A Roadmap for Disclosure Avoidance in the Survey of Income and Program Participation (2024)
Chapter: Summary
Summary
The Survey of Income and Program Participation (SIPP) is one of the Census Bureau’s major regularly repeating surveys, with the first interviews conducted in 1983. It is designed to collect information about the costs, impacts, and effectiveness of government social programs designed to help the poor, and to answer questions about short-term financial and family dynamics. While largely focused on collecting financial data on income, assets, and expenditures, it also collects detailed information about the composition of households. It is unique in combining three features: an extremely large number of variables across multiple domains, detailed information on participation in social assistance programs, and the capacity to track monthly changes over a four-year period. These features make it a uniquely valuable resource for researchers and policy analysts, across a wide variety of domains.
While the Census Bureau has a general responsibility to protect the confidentiality of its survey respondents, SIPP presents special challenges. Because of the types of financial and personal data collected, the data can be considered highly sensitive, making confidentiality even more important. At the same time, SIPP collects so much data about multiple people in a household that there is a heightened possibility, relative to most surveys, that those data can be combined in a way that will uniquely identify an individual. For example, the SIPP 2020 data include a household in Florida with a Black male born in 1946 married to, and sharing the household with, an Asian female born in 1941, also with a child born in 1968 in the household; this combination of characteristics is sufficient to make the household unique
within the SIPP sample, and one could add additional data from SIPP such as occupation, educational level, and homeowner/renter status that might make the household both unique and identifiable in the entire nation.
Furthermore, the amount of data available from external sources that might be used to identify a SIPP respondent continues to increase. Many types of data are available on the public record, and while those data once were highly localized, the development of internet search tools and powerful software allows the data to be aggregated into comprehensive databases. These data appear in commercial databases for tasks such as credit-checking, marketing, and house purchasing. As another example, as part of a policy of transparency some states have published detailed information on the assistance they provide to needy individuals. Thus, databases that once might have been secure are becoming less secure as new data tools arise. Traditional practices used to protect the privacy of survey respondents are becoming less sufficient.
To determine the most appropriate disclosure avoidance procedures to use for SIPP, the Census Bureau asked the National Academies of Sciences, Engineering, and Medicine to convene an expert panel to address the following charge (Box S-1).
In response, the National Academies formed a panel consisting of experts in statistics, survey methodology, economics, computer science, data science, policy evaluation, and sociology.
The panel organized the statement of task into four broad questions:
- What are the needs of researchers and the general public in terms of making use of SIPP data (Chapter 2)?
- What are the disclosure risks facing SIPP, and how can they best be assessed (Chapter 3)?
- What tools are available for addressing disclosure risks in SIPP, and how do they compare (Chapters 4 through 8)?
- What is the proper balance between protecting the confidentiality of respondents while supporting the best way to use data for valid inferences (Chapter 9)?
To address these four questions the panel conducted literature reviews; invited outside experts to provide information on SIPP, disclosure avoidance approaches, and data ethics; examined the 2020 SIPP public-use file and its documentation; and conducted a data collection asking SIPP data users to complete a short online questionnaire about their experiences in working with SIPP data.
THE PANEL’S CONCLUSIONS
SIPP Is a Unique Resource and Continuing Access Is Important
The panel found SIPP data to be a unique resource, offering data that are useful across a wide variety of research topics and academic disciplines. They are a major source for policy analysis, both by the federal government and by academic researchers. SIPP is used to examine multiple aspects of the U.S. economy, monitor the use of federal programs, examine the need for and impact of policies and programs, and conduct sociological research on topics such as parental presence and children in shared households. For example, by providing information on income, demographic characteristics, and program participation, SIPP can be used to model the impact of changing eligibility requirements.
The public-use file is the version of the data that has received the greatest use; therefore, maintaining such access should be a top priority with steps taken to protect confidentiality by limiting statistical disclosure. Otherwise, the value of SIPP can be expected to diminish, the number of users is likely to drop, and support for continuing SIPP as an ongoing survey is likely to decline. Researchers’ use of SIPP was highly varied, using a mixture of the various modules within SIPP, and often used complex modeling. As a
result, producing a dataset consisting of a limited set of key variables would not meet the needs of most current SIPP users.
