library contains default weather data for 101 U.S. metropolitan areas based on 2001–2010 records.
- HCM7 Chapter 25 has default day-of-week and month-of-year demand factors that can be applied to model seasonal traffic variation.
3.2 Approach for Rural Highways
The HCM7 Chapter 11 methodology is well-established and supported for freeway facilities. The arterial reliability methodology (HCM7 Chapter 17) is also covered in HCM7, although the tools and data to predict reliability on arterials are not as readily available as for freeways. There is currently no equivalent methodology for rural highways.
Travel time reliability on rural highways is generally much different than on urban arterials and freeways. In congested urban settings, travel times tend to be highly variable over time—both over a day and over a year due to seasonality, adverse weather, and the like. Roadways operating at or close to capacity are more susceptible to disruptions that can significantly increase travel time. However, few rural highways operate at or close to capacity during an average day. Instead, travel time reliability on rural highways is highly dependent on the origins and destinations served by the rural highway, natural disasters on or around the corridor, and disruptions such as crashes or work zones on parallel facilities. Furthermore, due to the lower volumes and sparser sensor coverage on rural highways, a predictive reliability methodology that requires a large number of data inputs is not likely to see much usage among agencies operating rural highways.
Because of these fundamental differences, the travel time reliability performance measures typically associated with urban travel are less relevant to rural highways. In addition, the differences noted in Chapter 1 regarding the higher variability in horizontal and vertical alignment, intersection traffic control, and lane configuration throughout a rural highway contribute to the need for a different methodology for assessing travel time reliability on rural highways.
Whereas the freeway and arterial reliability methods rely heavily on scenario generation and batch application of HCM7 methodologies, the rural highway methodology described in this chapter is more concerned with historical reliability performance and with applying LOS methods in a way that captures the full experience of a traveler traversing the often varied segments of a rural highway. The approaches outlined in Chapter 2 and this chapter can be applied with data that are generally available to rural transportation agencies. By combining the Chapter 2 methods to evaluate LOS and available capacity with the methods of this chapter to compute and visualize historical reliability performance, it is possible to identify seasonal patterns or spatial hot spots that might result in poor reliability performance in future years.
The remainder of this chapter covers data sources and analysis and visualization techniques that may be used in understanding travel time reliability for rural highways.
3.3 Data Examined
Historical reliability analyses are usually based on vehicular probe data, obtained from cell phone location-based services (LBS), and to a lesser degree connected vehicles and fleets. These devices “ping” their approximate locations at regular intervals, enabling the estimation of travel times and speeds along roadways. Although there are errors associated with the reported positions and timestamps, the high penetration rate of cell phones can produce large sample sizes that can accurately track average speeds and travel times. This is especially true for freeways and principal arterials, but lower-volume rural and residential roadways might not have enough samples to confidently estimate speeds and travel times. Most probe data are aggregated and sold by commercial vendors like HERE, INRIX, and TomTom. In support of the MAP-21 performance reporting requirements, the FHWA provides its National Performance Management Research Data Set (NPMRDS) free of charge to transportation agencies.
Higher-resolution probe vehicle data were examined for the potential to be used for travel time reliability assessments along rural highways. Unlike traditional probe data sources reporting on traffic message channels (TMCs) spanning from one major intersection to the next, the higher-resolution probe data sources report on segments up to 1 km (0.62 miles) in length. Furthermore, the temporal resolution of the data is higher as well, with data points every minute as opposed to every 5 or 15 minutes.
The data used for analysis were obtained from the INRIX XD Monitoring program. INRIX XD data are very similar to INRIX TMC data, with a key difference being that they use smaller spatial segments for data reporting. The underlying XD Monitoring program provides real-time insight into traffic speeds, travel times, and the location of incidents and backups for every major road type and class from highways, ramps, and interchanges to arterials, city streets, and other secondary roads. INRIX XD data are currently available through RITIS in about 16 states, with varying route coverage within each state. It is expected that this coverage, both within a state and across states, will continue to increase.
