2020 Census Data Products: Demographic and Housing Characteristics File: Proceedings of a Workshop (2023)
Chapter: 3 Overview of Disclosure Avoidance and Census Data Products
3
Overview of Disclosure Avoidance and Census Data Products
TOPDOWN ALGORITHM
Michael Hawes (U.S. Census Bureau) explained that the Census Bureau’s new disclosure avoidance system initiative is intended to produce high-quality Demographic and Housing Characteristics (DHC) files for the 2020 Census while protecting the confidentiality of respondents. Hawes and other subject matter experts from the demographic, decennial, and research and methodology program areas would be listening carefully to the presentations and looking for opportunities to adjust the algorithm’s parameters to address fitness-for-use deficiencies and privacy concerns that may be raised. He emphasized that the purpose of the workshop for the Census Bureau was to provide an indication of how it could turn feedback into tangible improvements for the DHC File.
Conducting a high-quality census hinges on the voluntary participation of the American public, and securing that participation requires that the public trust the government to properly safeguard their data. Hawes stated that the Census Bureau has a long history of employing techniques to mitigate the risk of disclosure in the published data and has no discretion when adhering to Title 13 U.S.C. § 8(b) and 9(a) under the U.S. Supreme Court’s decision in Baldridge v. Shapiro, 455 U.S. 345 (1982):
To stimulate public cooperation necessary for an accurate census . . . Congress has provided assurances that information furnished by individuals is to be treated as confidential. Title 13 U.S.C. § 8(b) and § 9(a) explicitly provide for nondisclosure of certain census data, and no discretion is provided to the Census Bureau on whether or not to disclose such data.
These safeguards—known as disclosure limitation or, within the Census Bureau, as disclosure avoidance—have evolved at the Census Bureau over the decades in different forms. For example, suppression was used in the 1970 and 1980 censuses, where table cells or even entire tables were redacted if they did not meet certain underlying population-size thresholds set by the Census Bureau. This practice of suppression resulted in a large amount of missing data for lower-level geographies (e.g., counties, tracts, block groups) and smaller populations in what Hawes characterized as the Swiss Cheese Effect. This suppression had an obvious, negative impact on numerous important uses of census data.
In 1990, injecting noise into some census tabulations was introduced through a process called record swapping. For the 2000 and 2010 Census data products, this record swapping was enhanced to cover more demographic characteristics across the full suite of published census tabulations. Hawes noted that, unlike its predecessor, the impact of swapping on census data was largely opaque to data users, both because there were no longer obvious holes in the data and because the effectiveness of swapping as a noise-injection safeguard depended, at least in part, on the public being unaware of the swapping algorithm’s magnitude or scope.
Hawes explained that statistical agencies are faced with similar threats as those found in information technology security, as well as hacking threats, so agencies have to contend with a constantly changing environment in which existing threats increase continually. Hawes asserted,
Two of the most vexing evolving threats come from the explosion of third-party data sources that could be used as part of an attack on published statistical data and the ever-increasing power of computers and optimization algorithms that can leverage those external data sources in such an attack.
Reconstruction Attack
Hawes explained that, to assess the effectiveness of prior decades of disclosure avoidance methods, the Census Bureau simulated its own attack using four commercially available data sets from the 2010 time period to create a lower-bound analysis (although higher-quality data were available in 2010). The simulated attack starts with running published tabular summaries, or data tables, through a system of equations that essentially converts those tabular data into individual census records without individuals’ names on them. Next, pseudo-identifiers, such as location, age, and sex, can be used to link those reconstructed individual-level records to an external data source that does include individuals’ names. The final result is a linked microdata file with the names of the individuals and their confidential census information.
Hawes pointed out a potential attacker has an immense amount of data available to attempt reconstruction. For example, the 2010 Census published more than 150 billion statistics across an extensive range of data tables. The reconstruction attack used a small subset of tables mostly at the block level, where data are vulnerable and disclosure risk is often greatest. The following variables were used for this simulation:
- P001 (Total Population by Block);
- P006 (Total Races Tallied by Block);
- P007 (Hispanic or Latino Origin by Race by Block);
- P009 (Hispanic or Latino, and Not Hispanic or Latino by Race by Block);
- P011 (Hispanic or Latino, and Not Hispanic or Latino by Race for the Population 18 Years and Over by Block);
- P012 (Sex by Age by Block);
- P012A-I (Sex by Age by Block, iterated by Race);
- P014 (Sex by Single-year-of-age for the Population under 20 Years by Block); and
- PCT012A-N (Sex by Single-year-of-age by Tract, iterated by Race).
