The Role of Advanced Computation, Predictive Technologies, and Big Data Analytics in Food and Nutrition Research: Proceedings of a Workshop (2024)
Chapter: 2 Setting the Stage
2
Setting the Stage
Highlights from the Presentations of Individual Speakersa
- Unsupervised, black-box algorithms lack interpretability of the representations that neural networks generate from data, which can result in a catastrophic failure. (Madabhushi)
- AI is not magic, and it needs to be used thoughtfully and intentionally when developing algorithms. Interpretability, reproducibility, and equity are key considerations. (Madabhushi)
- Although DL/AI algorithms can provide a great deal of information about patients, they can perpetuate bias and disparities when deployed widely. (Gichoya)
- Serious questions arise regarding privacy and regulation of AI systems, such as how and when to get consent for data sharing, are institutional review boards empowered to protect patient privacy in the era of AI, is it possible to sufficiently deidentify and anonymize patients, can patients opt out of data sharing, and is it different to get consent for data from an electronic health record (EHR) versus patient images. (Gichoya)
- Application of AI in nutrition research has a great potential to increase the capacity to manage and analyze big datasets and perhaps identify new relationships and patterns in diet, but it is difficult because of the complexities and difficulties in measur-
- ing relevant characteristics and relating them to the behaviors and societal factors that influence how and what people eat. (Lamarche)
- It is important to develop a common language and culture for the many disciplines that will use AI/ML in food and nutrition research. (Lamarche, Madabhushi)
__________________
a This list is the rapporteurs’ summary of points made by the individual speakers identified, and the statements have not been endorsed or verified by the National Academies of Sciences, Engineering, and Medicine. They are not intended to reflect a consensus among workshop participants.
AI AND HEALTH
Anant Madabhushi, the Robert W. Woodruff Professor and research neuroscientist in the Departments of Biomedical Engineering, Radiology, and Imaging Sciences and Biomedical Informatics and Pathology at both Georgia Tech and Emory University, said that artificial intelligence (AI) has implications for a wide range of areas, including health care, education, and agriculture. His research group has been examining the use of AI with computational imaging technologies for developing better diagnostic, prognostic, and predictive tools capable of identifying the presence or absence of disease and predicting disease outcome, progression, and response to treatment and other interventions. He noted that “precision medicine” refers to the development of prognostic and predictive tools for tailoring therapy for a patient based on their specific risk profile.
Madabhushi explained that deep learning (DL) serves as the foundational architecture of large language models, such as ChatGPT, and refers to a particular variety of machine learning (ML) algorithms. DL algorithms are based on neural networks. Although researchers have been working on neural networks for over 60 years, it has only been with the advent of more powerful computers that they have been able to stack them in sophisticated and complex ways, with individual neurons in the network coding for representations of the data. “You now have the ability to absorb and ingest large amounts of data and learn from those large amounts of data to be able to create these networks that are then able to make predictions based off the data that is being ingested,” said Madabhushi.
As an example of how his team has applied this approach to medicine, Madabhushi cited using DL to detect malignant cells in breast pathology images (Lu et al., 2016; Xu et al., 2016; Zhang et al., 2016). With annota-
tions of individual cells in an image of a scanned pathology slide, the network can learn which representations best distinguish a cell of interest from all other cells. Those patterns, he said, are encoded within the individual neurons in the neural network. Each encoded representation is generated automatically by the algorithms that make up the DL framework. “There is no explicit knowledge or explicit predicate features that are being provided to the neural network,” said Madabhushi. “The neural network is learning this in an unsupervised manner.” The network learned the representations that best describe individual cells and then predicted the precise location of these cells on new images.
The advantage of this type of algorithm, Madabhushi explained, is that it is data driven. In other words, without having any knowledge of breast cancer or pathology, Madabhushi’s students were able to create the algorithm and identify individual cells. The caveat is that the representations the network is learning from the data are abstract, and because it generates representations that lack interpretability, these algorithms are often called “mysterious machines” or “black boxes.” This lack of interpretability can result in a catastrophic failure.
For example, Madabhushi’s team attempted to build a DL neural network to predict the presence of heart failure from endomyocardial biopsies (Nirschl et al., 2018). His collaborators at the University of Pennsylvania provided digital images of pathology slides of endomyocardial biopsies from 100 patients and noted whether heart failure was present. His team used the annotated images to train a neural network, and the resulting weakly supervised algorithms, so called because they develop without detailed information, had free rein to learn features on each pathology slide.