The analysis of the sample data from several sample corridors presented in Part 3 of the document (see Chapter 15) suggested that the higher-resolution probe data can improve travel time reliability analyses, especially when recurring congestion, queues, and queue spillbacks are primary contributors to reliability issues. With the traditional probe data sources, it is not often possible to observe queue spillback on rural highways, as the TMCs usually span several miles and the congested travel times (and resulting speeds) get averaged out with those at free-flow segments.
The data also supported a more detailed understanding of nonrecurring congestion due to adverse weather events (e.g., snowstorms) and holiday travel (e.g., Thanksgiving) on the sample corridors. Although higher spatial resolution is not as important for weather events and holidays,
it would be valuable in understanding the impact of other types of nonrecurring congestion—such as flooding, landslides, and other events limited to short segments of roadway.
Another key advantage of the higher resolution is that the data can pinpoint delays at intersections. On rural highways, most intersections do not impose delay to the highway (major street) travelers; delays are to side street traffic only. However, there are isolated intersections—including roundabouts, all-way stops, and traffic signals—that do result in delays to highway travelers. The higher-resolution probe data can be used to quickly understand the location and magnitude of those intersection delays without requiring additional data sources (e.g., GIS layers, traffic volumes, signal timings) or field visits.
3.4 Segmentation
Segmentation (see Section 2.2) is also a critical step when developing summaries of reliability data. Unlike in the Chapter 2 analyses, segmentation will not change the method that is used to analyze the data, but it is important to consider as it will impact the outcome of the analysis. For example, if an exceedingly long segment is analyzed, travel times on the segment will likely be reliable, as subsegments with poor reliability are typically washed out by much longer subsegments that are reliable. In addition, a very long segment spanning many TMCs will have fewer times when all TMCs have enough samples to report accurate travel times or speeds.