Hawes characterized the results from the simulated attack as “alarming.” From the small subset of published tables, the Census Bureau was able to reconstruct individual-level records for the entire country that closely matched the underlying confidential data of the Census Edited File (CEF). Specifically, 91.8 percent of these reconstructed records were an exact match with the CEF on location, sex, exact and binned age, race, and ethnicity. When the simulation was conducted using the disclosure avoidance system run for the March 2022 demonstration data products, the match rate dropped to 33.1 percent. The full paper covering this simulation is available from the March Census Science Advisory Committee,1 and Hawes stated that a technical paper will be released later this year that provides the full specifications and results of the simulated attack.
Disclosure avoidance practitioners have long been concerned with individuals who are noticeably different from their neighbors. These are called population uniques because their records are easy to distinguish from those of their neighbors, thus making it easier to reidentify them in a re-identification attack. Hawes displayed results of their simulated attack at re-identifying population uniques in the published 2010 Census data using the 2010 swapping approach. The precision rate is the percentage of possible re-identifications that were correct. When this precision rate was
___________________
1 https://www2.census.gov/about/partners/cac/sac/meetings/2022-03/presentation-reconstruction-and-reidentification-of-the-dhc.pdf
estimated for re-identification of population uniques for nonmodal races—or a race different from the majority of their neighbors—the precision rate was 89.2 percent. Consequently, attackers with these matches would have high confidence that they correctly reidentified those people.
Implementation of Differentially Privatized Data
Given this knowledge of disclosure risks, Hawes explained, the Census Bureau decided to enhance its methods of noise injection for the 2020 Census by moving away from the swapping mechanism used in the past and adopting a new approach based on the mathematical framework known as differential privacy. This approach allows for the quantification of disclosure risk and confidentiality protection in ways that prior methods do not. Every statistic derived from a confidential data source will “leak” (or reveal) a tiny amount of confidential data in the process. The differential privacy framework can assess and thus limit how much information about an individual will leak into the statistic that is published.
There is no single way to implement differential privacy because it is an accounting system used to measure and track disclosure risk across all releases. As a result, the Census Bureau has employed a variety of differential privacy algorithms to protect the different data products that comprise the 2020 Census. Hawes focused on the TopDown Algorithm (TDA), which was used for the 2020 Public Law 94-171 redistricting data file, as it is the basis for the 2020 Census demographic profiles as well as the DHC File.
Hawes outlined the TDA’s five-step process, which is described more fully in a paper by Abowd et al. (2022). First, the TDA inputs the confidential microdata from the CEF with the Tabulation Geographic Reference (Tab GRF-C) file. Second, it converts those individual-level records into a functionally equivalent histogram. The third step is to take an extensive series of measurements, or tabulations, of that histogram with confidential data and add noise—small amounts of error—to each one of the results of those tabulations. The fourth step is to postprocess those resulting noisy measurements so that they are internally and hierarchically consistent, with all nonnegative integers. The final step is to convert the resulting histogram back into microdata that can be fed into the decennial census tabulation systems.
The TDA incorporates any corresponding invariants and constraints, Hawes continued. As the name suggests, TDA is done in a top-down fashion, starting at the level of the entire United States and moving sequentially down each geographic level of the hierarchy until it reaches the individual census-block level. At each level, the results and totals from the geographic level above are added to the set of constraints for the postprocessing of the next geographic level down.
