Generative Artificial Intelligence in Health and Medicine: Opportunities and Responsibilities for Transformative Innovation (2025)
Chapter: 4 Application Readiness Cadence
4
APPLICATION READINESS CADENCE
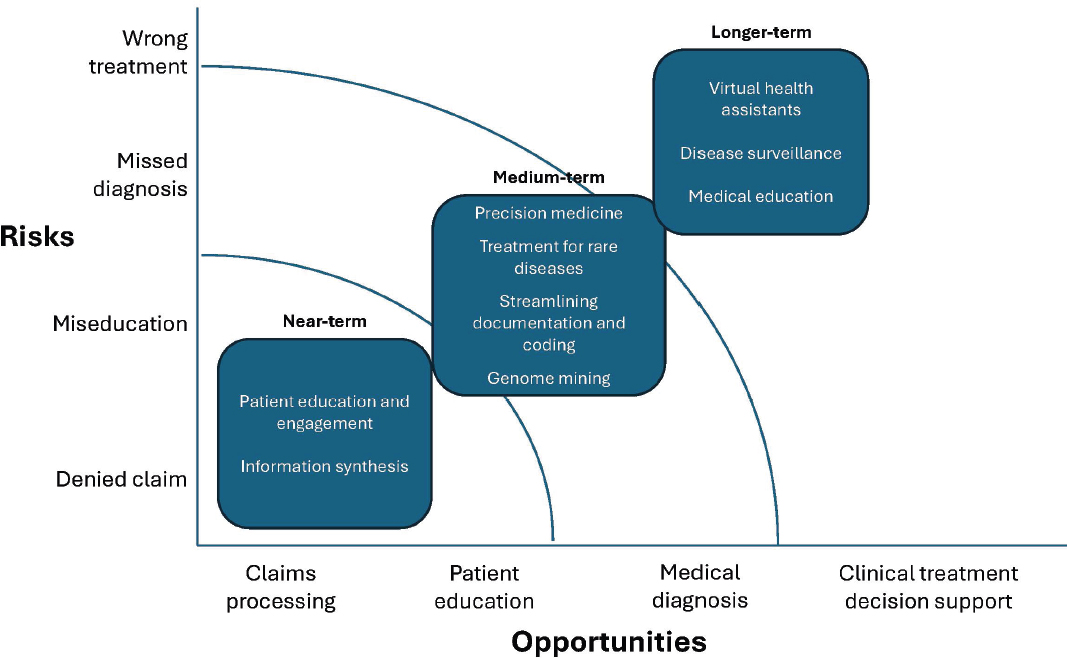
Large language models (LLMs) powered by advancements in generative AI (GenAI) and natural language processing, hold promise in augmenting patient care and clinical workflows. At the same time, the risks inherent in GenAI and their application to health care require careful consideration and development. As a result, some lower-risk applications of GenAI in health care, such as ambient LLM scribing for ambulatory clinic visits, are closer to clinical deployment than higher-risk applications such as virtual health assistants (Tierney et al., 2024). Below and in Figure 4-1, we identify near-, mid-, and long-term applications of LLMs in medicine and health care, organized by their specific opportunities and risks for patients, clinicians, and health systems.
NEAR-TERM APPLICATIONS
Patient Education and Engagement
LLMs are poised to enhance patient education and engagement through personalized health information dissemination. AI-based conversational agents have already demonstrated reasonable proof of concept in areas like mental health, with prospective studies demonstrating reductions in depression and distress (Li et al., 2023). The underlying learning architecture of modern chatbots has evolved from predictive natural language processing and speech recognition software to generative LLMs that process large text-based datasets to translate, predict, and produce content. Chatbots and virtual assistants powered by LLMs can augment prior efforts by providing tailored responses to patient queries in patient-friendly, culturally appropriate language, improving health literacy and adherence to treatment plans. There is already emerging evidence that LLM chatbots can improve understandability and readability of decision support around informed
consent for surgery, although, unchecked, such chatbots may reinforce biased decision making (Decker et al., 2023; Omiye et al., 2023).
Information Synthesis
LLMs can facilitate automated summarization of medical records, aiding clinicians in quickly extracting relevant information during patient encounters and reducing administrative burdens (Van Veen et al., 2024). Large EHR vendors have already integrated LLMs to summarize information from EHRs and these programs have been implemented in several health systems (Goodman et al., 2024). Cohort retrieval is a particular application of LLMs, with existing applications involved in recruitment for clinical trials, protocol design, and retrospective studies (Jin et al., 2023). Additionally, LLMs show promise in accelerating clinical decision making through real-time literature review and evidence synthesis. By analyzing vast volumes of medical literature, these models can assist clinicians in staying abreast of the latest research findings and treatment guidelines, thereby supporting evidence-based practice. However, without careful tailoring of clinical questions, LLMs are prone to factual inaccuracies in evidence synthesis (Tang et al., 2023).