SIPP’s Current Level of Risk of Disclosure Remains Undetermined
Key to developing disclosure limitation strategies is to fully understand and measure the risk of disclosure. The actual risk of disclosure in SIPP data products has long been relatively unknown. The panel commends the Census Bureau on recently conducting a re-identification study to measure the likelihood that a data intruder could identify survey respondents by matching data in the SIPP public-use file with data contained in income tax data and Social Security records. The results were largely encouraging; some strata had no confirmed links at all, and overall less than 3 percent of putative links were confirmed as being correct (i.e., most putative links would be false positives). However, some strata had rates between 10 and 25 percent. Age was the measure that was most disclosive, though geography was used as a stratification variable rather than as a linking variable, so its impact relative to age cannot be measured. The study concluded there were no vulnerabilities requiring an immediate change to disclosure avoidance strategy.
The panel found the re-identification study to be highly informative but insufficient to properly evaluate the disclosure risks present in the public-use file. The report itself was very straightforward in acknowledging its limitations, and the research literature has developed many sophisticated methodologies for re-identification and other privacy attacks, making it difficult to draw confident conclusions from experiments with just one approach. For example, the report did not provide adequate information on how the presence of measures of changes over time affected the risk of disclosure, or of how looking at households rather than individuals might present a risk. The study was also too limited in examining what external databases (and consequently what types of data) might be used to identify survey respondents.
The Tools Available for Disclosure Avoidance
A variety of tools are available to support disclosure avoidance, and these might broadly be classified as falling within two categories: changing the data in ways that would make the data safe from disclosure and changing access to the data to prevent improper use. These two types of approaches can be used alone or in combination.
Box S-2 summarizes the ways in which data can be adjusted to protect confidentiality.
Currently the Census Bureau’s options are limited in the sense that there are no off-the-shelf tools for developing either a fully synthetic data file or a differentially private data file. It would be viable to synthesize selected
variables or to produce a table generator that restricts what tables can be produced and that adds noise to produce differentially private output, but the large number of variables and the presence of multiple observations over time both are complicating factors that could not be addressed at a full-file level in a reasonable amount of time.
A different approach is to change access to the data. Multiple tiers of access can be created, with each tier potentially varying in terms of what data are available, how the data can be analyzed, and what data can be publicly released (or even removed from the premises). SIPP currently offers the following tiers. First, SIPP offers a public-use file, in which some data have been removed or altered. Second, SIPP offers access through Federal Statistical Research Data Centers (FSRDCs), which offer potentially complete access to the data without alteration or suppression but require an approval process to get access and to have results publicly released; this
currently is offered both at selected physical facilities and through online access, with the same approval process and fees required for both ways. Third, SIPP offers access to synthetic data (which requires a more limited approval process), providing access to only a small subset of SIPP data plus selected administrative data, all synthesized. Other types of access used by federal agencies include a restricted-use file (provided on CD or by download, with restrictions on how the data may be stored, analyzed, and reported) and secure online data access (SODA), in which data users have online access to the data, with restrictions placed on the analysis and reporting of the data.
Maintaining Usability While Protecting Confidentiality
Full usability is achievable by releasing all of the original data, and full confidentiality is achievable by suppressing all of the data. The difficulty is in finding an appropriate balance between the two. The panel developed several conclusions to guide this process.
Current SIPP users tend to make use of a wide number of modules within the SIPP questionnaire, and they tend to engage in complex analyses, both in the way they manipulate the data and in the statistical procedures they choose. For this reason, neither providing a set of standardized tables nor providing a table generator is likely to meet all their needs, although such tools might increase the number of users, especially given the difficulty of working with SIPP data. Similarly, releasing only selected modules would not meet their needs.
Current SIPP users also frequently rely on the public-use file, so eliminating the public-use file as a way of protecting confidentiality may result in a substantial loss of SIPP users. In particular, current users find the FSRDC process to be highly onerous and would want a mid-tier mode of access to the extent that a public-use file cannot meet all their needs.
SIPP data users need more information about how SIPP data are altered so that they can analyze the data appropriately. Additionally, to make the best choice, they need information about the implications for analysis of choosing each of the available tiers of access.
At the present time, the Census Bureau has not conducted a formal assessment of the tradeoff between usability and privacy protection for SIPP.
RECOMMENDATIONS
Using a Public-Use File and Intermediate Tiers to Facilitate Access
The Census Bureau should continue to produce a public-use file to satisfy the needs of those wishing to perform complex analyses. To the
extent that data cannot be included in the public-use file, the Census Bureau should look for an intermediate tier of access that is less onerous than FSRDCs (Recommendation 5-1).