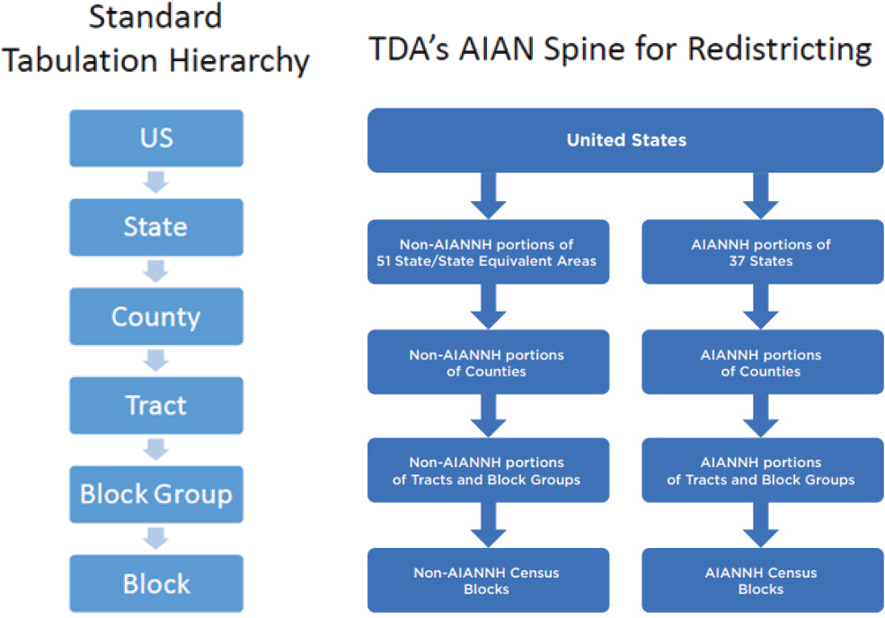
However, as Hawes shared in Figure 3-1, the geographic hierarchy used by the TDA differs from the Census Bureau’s standard tabulation hierarchy, which goes from the United States to state, county, tract, block group, and finally block. In earlier assessments of the TDA, the Census Bureau found, in the context of producing the redistricting data, that the overall accuracy of the data could be improved without any loss of privacy by modifying the algorithm’s hierarchy to bring some of the off-spine geographical entities onto or closer to the processing hierarchy. The modification of the algorithm’s hierarchy was done for the redistricting data by separating American Indian and Alaska Native (AIAN) tribal areas from their states and reconfiguring the algorithm’s definition of block groups to bring minor civil divisions, places, and AIAN areas closer to the spine. These “Optimized Block Groups” are used exclusively in the TDA.
Primitive Geographies
Hawes said that the Census Bureau has been researching and assessing additional changes to the TDA’s geographic hierarchy to incorporate the
NOTE: AIAN = American Indian and Alaska Native; AIANNH = American Indian, Alaska Native, and Native Hawaiian; TDA = TopDown Algorithm.
SOURCE: Michael Hawes workshop presentation, June 21, 2022.
Population Estimates’ primitive geographies onto the spine and thereby into the DHC File. Primitive geographies are the most granular geographic areas that are required in order to derive tables for every geography for which official population estimates are produced. Together they form a complete and mutually exclusive partition of the United States. Underneath primitive geographies are tract subsets at the intersection of the primitive geographies with census tabulation tracts, defined as the union of multiple tract subsets that are all within the same primitive geography. The Census Bureau is currently researching and evaluating potential changes to the TDA’s geographic hierarchy in response to feedback received, including possibly bringing school districts closer to the spine as part of the optimization.
Housing File Coding Error
Hawes conveyed that a coding error was discovered prior to the workshop for the housing file for the March 2022 demonstration data. This error in the DHC-H (housing) configuration file—introduced as part of the Census Bureau’s rapid-cycle, experimental tuning runs—inadvertently reversed the order of the privacy-loss budget allocations by geographic level. Hawes provided an overview of the impact of this error: generally, the U.S.- and state-level tabulations in the demonstration product were significantly less accurate than intended, while county-level tabulations were slightly more accurate than intended. Tabulations for incorporated places were comparable, but tract-level tabulations in the demonstration product were slightly less accurate than intended.
The Census Bureau does not plan to reissue a corrected version of the March demonstration data product, Hawes said, but the detailed summary metrics will be released as an informational tool. For tabulations above the block level that were released with greater accuracy than intended, Hawes stated the Census Bureau commits to maintaining (or improving) that level of accuracy in the second DHC demonstration data product and in the 2020 Census DHC production run, consistent with ongoing confidentiality assessments. The next round of the demonstration data will reflect improvements based on extensive internal analysis and feedback provided to the Census Bureau, including external uses cases from this workshop.