MID-TERM APPLICATIONS
Precision Medicine
A large strength of LLMs is their ability to synthesize large amounts of information for prognostic and predictive risk assessments. By analyzing multimodal data, including EHRs, genomics, and imaging studies, LLMs may be on a path to assist in treatment selection (Wilhelm et al., 2023). That said, early efforts in this capacity have demonstrated some limitations, such as confusing or incorrect recommendations, so significant quality improvements will be needed before this capacity is ready for real-world deployment. In areas like precision oncology, a major limitation of current LLMs for personalized treatment and decision support is their inability to generate accompanying evidence that is useful for clinicians (Benary et al., 2023). This inability to include clinical domain knowledge into decision making may explain the suboptimal performance of current LLMs for treatment selection and disease management and may foreshadow the need for integrating neurosymbolic reasoning for next-generation decision support to improve interpretability and generalizability.
Treatments for Rare Diseases
There is an urgent need for novel therapies of rare diseases, including genetic diseases, but clinical trials in this space are often underpowered, fail to meet enrollment targets, or do not yield effective therapies (Rees et al., 2019). GenAI can provide powerful insights and knowledge linking between the emerging mechanistic understanding of an increasing number of rare diseases with existing therapeutics that might prevent or treat those rare diseases. Computational simulations of clinical trials, termed in silico trials (ISTs), have the potential to salvage some of the resources devoted to failed pharmacological studies in rare diseases and speed the development of promising therapies by enabling better powered trials, simulating control and efficacy arms, and optimizing patient recruitment and drug protocols (Kolla et al., 2021). Digital twins (DTs) are a related concept, defined as a computational representation of an individual patient or disease (Moingeon et al., 2023). DTs may represent a specific organ, disease process, or entire patient modeled from high-resolution imaging, genetic, or physiologic function. DTs aim to facilitate virtual experiments and subgroup analyses of investigational agents that would otherwise be difficult or risky to conduct in real patients; this is particularly salient in rare diseases, where treatments may carry a higher risk profile. Many current DTs utilize AI and machine
learning (ML) methods for functions that include better optimizing patient matching, simulating counterfactuals, and predicting downstream response. It can be challenging to create separate digital twins for specific diseases; the advent of LLM foundation models can facilitate cross-disease digital twins that could be used to simulate the effectiveness of various drug combinations (Bartlett et al., 2019; Cosmas et al., 2024).
Streamlining Documentation and Coding
Through natural language understanding, LLMs can automatically generate comprehensive clinical notes and assign appropriate billing codes, enhancing revenue cycle management in health care settings (Yang et al., 2023). Generation of appropriate billing and procedural codes may also ensure reliable claims-based datasets that are used for observational and economic studies in health care (Yang et al., 2023). Such tools could also be used to extract important metrics of social determinants of health from unstructured clinical text (Guevara et al., 2024). Platforms like ChatGPT have had markedly high accuracy in detecting diagnosis codes from unstructured text and inferring disease modifiers, although this performance may vary by disease. Furthermore, similar general-purpose LLMs may have large levels of inaccuracy with diagnosis codes, especially with rarer diseases (Hadi et al., 2024; Harada et al., 2024).
Genome Mining
Despite the progress made in understanding genetic contributions to disease through efforts such as the Human Genome Project, the phenotypic impact of many variants in the exome and transcriptome remains unknown. LLMs can be trained on billions of genomic variants to predict effects of heretofore uncharacterized genomic variants. So-called DNA language models may augment traditional genome-wide association studies and lead to more accurate characterization of variants of unknown significance, which can uncover new therapeutic options for diseases like cancer.
LONG-TERM APPLICATIONS
Virtual Health Assistants
Given appropriate validation, LLM-powered virtual health assistants can conduct symptom assessments, provide triage recommendations, and facilitate
remote consultations, expanding access to care in regions where access to in-person health care is limited. Such models may be able to adapt to new evidence and treatment faster than traditional medical professionals, offering access improvements (Sezgin, 2024; Tadesse et al., 2023).
Disease Surveillance
LLMs can contribute to the development of disease outbreak detection and management tools. By ingesting diverse data sources, including population health data, laboratory data, social media trends, and environmental factors, these models can generate more comprehensive insights to aid in early identification of public health threats and inform timely interventions. Such efforts to bolster pandemic preparedness and response efforts may be extremely beneficial for future outbreaks akin to the COVID-19 pandemic. However, safe and effective deployment in this space is limited by access to real-time reliable sources of data to inform forecasting models.
Medical Education
The current paradigm of medical education is based on potentially identifiable patient vignettes or hypothetical cases of limited disease phenotypes. In areas requiring visual interpretation, like radiology and dermatology, datasets are often limited to specific populations while underrepresenting other groups or pathologies. When armed with representative data and appropriate clinical domain knowledge, LLMs may generate synthetic images and cases that can inform more representative, equitable medical education materials that represent diverse pathologies (Safranek et al., 2023).
This page intentionally left blank.