With the algorithm training complete, his collaborators sent slides from a different set of 100 patients. As a check, two cardiac pathologists reviewed the same slides and made their own predictions. The DL network’s predictions were 97 percent accurate, and the expert pathologists were only 74 percent accurate. However, when his collaborators sent another set of images, the algorithm’s accuracy fell to 75 percent, raising the question of why the performance had dropped so precipitously. The slide scanner had received a software upgrade, which subtly changed the appearance of the individual slides. From a human perspective, the change was unnoticeable, but for the ML network, it was sufficient to diminish performance significantly. “This goes back to this issue of interpretability, because if you do not really understand fundamentally what the network is picking up, then you can have examples of these catastrophic failures where the network suddenly fails,” he explained.
Madabhushi cited another research group’s work developing a DL algorithm to distinguish between a wolf and a husky (Ribeiro et al., 2016). The investigators trained the algorithm using pictures from the Internet;
when tested against a separate set of images, it was 99 percent accurate, which was surprising because it is hard for humans to tell these two animals apart. However, the network was not picking up any features of the animals’ faces but rather whether the picture’s background showed snow. “The network had latched onto features that were completely unexpected, and this reiterates the issue of the lack of interpretability, because sometimes it may work but it is not working for the reasons that you would expect,” said Madabhushi.
Cynthia Rudin at Duke University has spoken eloquently, said Madabhushi, about the need to exercise care when imbuing interpretability into black-box models, particularly for high-stakes decisions (Rudin, 2019). She called for focusing on inherently interpretable approaches and designing models with intentional interpretable attributes or hallmarks built into them.
Madabhushi listed key considerations for developing AI tools for precision medicine and precision nutrition. The first is interpretability and developing handcrafted, engineered approaches that start with a set of attributes or features with more inherent interpretability. A second consideration is affordability and taking advantage of routinely acquired data, particularly in low- and middle-income countries that may lack the ability to acquire sophisticated data or sophisticated technology to acquire more data. The third consideration is equity and whether an algorithm works across populations or is biased toward a particular population.
One example of his group’s work that tries to accommodate these considerations involved leveraging the power of AI to identify lung cancer and the associated tumor habitat using interpretable, noninvasive radiomic biomarkers. Instead of merely providing slide images and letting the algorithm learn unsupervised, Madabhushi’s group identified individual cells, different tissue compartments, the architectural arrangement of different cell types, the network arrangements between different cell types, the shape of individual cells, and the appearance of the different tissue compartments in which these cells reside. Using these more interpretable features produced more accurate predictions, enabled determining the tumor phenotype, and segmented out the tumor-associated habitat (Bera et al., 2022).
His team has applied this more intentional approach to a variety of diseases and therapeutic regimens. Using routinely acquired data, such as radiologic scans and pathology images, the resulting algorithms can make predictions of therapeutic response. For example, his team developed an algorithm capable of predicting which women with breast cancer would have short-term versus long-term survival from one specific tumor feature: whether collagen fibers were ordered or disordered (Li, H. et al., 2020, 2021b). Those with disordered collagen had a better prognosis and longer survival, which makes sense given that ordered collagen tends to promote metastasis.
Madabhushi said that the image-based assay also provided significant additional value to more expensive molecular-based tests. Specifically, image classification identified a subset of patients (12 percent of those designated as having a low risk of premature death by the molecular test) who had significantly worse outcomes, suggesting that they should have received chemotherapy. Conversely, the image classifier identified 58 percent of those whom the molecular test identified as high risk and candidates for chemotherapy who actually had significantly lower risk and could possibly have avoided chemotherapy.
It is important, said Madabhushi, to develop more population-tailored models and AI algorithms that account for differences among populations. His team has developed such a model for uterine cancer, which has subtle differences between Black and White patients (Azarianpour Esfahani et al., 2021), that produces more accurate predictions for both Black and White people compared to population-agnostic models. Similarly, an AI-powered model of immune cell architecture extracted from uterine cancers accurately predicted prognostic differences between African and European American patients. They also developed a population-tailored model for breast cancer, which has differences between South Asian and North American patients (Li, H. et al., 2021a).
Another AI-powered algorithm his team developed was able to quantitatively and accurately capture the amount of liver fat from computed tomography scans (Modanwal et al., 2020). “What has been interesting is that we are starting to see a strong association between the AI-quantified liver fat and cardiovascular disease,” said Madabhushi. His team has validated this algorithm in some 47,000 patients. By leveraging standard ultrasound images, they also developed an AI-powered algorithm that can predict major adverse cardiovascular events in chronic kidney disease patients (Dhamdhere et al., 2023) and another that uses twistedness of the vessels in the eye to predict response to therapies for eye disease (Dong et al., 2022). Recent data suggest that vessel twistedness might be able to predict Alzheimer’s disease and heart disease.