Notwithstanding this error, Hawes stated that releasing demonstration data helps the Census Bureau’s internal subject matter experts to set accuracy targets and evaluate parameter settings of the TDA for the next demonstration product and for the final production run of the 2020 Census DHC File. Adjustments to the TDA that could occur based on this workshop (in addition to other feedback received by the Census Bureau) include geographic hierarchy, noisy measurement query structure, allocation of the overall privacy-loss budget by query or geography level, and
overall privacy-loss budget allocation to the DHC-P (persons) or DHC-H (housing) files.
Discussion
Co-chair Joe Hotz served as the discussant for this session before opening it to floor discussion. He stated that his comments drew upon published work (JASON, 2020, 2022; boyd and Sarathy, 2022; Hotz and Salvo, 2022; Hotz et al., 2022). Hotz emphasized the importance of recognizing the improvements that the Census Bureau has made since the first workshop and that some of his comments were based on the use cases from the 2019 workshop. The improved accuracy was noted by the second JASON report (2022). Hotz discussed the change from the TDA based on pure differential privacy with the Laplace mechanism to zero-concentrated differential privacy with the Gaussian mechanism. Another change was the optimized geographic spine that brought such entities as school districts closer to the spine in response to prior input to the Census Bureau. In addition, handling of postprocessing constraints was better. These advances were important refinements, and they clearly improved the accuracy. Further investigation would be valuable in looking forward to 2030.
Referring to the fourth step in the TDA’s development described by Hawes, Hotz discussed remaining issues associated with postprocessing. Differential privacy stops at noisy measurements, and Hotz argued that imposing these postprocessing constraints were a demanding part of the algorithm. Hotz stated that, although the Census Bureau has made advances, it should explore over the coming years how to be public and transparent about better approaches to this postprocessing step. He explained that it is crucial to understand the extent to which postprocessing provides uncertainty or measurement error in the data in tabulations.
Understanding sources of uncertainty is important because a gold standard does not exist. Comparing these sources of uncertainty to the margins of error in a survey (which could be due to sampling error), Hotz said these are essentially nonsampling errors in the Census. A hallmark of differential privacy is that the source of error is quantifiable. Consequently, Hotz made a plea to release the noisy measurements or an approximation of them, so others can assess and better understand that part of the process. He noted that this request has been made in certain communities, especially in computer science.
It is also imperative to improve communication and identify ways to address misconceptions. Drawing on the peer-review process that journals employ, Hotz urged that now is the time to start addressing some of these misconceptions, which requires releasing more information. Although it is important to know what the disclosure avoidance system is and what it
does, there is a lot of misunderstanding about it, and Hotz asserted that there has been a lot of “talking past one another.”
The last critique Hotz raised was about the difference between absolute disclosure risk and relative disclosure risk. He offered an analogy between considering a potential intruder and considering mortality risks from diseases and health conditions. Individuals, he argued, may worry a lot about absolute risk of dying if they are not in good health, even if there is a small relative risk of dying. Comparing the risk of dying to privacy loss due to a data release, Hotz argued that individuals in a confidential data set may not be bothered by even large relative increases in disclosure risk if the probability of disclosure risk is low. He extended this analysis by positing that differential privacy mechanisms address worst-case scenarios when there are serious challenges to quantifying what information potential intruders may know (Gong and Meng, 2020).
When the floor was opened for discussion, Hawes provided clarifications about the TDA for some of the issues raised by Hotz. Hawes stated that the final stage of the algorithm with the microdata step absolutely has consequences that are not ignorable, which is one of the reasons the Census Bureau has adopted different algorithms for the Detailed DHC (DDHC) and possibly special tabulations down the road. With respect to the coding error and its impact on precision, Hawes noted that it was too early to speculate because the coding error was only detected the prior week. He indicated that the Census Bureau is still doing experimental tuning based on the feedback at the workshop and the feedback received from the analyses of data that were published. Tom Mueller (University of Oklahoma) asked whether the DHC coding error impacted the person-level files or just the housing characteristics file. Hawes clarified that the coding error was related to the housing file exclusively and did not impact the person file.