Best practices for segmenting facilities include those listed in Section 2.2, such as considering area context, posted speed limit, or changes in cross section. Fundamentally, the segmentation selected should be intuitive to travelers. This might be achieved by using segment starting and ending points that are also popular starting and ending points for trips (e.g., towns, major cross streets, major attractions). In general, segments up to 10 miles long can be readily analyzed and their results intuitively conveyed to users.
3.5 Data Overview
The data contain the following fields:
- XD segment identifier.
- Timestamp (options for 5 min, 15 min, and 60 min aggregations).
- Speed.
- Historical average speed.
- Reference speed.
- Travel time (in seconds or minutes).
- Confidence score.
- 10-Speeds showing the reference speed due to lack of real-time data.
- 20-Speeds showing the historical average speed due to lack of real-time data.
- 30-Speeds showing real-time data.
- C-Value (only when confidence score is 30).
- 0–100, denotes whether probe data are representing actual roadway conditions.
3.6 Evaluation Methodologies
The case study facilities were evaluated using five data analysis and visualization techniques that convert the INRIX XD speed and travel time data into charts and graphics for analysis and interpretation:
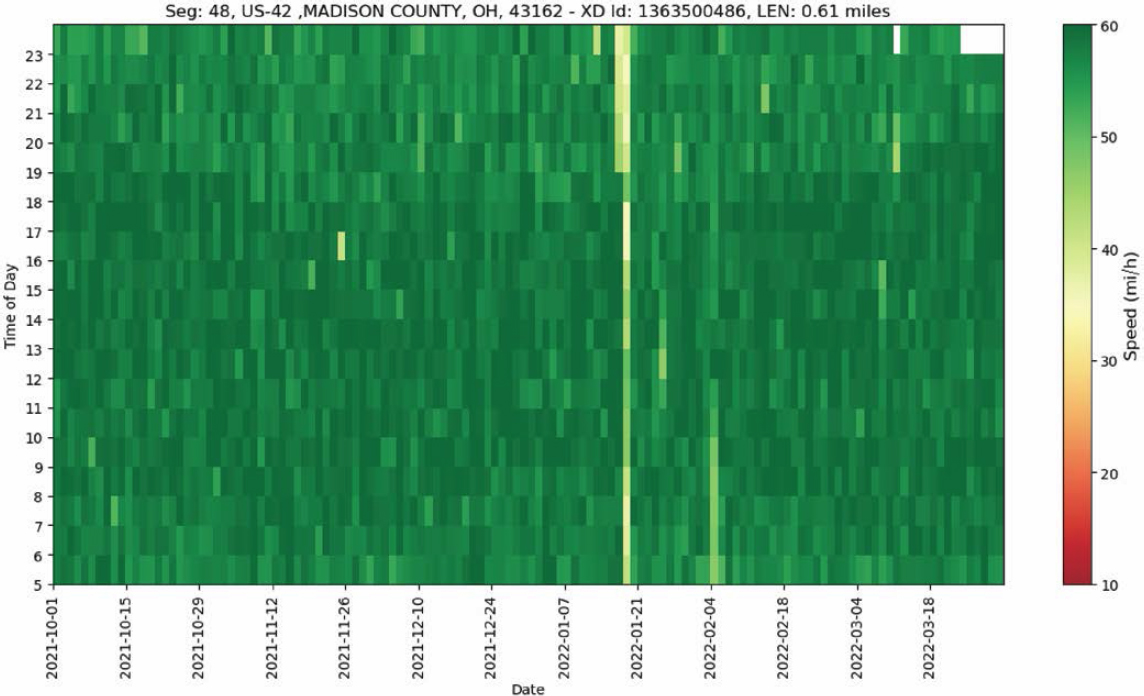
- Speed heatmaps provide an overview of the overall facility and can be used to quickly identify recurring bottlenecks. Combined with local knowledge about facility geometry and information
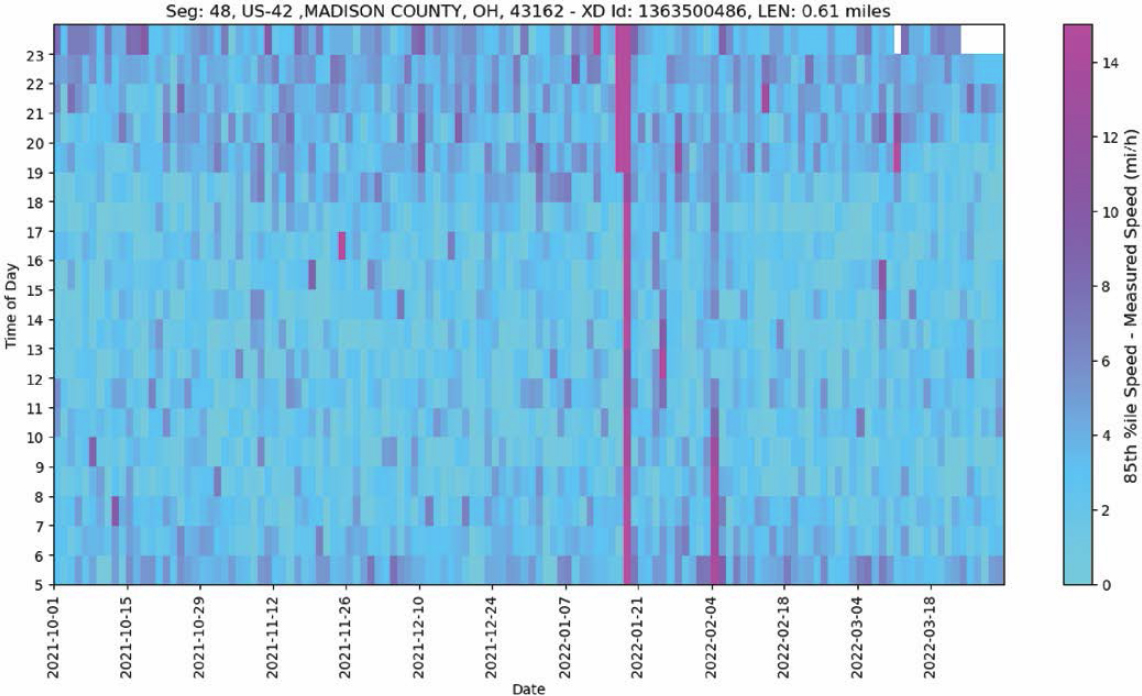
- Speed difference heatmaps normalize the heatmap patterns using a reference speed for each segment—in this case, the 85th percentile speed from the data as an approximation of FFS. This technique is particularly appropriate on long rural highways with a wide range of speed limits. The speed difference heatmaps more clearly highlight recurring and nonrecurring congestion patterns across segments and avoid potential visual bias introduced when traversing different speed limits and geometry-induced speed reductions along the corridor.
