Statistical Analysis of Massive Data Streams: Proceedings of a Workshop (2004)
Chapter: 8. RULE CHAINS AND ASSOCIATED DATA STRUCTURES

Figure 5. The rule engine can be viewed as an in-line agent that performs the work of merging, analyzing, and splitting streams. The output streams of a rule engine use the same NME structure, which enables the creation of a fabric of chained stream processors.
produce aggregates of particular attributes. At the end of the aggregation time interval the aggregates are flushed either to a persistent store for recovery operations, or the aggregates can be fed directly to a following Collector for further processing (or both). (3) Certain rules allow a real time query of current results. This is particularly valuable to gain insight into ongoing statistics. For example, examining the current empirical distribution of a variable. This kind of functionality is enabled with DNA discussed later on.
8. RULE CHAINS AND ASSOCIATED DATA STRUCTURES
A rule chain is sequence of configured operations on the flowing NMEs of an input stream. Example rules include standard three-address arithmetic and logical operators of the form op(a1, a2, a3) where the first two parameters represent NME attributes as operands, and the third attribute is the result. Flow control rules include conditionals (e.g., if…then…else) that can change the path of the rules based on the NME attributes, but no looping rules—not a good idea in a stream! In addition we have developed a rich set of lookup rules, filter rules, adornment rules, and other special rules for more complex operations. The rules are written in Java and there is a developer’s kit that enables users to create their own rules. However, the current rule library is extensive with more than 100 rules, which is satisfactory for most applications.
The right side of Figure 6 illustrates a simple rule chain on the left with a single if…then…else rule followed by some sequential operations.
Although the processing logic applied to an NME as it flows through is contained in the rule, there is also a reference to a data structure that travels with the NME and can also be changed by the action of the rule logic. This data structure can hold state information that can interact with subsequent NMEs traveling through the Rule Engine and can be flushed to a datastore at regular intervals. This parallel data structure is usually organized as a tree shown on the right.
Hash rules are an example of the special rules that operate on the references to the data tree. Each node of a level of the tree associated with a Hash rule can contain a hash table (Cormen, Leiserson, and Rivest 1999; Knuth 1973) where the entries contain a key and a pointer to a child node. A hash rule is configured to use an attribute of the NME as a key and then either chooses the successor data node based on the result of the hash if it exists, or create one if it does not exist. Each data node can be an n-way branch (a binary tree
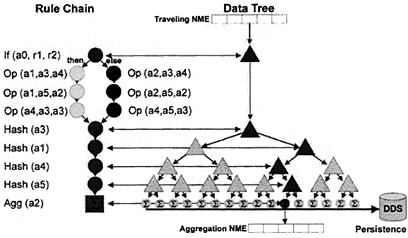
Figure 6. A simplified view of how rule chains can interact with dynamic data structures. A single rule engine can have multiple of these rule chains in various series and parallel configurations.
structure is used in the diagram for graphical simplicity). New nodes of the tree get created as new values appear in the data. If the last rule in the chain is configured as an aggregation rule, and the Collector is configured to flush the leaf nodes flushed at periodic intervals, the resulting dataset would be the same as an SQL aggregating group-by operation except the grouping (essentially routing) occurs as the NMEs flow, not as a batch operation. The following table contrasts the stream processor rules that produce the same operation as the batch SQL statement on the right.
|
Stream Processor Rules |
Batch SQL Statement |
|
(in a specific rule chain context) |
Select SrcIP, DstIP, sum(usage) |
|
Hash SrcIP, DstIP; |
From <table> |
|
Aggregate sum(usage); |
Group By SrcIP, DstIP |
Because there can be multiple rule chains, as explained earlier, the specific rule chain where the hash rules appear is analogous to the “From <table>” clause in SQL. However, in a stream processing context we have the opportunity to perform operations that would be much more cumbersome in an SQL environment. This will be further discussed in Section 9.3
An n-level hash in this structure is analogous to a hyper-cube in the sense that the leaf nodes of the tree can be mapped to coordinates of an n-dimensional hyper-cube. However, there are differences. One is that the tree structure can be sparse in that nodes are created only when the combination of data actually exists in the input stream. Another difference is that the cell of a hyper-cube usually contains only one value. In this data structure the nodes are containers that can contain their own complex data structures internally.