Planning committee member Mary Craigle (Montana Department of Commerce) stated that data users welcome partnership, but asked how they can better translate their cases for the Census Bureau. Hawes replied that the conversations with the State Data Center (SDC) and Census Information Center (CIC) networks have been valuable. He clarified that the most important feedback is that which is actionable in terms of accuracy targets. He also acknowledged that while everybody would like the data they rely on most heavily to be perfectly accurate, it is not possible. The question on the amount of error injected as a privacy-preserving step is not easy to answer because it is a policy question. Hawes continued by saying that feedback would be most useful if data use cases were framed as “the data would still be useable and valuable if” and then an error measure was selected—e.g., mean absolute error, mean algebraic percent error—as being less than or equal to this amount at this level of geography. User statements such as these (that once the error exceeds a certain threshold they will look for other sources
of data) are actionable feedback for the Census Bureau to make definitive changes to the privacy-loss budget allocations to meet those targets.
Hawes asserted that users are uncomfortable with and unaccustomed to jockeying with each other about use cases. However, all disclosure methods impact different use cases in different ways, and these decisions have always been made, they just have not been made in view of the data users. So while it has been a challenge to get usable information from these discussions, it is better to have that input when making decisions that will impact one case over another than to have them made behind closed doors without data users being aware.
Mays raised the Biden administration’s direction to work on the issue of data disaggregation, especially for Asians and Pacific Islanders. She asked how the Census Bureau will be able to able to meet this requirement. Roberto Ramirez (U.S. Census Bureau) replied that while the focus for the workshop was the DHC File, a number of products will follow the DHC File, including the DDHC-A. This file will include more than 300 detailed ethnicities and nationalities and more than 1,200 detailed AIAN tribes and villages. It is planned to be released in the summer of 2023.
Doug Geverdt (National Center for Education Statistics) asked about the discretion of setting the value of epsilon. Hawes replied that this is the “$60 million question” for all disclosure avoidance practitioners; the confidentiality laws are typically written in very black-and-white terms, and data are either identifiable or they are not. In reality, practitioners have known since the 1970s that any publication is going to carry some level of disclosure risk. As a result, it is incumbent upon statistical agencies to decide how much risk is acceptable and to evaluate this risk. There is no fundamental way to eliminate all risk of disclosure. It is about mitigating that risk to what is considered acceptable given the anticipated threats to the confidentiality.
Webinar attendee Gwynne Evans-Lomayesva (University of Pennsylvania) inquired about the impacts on off-spine geographies for the DHC File and what the Census Bureau is doing to ensure their usability. She stated she was specifically interested in the American Indian, Alaska Native, and Native Hawaiian Home Lands data. She asked whether there is a level at which data for those geographies will be suppressed or whether there is a target for accuracy in these areas. Hawes replied that the Census Bureau is looking at accuracy targets for the AIAN and Native Hawaiian areas that will be included in the detailed summary metrics. He continued that it has the AIAN branch of the hierarchy that is preserved for the DHC file with the intention of improving accuracy for those AIAN tribal areas, which are historically further from the spine than many of their counterparts.
Webinar attendee Joe Salvo (University of Virginia Biocomplexity Institute) acknowledged that the Census Bureau has communicated that the data products from the 2020 Census enumeration need to be subject
to differential privacy, and he has since learned that statistics about census operations also have a cost when it comes to the privacy-loss budget. He requested an example to illustrate why statistics about the process of taking the census also need to be subject to disclosure avoidance. Hawes explained that the key aspect is whether the operations data include information that is considered a response variable from the census itself. Examples include imputation, knowing where records are coming from (geography), or knowing response rates within a particular area. Anything that is considered a response variable does need to be governed by the 2020 disclosure avoidance system in one way or another. The disclosure avoidance system as applied to operations data would carry over to operations metrics if the Census Bureau includes those response variables.