Madabhushi said that AI is not magic. It needs to be used thoughtfully and intentionally when developing algorithms, with interpretability, reproducibility, and equity being key considerations. Unsupervised and supervised AI approaches provide a trade-off between not requiring domain knowledge and interpretability, but independent of the approach, rigorous validation is needed across different test sites. Finally, it is crucial to create carefully curated, representative, and inclusive training datasets for AI and nutrition.
ETHICS, PRIVACY, BIAS, AND TRUST IN THE APPLICATION OF AI
Judy Gichoya, associate professor of interventional radiology and informatics at Emory University, said that applying AI to predictive nutrition will be a bigger, more difficult task compared to using it with imaging data. She noted the harm of not sharing health data and that inequitable data access may lead to expensive and adverse data outcomes.
Gichoya said that it is difficult for experts to agree on what a fair algorithm is and whether it is fair to an individual or a group (see Figure 2-1). She showed examples of unfairness. In one case, where researchers examined the accuracy of four DL models designed to segment cardiac magnetic resonance images, all four models had performance biases depending on whether the images came from a man or woman or a Black versus a White individual (Lee et al., 2023).
In another case, a DL model for analyzing chest radiographs severely underdiagnosed underserved patient populations, including women, Black individuals, and people on Medicaid (Seyyed-Kalantari et al., 2021). Moreover, intersectionality was an issue: a Black woman on Medicaid, for example, had the greatest possibility of being underdiagnosed, but the model produced better results for Black women on private insurance. This intersectionality arises because of the interactions of many factors in an individual’s life and how those factors change across the lifespan. “This intersectionality is something we still do not understand regarding how to evaluate for fairness, especially when we are trying to fit this to a single mathematical function,” said Gichoya.
She also cited a study showing that a commercial algorithm used to determine who is eligible to be referred to managed care and receive home health care rather than return to the hospital is severely biased by race (Obermeyer et al., 2019). This research showed that Black patients assigned the same level of risk as White patients by the algorithm are actually sicker. The investigators determined that bias happens because the algorithm treats health costs as a proxy for health needs. Less money is spent on Black patients with the same level of need, so the algorithm falsely concludes that they are healthier than White patients who are equally sick.
She mentioned another example in which AI biased the human experts. In this work, investigators presented radiologists with a set of mammograms along with a correct assessment provided by an AI system and another set accompanied by an incorrect AI-generated assessment (Dratsch et al., 2023). With bad information, the radiologists’ performance fell. In other words, AI-generated information biased the radiologists, leading them to discount their own expertise. “What is surprising is [that] you can mislead the most experienced people based on the type of output and when you integrate AI,” said Gichoya.
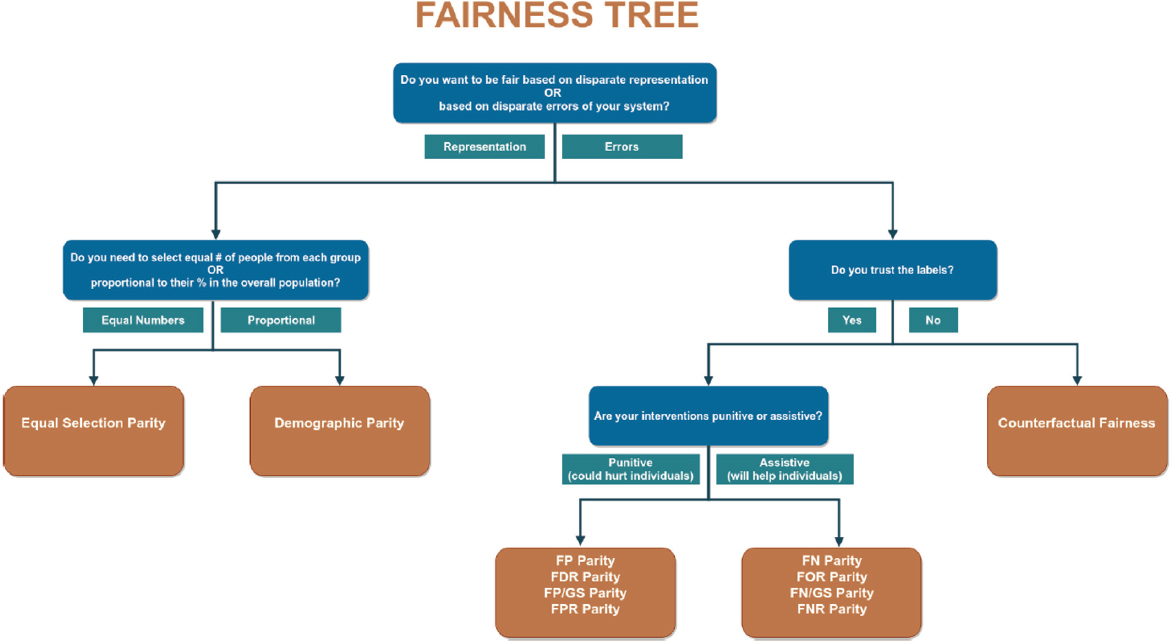
SOURCE: Presented by Judy Gichoya on October 10, 2024, at the workshop on The Role of Advanced Computation, Predictive Technologies, and Big Data Analytics in Food and Nutrition Research; Saleiro et al., 2018.