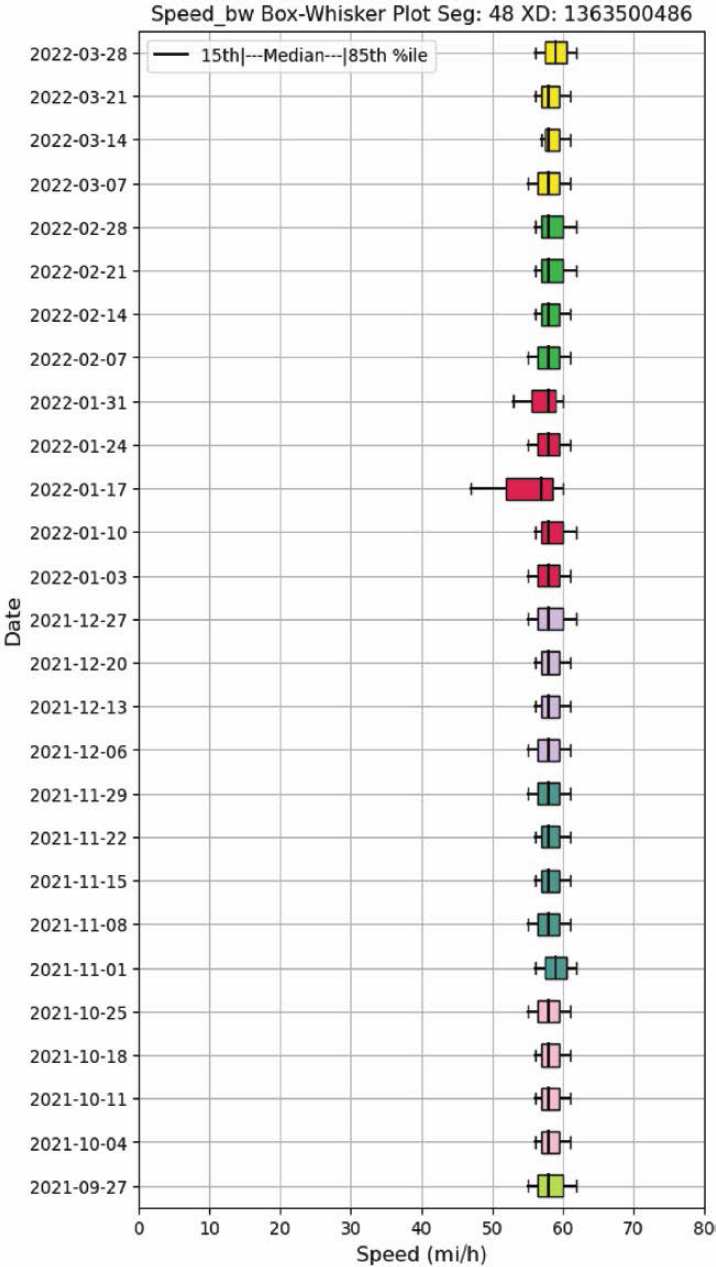
- Box-and-whisker speed plots help in identifying and narrowing down periods with poor reliability in the overall analysis period. It also complements inferences made using other visualizing metrics.
- Speed confidence band plots highlight the reliability of speeds at different hours using a year’s worth of data. They are a more easily interpreted visualization by removing the date dimension in the reliability data and showing reliability patterns by time of day only. The speed confidence band plots are especially useful when combined with a speed difference heatmap. In this combination, the speed confidence band plot can be used to infer which segment and which periods experience unreliable travel; the speed difference heatmap can then be used to infer what date ranges contribute to the unreliability.