The use of measures of geography, including state identifiers, is a highly important function because policy researchers have used differences across states in state policies as a tool for measuring the impact of those policies (Recommendation 8-1). However, because of the capacity of geography to divide the sample and the U.S. population into relatively small groups, it presents likely disclosure risks. For some types of situations, researchers may only need to distinguish between states without necessarily being able to identify them, while other types of research will require precise identification of the states. This divergence of research needs is well suited to offering multiple tiers of access, allowing some types of analysis to be performed on the public-use file, while others will require more secure forms of access.
Strengthening Current Approaches to Measuring the Risk of Disclosure
Current information about disclosure risks is still too incomplete to make a proper judgment about the safety of the current public-use file. Contingent on the findings from future re-identification studies, it seems likely that some variables (including demographic and geography variables) may need to be given statistical disclosure treatment, such as by collapsing to fewer categories, synthesizing, or developing alternative means of access to the variables or their analytical use (Recommendation 4-1); these approaches are discussed in the following section. A regularized process of re-identification studies to evaluate disclosure risks is needed, including several types of analysis not yet specifically addressed by the Census Bureau (Recommendation 3-1). These include considering the use of additional variables for matching, such as home values and education levels; examining the clustering of characteristics across multiple individuals within a household; examining alternative thresholds for identifying putative links; and testing for changes over time. The Census Bureau would benefit from involving experts from the research community in the design of more creative attack strategies tailored to SIPP data (Recommendation 3-3).
Choosing Among the Tools Available for Disclosure Avoidance
The panel recommends continuing to release a public-use file that is as large as possible while protecting confidentiality (Recommendation 9-3), while also creating new tiers of access as a way of providing access to variables that are dropped altogether in the public-use file or to original variables that were recoded in the public-use data to protect confidentiality (Recommendation 9-4). Data users’ needs will vary depending on the
particular analysis that is planned and the variables that are involved; for example, some users may be satisfied with a categorical version of age (perhaps as long as detailed ages are available for determining program eligibility) and others will need more detailed data, while converting state to geographic region would hinder many analyses. The current FSRDC approval process and financial costs are too onerous even with online access now being permitted, and an intermediate solution can be provided for those situations in which the public-use file is not sufficient. Chapter 5 suggests the creation of SODA, which would (a) provide more data than in the public-use file but less than in FSRDCs; (b) have less restrictive procedures than FSRDCs for obtaining access, analyzing the data, and obtaining permission for public release of the findings; and (c) provide a quicker and simpler process for disclosure review of findings for public release. A SODA would function by creating a controlled environment for data access and especially data release, and by requiring signed user agreements to gain access. A key is that to maintain high usability, a SODA should be readily available, with a simple and short application process that can be processed in a timely manner. The Census Bureau will also need an appropriate infrastructure for supporting multiple users of SODA, which may require hiring an outside contractor. (The panel takes no position on whether it is better for the Census Bureau to provide the infrastructure internally or hire an outside contractor. It notes that there are contractors who already have such an infrastructure in place, and that the Census Bureau might find their experience useful in determining the best approaches, and that hiring an outside contractor might require less set-up work on the part of the Census Bureau.)
In the short term, the Census Bureau might also consider augmenting public-use files with synthetic versions of variables that are deemed to be disclosive. These synthetic variables may be created using prediction modeling that is designed to emulate the statistical properties of the original data. Using a set of statistical models, the statistical estimates from the synthetic and original datasets may be compared to assess the usability of augmented public-use files. Current technology can handle a limited set of variables to be synthesized, though considerable research will be needed to assess usability.
A long-term ideal might be a fully synthetic, differentially private public-use data file, but this does not seem realistic in the near term (given current tools for data synthesis and differential privacy) and may prove to be impossible. Research is advancing rapidly, so it is difficult to know what tools may become available in the near future. The Census Bureau should continue to support research on disclosure avoidance and should work actively with both an advisory group and external researchers in developing appropriate tools and strategies (Recommendations 3-3 and 10-2). The external researchers might include both privacy protection specialists and SIPP data users.
An important consideration in creating synthetic versions of the variables is the assessment of inferential validity (Recommendation 6-2). This can be assessed by investigating the sampling properties of the analytical results that use synthesized variables and comparing them with the results using the original variables. This can be routinized using several candidate analyses from the literature or a set of analyses developed in consultation with the subject matter experts.