Turning to the subject of bias in data collection, Gichoya said that investigators can introduce bias in their data depending on how they assemble a dataset. For example, in imaging studies, the investigators might not image all eligible patients or could inadvertently include mislabeled images that skew the dataset (Drukker et al., 2023). Using an incomplete set of possible labels when characterizing the information-dense images that inform ML models leads to a phenomenon known as “hidden stratification” (Oakden-Rayner et al., 2020).
As an example, she described a study in which researchers developed AI systems that appeared to accurately detect COVID-19 in chest X-rays. However, closer examination found that these systems were relying on confounding factors rather than actual pathology, similar to the results Madabhushi noted in his wolf–husky example. As a result, said Gichoya, these systems failed when tested with images from a different hospital (DeGrave et al., 2021).
Gichoya cited a study by herself and her collaborators in which they detected racial and ethnic health disparities using DL with chest X-rays and compared the results to administrative diagnostic codes in COVID-19 patients (Pyrros et al., 2022). The discrepancy between the model’s assessment and the administrative code was associated with language preference or a social deprivation index, suggesting that it is an independent predictor of health disparities.
In other studies, she and her collaborators were able to detect type 2 diabetes using DL informed by frontal chest X-rays (Pyrros et al., 2023) and identify a patient’s race (Gichoya et al., 2022). Similarly, other groups have shown that DL models could predict health care expenses (Sohn et al., 2022) and estimate biological age (Mitsuyama et al., 2023; Raghu et al., 2021) from chest X-rays. One of the latter studies also found that the DL-based chest X-ray age could predict long-term all-cause and cardiovascular mortality (Raghu et al., 2021). She noted the difficulty of explaining these results and emphasized that although these algorithms can provide a great deal of information, they can perpetuate bias and disparities when deployed widely.
Gichoya concluded by acknowledging that the federal government is focusing on discrimination and bias in AI systems. At the same time, serious questions arise regarding their privacy and regulation, such as how and when is consent needed for data sharing, are institutional review boards empowered to protect patient privacy in the era of AI, is it possible to sufficiently deidentify and anonymize patients, can patients opt out of sharing their data, and is there a mechanism to obtain partial consent versus no consent for sensitive patient images.
THE PROMISES AND CHALLENGES OF AI IN NUTRITION AND FOOD SCIENCES
Benoît Lamarche, professor in the School of Nutrition at Université Laval and scientific director and founder of the Nutrition, Health, and Society Center (NUTRISS), said that the center focuses on precision nutrition, eating behaviors, and nutrition and society. He noted that AI has great potential in nutrition research, but it is difficult because of the complexities and difficulties in measuring relevant characteristics and relating them to the behaviors and societal factors that influence how and what people eat.
Lamarche explained that with traditional statistics, researchers take their data, decide that the model will be to explain those data, and then use the model to predict an outcome. With AI/ML/DL methods, the data and results are the inputs, and the output is the model that makes predictions. He noted that AI, as with traditional statistics, follows the garbage in, garbage out paradigm. For example, the Canadian National Health Survey on Nutrition uses 24-hour recall as its data source. Robust ways exist to deal with measurement error and under- or overreporting of food and energy intakes using sophisticated statistical methods. Overlooking these errors with AI-based methods may introduce bias into the final model with unknown consequences for the results. This is problematic because data show, for example, that underreporting is not systematic across all foods people report to have eaten, with a large proportion of it related to specific foods, particularly low-quality foods. Measurement errors make the “image” of dietary intake fuzzy, akin to pictures with poor-quality pixels, for which AI-based methods have limited capacity.