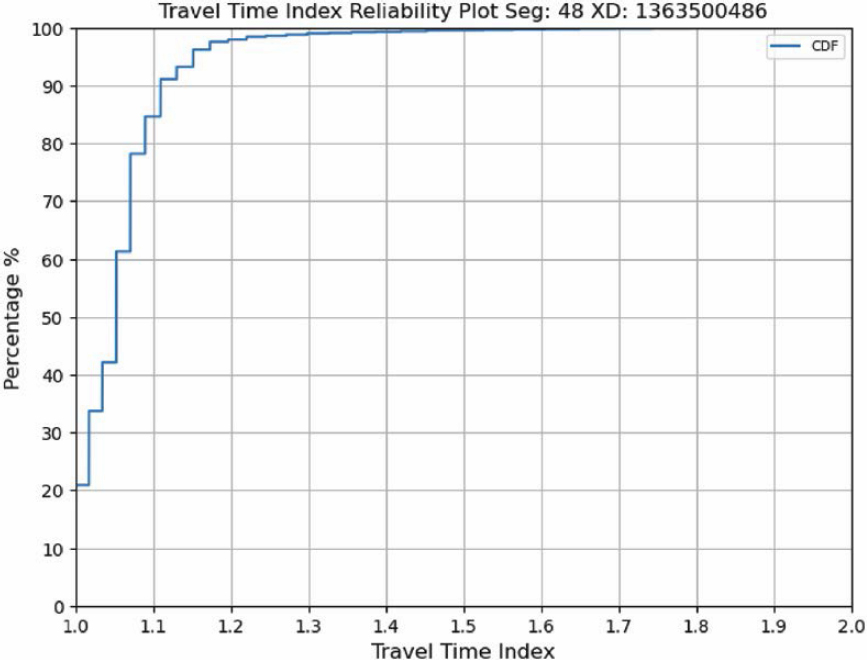
- TTI plots show the cumulative distribution of travel times along the segment, normalized by the free-flow travel time—which was estimated from the data as the 15th percentile travel time. The TTI metric is commonly used in congestion and reliability reporting and is defined in the FHWA Travel Time Reliability Measures. Due to its simple line representation, a TTI plot can be an effective tool to convey before-after comparisons.
on weather, construction, activities, events, and speed heatmaps can be used to paint a picture of facility reliability and potential patterns of recurring and nonrecurring congestion. The speed heatmaps developed for the case study facilities consist of time of day on the y-axis and date on the x-axis. They thus create a visual representation of the 24-hour speed performance (y-axis) across the entire period of analysis (x-axis), with each cell of the heatmap representing an individual INRIX XD speed observation. On these visualizations, speeds are aggregated to the hour and are visualized by a color scale from green (fast) to red (slow).
Python snippets to load, analyze, and visualize probe data using these five techniques are included in their respective sections. A complete Python script can be obtained from https://github.com/NCHRP-08-135/Resources/tree/main/Reliability.
3.7 Assessing Reliability
This section provides specific guidance and scripts that may be used to produce the reliability visualizations in Section 3.6, Evaluation Methodologies. As shown, the Python Pandas and Matplotlib libraries can be used to efficiently process and visualize probe data (in this case the INRIX XD data described previously).
3.7.1 Load the Data
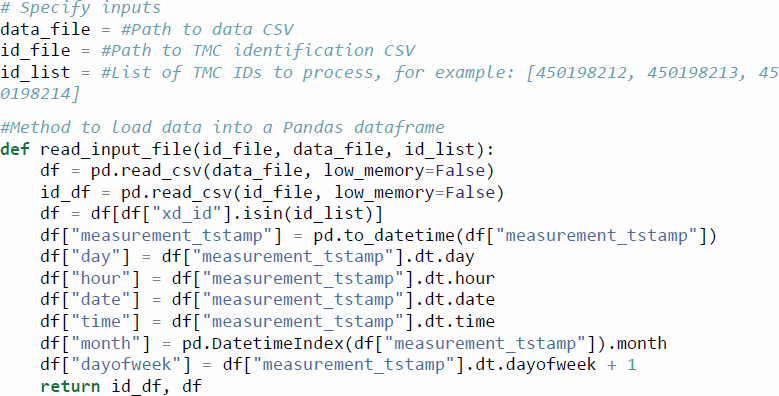
First, the probe data and metadata files must be obtained. For the case studies presented here, INRIX XD data were obtained through RITIS. Once on hand, the files can be loaded onto a Pandas dataframe using the following code:
3.7.2 Aggregate the Data
The INRIX XD data come at a high temporal resolution (1 minute), which is beneficial for fine-grained analyses of individual incidents or special events but can be cumbersome to display in visualizations covering 1 year of data or more. As such, the data are first aggregated to a suitable resolution for the analysis being conducted. In this case, an hourly resolution was considered adequate for these reliability analyses.