Table generators, or more generally, Remote Analysis Platforms (RAPs), can provide a method of data access with a built-in differential privacy framework. Depending on the interagency agreements that the Census Bureau has with other federal agencies, the table generators might include synthetic versions of linked administrative data. Here the users should be able to submit queries or analysis requests remotely using the SIPP metadata (e.g., codebook) and noise-infused results that are calibrated to be consistent with the results from the actual data could be sent back to the users. In the short term, this framework may be more useful to new users or for preparing research proposals than for the complex analyses often performed by SIPP data users. A fully functional RAP with the ability to perform complex analysis may take longer to develop. The Census Bureau’s previous experience with a SIPP table generator was abandoned as being too difficult to maintain; the Census Bureau might consider hiring an outside contractor for such work. This decision might depend on the extent to which the Census Bureau is willing to dedicate its own resources to such a project and on whether contractors might have systems in place that could be adapted to meet data users’ needs with minimal development effort. Table generators can be designed to infuse noise and to limit the production of data involving very few respondents in a cell, so per-user disclosure review may be unnecessary.
Steps That Will Help in Balancing Usability and Confidentiality
Particularly to the extent that new disclosure avoidance procedures are adopted, greatly enhanced communication would be beneficial. Data users need better documentation and tools to properly make use of the data (Recommendation 10-1). The Census Bureau should release information about its actions to protect data, balancing the need to keep some information protected or secret from potential intruders with the ability for users to work with the data properly.
In particular, data users need to understand
- the current risks to confidentiality so they recognize the need for a change in tiers of access;
- how to estimate the impact of data synthesis and noise infusion on the validity and accuracy of statistical estimates (Recommendation 9-1);
- when and how to have their results validated against the Gold Standard File; and
- how to choose which tier of access is most appropriate.
Communications with data users should be in both directions, not only providing tools and documentation for users but learning from data users about their needs and experiences.
A key aspect to protecting confidentiality while enhancing usability is the creation of additional tiers of access. A remote table generator could do this in a limited way, though it would not meet the full needs of current SIPP data users. The provision of SODA would provide a more complete tool for allowing customized analysis of the complete (or relatively complete) data file.
One of the hindrances to usability is the current interpretation of Title 13. It may not be necessary to change that interpretation in order to provide SODA, since the move would still be toward increased protection of confidentiality as compared with the public-use file. Still, a modernization of the interpretation of Title 13 is desirable, both for SODA and for FSRDCs (Recommendation 9-5). Some of the current barriers are the requirements to show a benefit to the Census Bureau, produce a complete research proposal, and go through an extensive background check. None of these barriers is specifically required by Title 13, while more recent legislation assigns the goals of supporting evidence and multiple tiers of access. Census Bureau Policies DS002 and DS006 could be updated to reflect the changing requirement without changing Title 13 itself.
TIMELINE FOR MAKING CHANGES
SIPP data are too valuable to stop data releases while new approaches are being developed. For this reason, the panel recommends a graduated approach in which relatively simple changes are made in the short term while research continues on developing longer-range solutions. The use of a graduated approach will also help users to adjust to the changes being implemented in SIPP. The recommendations here may also be difficult for the Census Bureau to implement on its own with its current resources. This may be a time to involve outside organizations for tasks such as maintaining SODA and assisting with the disclosure review process for publishing data. The Census Bureau could also benefit by including external researchers when performing re-identification studies and developing disclosure avoidance strategies, bringing in additional skills and perspectives to supplement the work of Census Bureau staff.
Given that it will take time to implement the recommendations in this report, and that more extensive analyses may reveal undesirable levels of
disclosure risk, the Census Bureau may wish to consider short-term steps to lessen the risk of disclosure. One approach would be to strengthen traditional statistical disclosure limitation methods like more coarsening of the data, additional top-codes, additional geography suppression, and similar methods. The re-identification exercise suggests that age might pose the greatest threats, and the panel’s analysis indicates that state identifiers also present risk, so these measures in particular could be considered as high priorities for disclosure avoidance steps. However, these increased protections come at the cost of reduced data utility, and any adoption of increased statistical disclosure limitation methods should seek to minimize the loss of that utility. Another option that has been adopted in a number of European countries is a registration process for those who download the public-use file, requiring users to provide identifying information and state the intended purpose of the data analysis. Alternatively (or in addition), users of public-use SIPP files could be required to sign a user agreement that required them to agree to specific uses of the data and to not disclose any data that could reasonably be regarded as confidential (the National Center for Education Statistics has adopted a variant of this procedure). While these options would not block a serious and sophisticated intruder from obtaining the data and attempting reidentification, they will make the general user community aware of these issues and sensitive to the problem.