Nevertheless, AI shows promise to enhance nutrition research, such as by increasing the capacity to manage and analyze big datasets and perhaps identify new relationships and patterns in diet (Côté and Lamarche, 2021; Kirk et al., 2022). Combining genetics, dietary intake, and social and demographic data may provide a better understanding of dietary patterns and enable more accurate prediction of health outcomes. It may be that people taking pictures of their meals with a smartphone can provide enough data for AI approaches to identify dietary patterns. However, this would have limitations. For example, a photo showing a plate of spaghetti and meatballs does not reveal how much meat or vegetable protein is in the sauce or how much salt the meal contains. Other challenges include the need to standardize methods, build capacity, and develop a new vocabulary and for nutrition researchers to understand the culture of AI researchers and vice versa. For example, p values and collinearity are generally not problematic in AI-based methods, which researchers used to traditional statistical methods must adapt to (Côté et al., 2022).
Non-image-based methods may also provide useful data to power AI models, said Lamarche. For example, devices attached to eyeglasses can estimate how long a person is chewing foods by detecting facial movements. However, they cannot tell what the person is chewing or how much food they have actually consumed on one occasion or over a longer term.
Lamarche reinforced the need to standardize dietary patterns methods and scores to advance the field (Reedy et al., 2018). There is also a need to develop methods and models that capture the totality of the diet and to evaluate the effect of measurement error and develop methods to adjust for this error.
Capacity building will be key, said Lamarche. In collaboration with the Sorbonne, NUTRISS held a boot camp in 2023 that brought together AI and nutrition researchers. The two sets of experts worked together to learn each other’s vocabulary and culture; in hands-on activities, nutrition students learned to code different algorithms and the AI engineers learned what to do with the data the algorithms produced.
MODERATED DISCUSSION
Rodolphe Barrangou, the moderator, asked the panelists to name the biggest opportunity or challenge. Madabhushi replied that the biggest opportunity is the ability to take advantage of routinely acquired data that are not being exploited. The challenge will be identifying and pulling together equitable and representative datasets from multiple institutions. Gichoya called the challenge of using AI in nutrition research a “moonshot problem” because it is so big and complex. “I am not so sure, as an AI researcher, that AI is the solution if we cannot figure out the data and the standards,” she said. To Lamarche, the opportunity lies in changing the perspective on the link between diet and health and ensuring that researchers who move into this area are mindful of the limitations of the available data. He also noted the opportunity to learn more about the intricacies of diet and health, although AI will not get people to eat more fruits and vegetables.
Barrangou asked the panel about reconciling the problem of having a wealth of diverse existing datasets yet wanting data to be standardized. “Is it a matter of restructuring data we already have and parsing it out in certain formats, or do we need to rethink how we collect data and start from scratch?” he asked. Gichoya replied that it is impossible to start from scratch and will be difficult to agree on standards, making efforts to harmonize datasets critically important.
Madabhushi agreed that trying to fit standards to existing data will be challenging, but the opportunity is to think intentionally about the standards, qualifications, and guardrails needed for the data to be useful for AI
models. Lamarche noted the need to develop a culture for these nutrition studies, which will require a big community of people starting to think in a concerted manner about data limitations and how to deal with them. Both Madabhushi and Lamarche pointed to the need to develop a common language the nutrition and AI communities can use.
Where the AI field can help, said Lamarche, is taking individual data, connecting them with the variables that influence individual choice, and identifying actionable variables or features that public health can use to educate the public and change behavior. Madabhushi commented that the examples he and Gichoya shared produce correlations and not causative associations. Over time, AI may be able to generate causative associations, but meanwhile, correlations may be sufficient to develop intervention trials based on evidence, he said. Historically, Barrangou added, nutrition research has established correlations rather than causation, but AI may develop some ability to predict outcomes that can enable preventive interventions. Madabhushi added that AI-generated risk predictions could inform educational efforts to change behaviors or even help point to healthier alternatives that could replace nutritionally poor foods.
Barrangou asked the panelists for their ideas about how to build the multidisciplinary teams needed to advance the field. One approach Gichoya has used is to hold a datathon, which brings together people from a range of fields—clinicians, data scientists, programmers, AI experts, social scientists, and others—to work on a large set of real-world patient data from a variety of perspectives. This has been a successful model that has started new partnerships and brought new researchers into the field.
This page intentionally left blank.