In addition to aggregating across time, the following code adds several calculated columns that simplify visualization of the data in later stages of the process. These include speed differences (from 50th, 85th, and 95th percentile speeds) and travel time indices (relative to 15th and 50th percentile travel times).
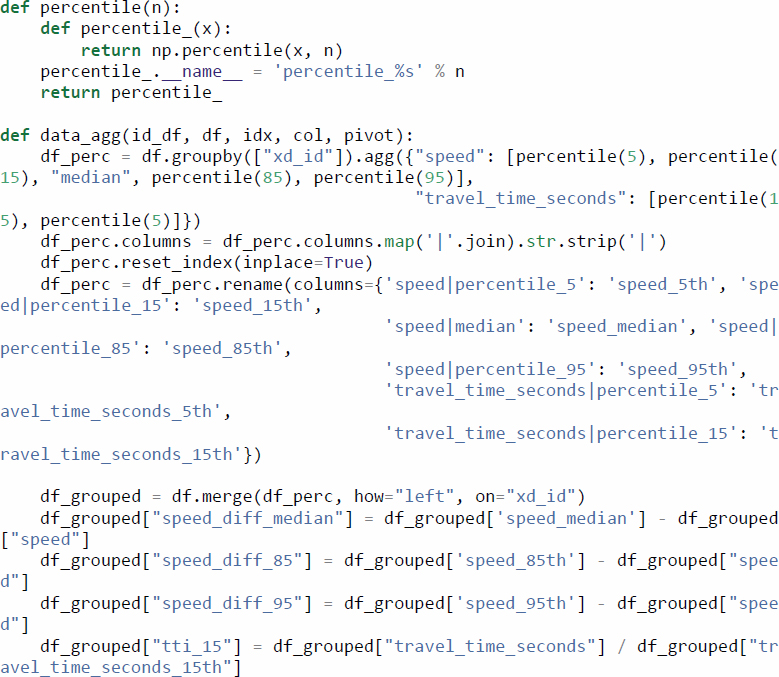

3.7.3 Heatmaps
The two types of reliability heatmaps described previously (i.e., speed and speed difference) can be generated with a single Python function. The value parameter can be set to either “speed” or “speed_diff_85” to instruct the function to use the appropriate column to generate a speed or a speed difference heatmap, respectively.
As is the case with the other visualizations presented here, the Matplotlib library offers several options to customize the chart’s area, title, legend, and more.
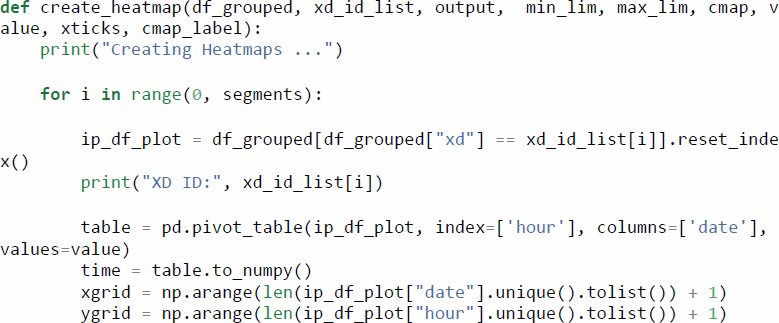

The resulting heatmaps can be seen in Figure 3.2 (speed) and Figure 3.3 (speed difference).
3.7.4 Box-and-Whisker Plots
Box-and-whisker plots display the minimum value, maximum value, and three in-between percentiles, usually the 25th, 50th, and 75th percentiles as shown in Figure 3.4. For purposes of reliability analysis, the 15th and 85th percentiles were considered more suitable as a representation of congested and FFSs, respectively.