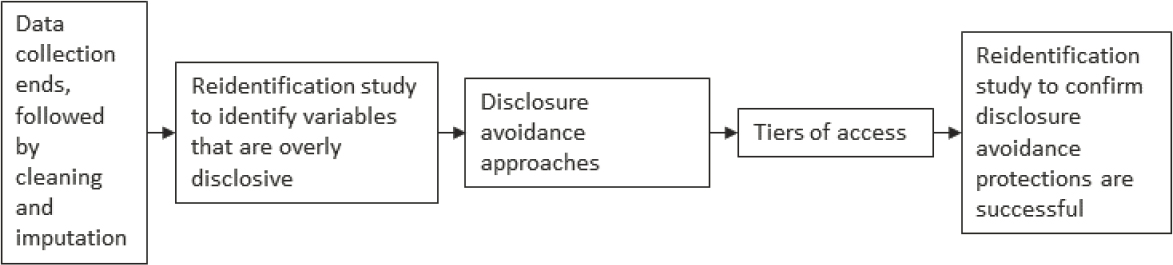
Figures S-1a and S-1b display how these various options compare in terms of the tradeoff between ease of access and the availability of complete data. Ideally, once the raw data are finalized, a re-identification study is performed to estimate the level of disclosure risks. After the disclosure risks are known, a variety of approaches are possible, depending on the level of risk and the planned tier of access. These range from traditional statistical disclosure limitations, such as those currently used by SIPP, to synthetic data (also used by SIPP for a small extract of the file combined with administrative data) and differential privacy (recently adopted for the 2020 decennial census). The four tiers of access are arranged in order of accessibility.
A table generator would be the easiest for users to access in the sense that it requires only internet access, not computer programming skills or software, but at the cost of offering the least information and with noise added to the data. A public-use file requires greater statistical and programming skills (SIPP file structure is complex), but it can be downloaded by anyone, it allows data users to customize their analysis, and it makes more data available. SODA places more restrictions on the user, such as signed user agreements and disclosure reviews of what data may be released, but it makes even more data available. FSRDCs tend to be difficult to access, with substantial user fees, background checks, and specific demands on the uses
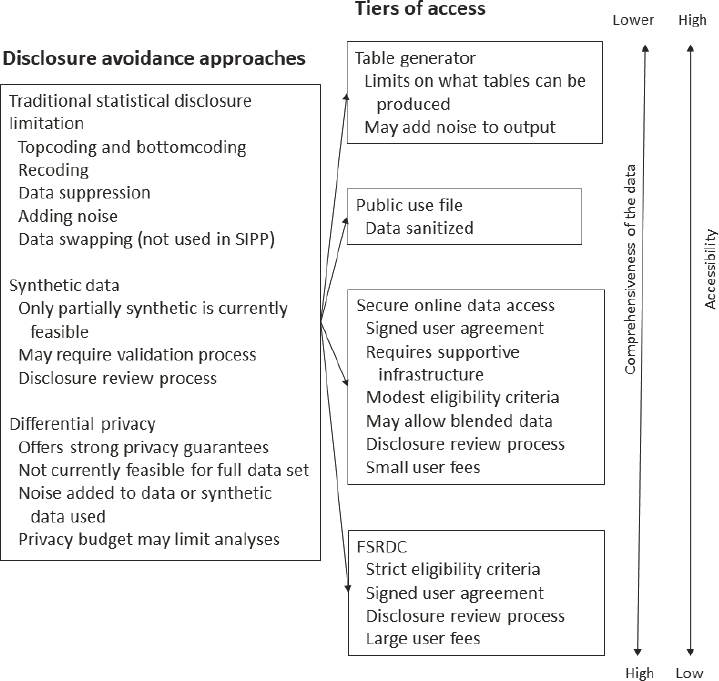
of the data; however, the original data can become available at FSRDCs and the data can potentially be blended with other sources.
While the various data disclosure approaches conceptually could be applied at any of the tiers of access, methods of changing or suppressing the data are most applicable to a table generator or public-use file, while the additional controls placed by SODA are intended to allow more complete access to the original data. However, one might still use synthetic data at an FSRDC, not necessarily to protect SIPP data but rather to allow the merging of other data, possibly to protect the other data or possibly to allow the blending of data that are not directly matchable. Differential privacy, as a tool for controlling what data are output or released, could be used at any of the tiers.
Following the design of the tiers of access, a final step is to use re-identification studies and other empirical tests of privacy attacks to confirm that the disclosure risks have been resolved appropriately without creating new risks.
This page intentionally left blank.