The following code can be used to create weekly box-and-whisker plots to display the spread in travel times. The lower_df and upper_df parameters can be modified to display the desired lower and upper percentile bounds. In this case, the 15th and 85th percentile travel times are used.


An example of the box-and-whisker plot for a segment of Ohio US 42 is shown in Figure 3.5.
3.7.5 Speed Confidence Band Plots
Speed confidence bands can be configured to use different bounds depending on the goal of the analysis. For example, in a scenario where a reasonable best and worst case scenarios are sought, using a low percentile (e.g., 5th) and a high percentile (e.g., 95th) achieves the objective by covering 9 out of every 10 values in the data. In analyses that aim to describe typical conditions, a narrower band can be used (e.g., 15th through 85th percentiles). The following code supports these different use cases by entering different (integer) values in the lower_df and upper_df function parameters.

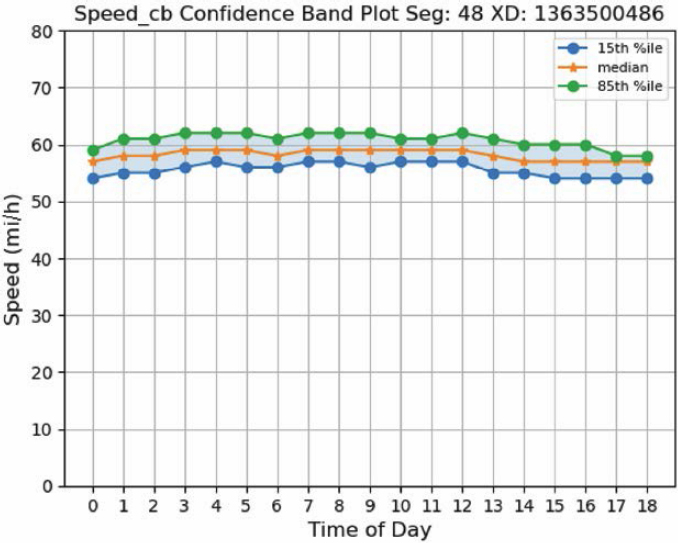
An example of the speed confidence band plot for a segment of Ohio US 42 is shown in Figure 3.6.
3.7.6 TTI Plots
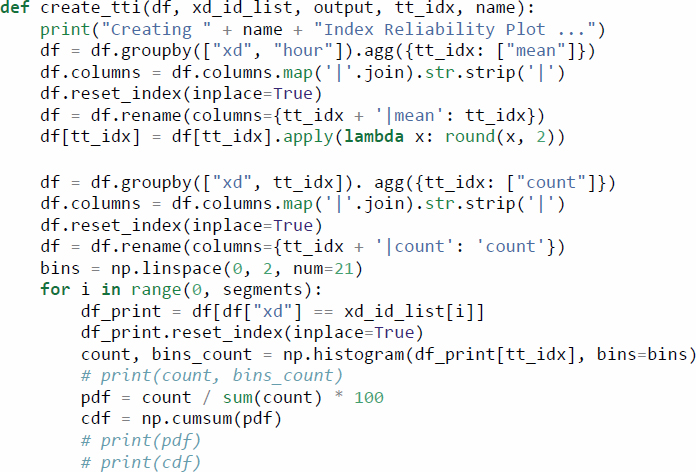
A cumulative distribution function (CDF) plot of TTIs can concisely describe how travel times or speeds are distributed across time or space. Because of the simple representation of the data (a single line), it can be particularly suitable for before-after comparisons. The following code is set to use a range of TTIs from 0.0 through 2.0 through the bins variable, although that can easily be adjusted for the range of TTIs in the data being analyzed. Increasing the number of TTI bins will reduce the size of the steps, leading to more continuous-looking plots.
![plt.figure(figsize=(8, 6)) plt.plot(bins_count[1:], cdf, label=“CDF”, marker=“o”)](https://www.nationalacademies.org/read/27895/assets/images/img-57-1.jpg)
An example of the TTI plot for a segment of Ohio US 42 is shown in Figure 3.7.