TURNING FEEDBACK INTO ACTION
Jason Devine (U.S. Census Bureau) stated that the Census Bureau has been working on implementing differential privacy ever since the first workshop almost three years ago. It is important that the data remain useful while providing protected data to the public. Devine stated the Census Bureau has been working to collect and incorporate feedback in its efforts, but it is “an extremely complex effort and major shift in how census data are protected.” Similarly, communicating and collecting feedback has been challenging; this workshop is an example of these efforts along with census advisory groups, the Federal-State Cooperative for Population Estimates (FSCPE), and SDCs.
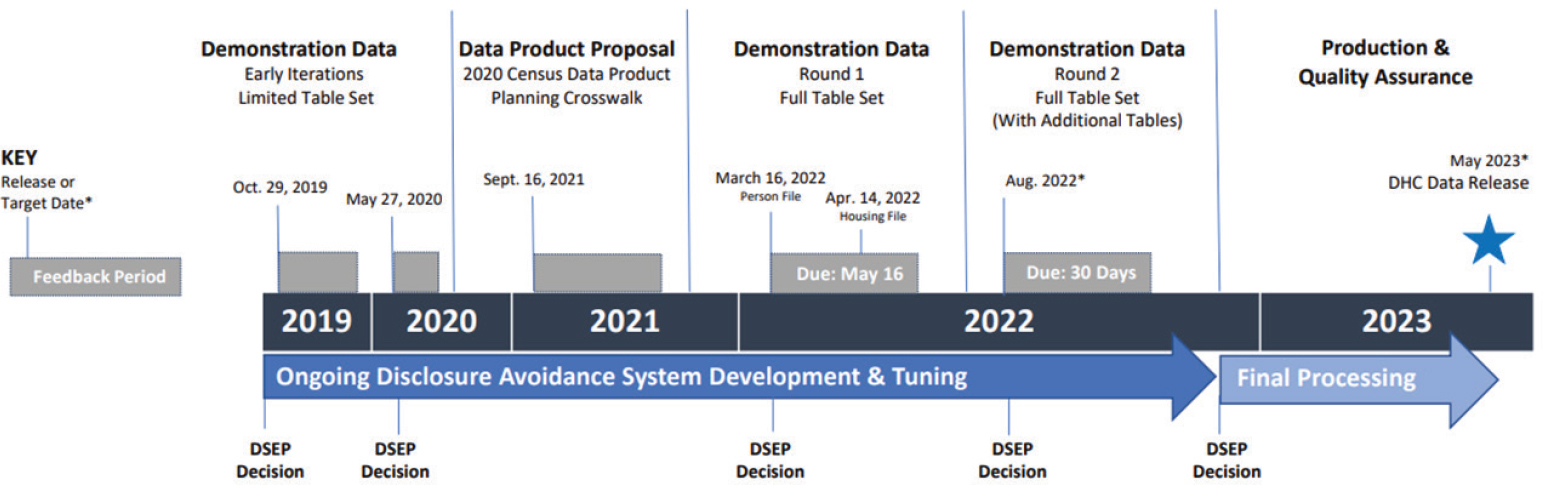
Figure 3-2 shows the Census Bureau’s progress in its efforts to release 2020 Census data products. The current stage of this process—following the apportionment and redistricting data released in 2021—is focused on the DHC and DDHC Files. The DHC File is planned to be released in May 2023, followed by the DDHC in August 2023. Additionally, Devine stated that the Census Bureau will soon increase its efforts to determine what it can do for a public use microdata series (PUMS) file and how its special tabulations program will look.
The DHC File was previously referred to as the Census Summary File 1, or SF1, with many tables provided at the block level. It includes tabulations and cross-tabulations of people by age, sex, Hispanic origin, relationship to the householder, counts of households, counts of housing by tenure and vacancy status, and counts of people living in group quarters. Characteristics that will be provided with the DDHC File but not the DHC File include counts of people by detailed race and ethnicity, and AIAN tribes and villages. Another forthcoming product is the supplemental DHC, in which the person and household joins will enable counts of people by household.
The current stage is Round 1 of the demonstration data that have been released; the Census Bureau will summarize the feedback it received and
NOTE: DSEP = Data Stewardship Executive Policy Committee.
SOURCE: Jason Devine workshop presentation, June 21, 2022.
provide it in a forthcoming report. All of this feedback will be used to set the final parameters for the census data products with more information available in the blog “2020 Census Data Products: Next Steps for Data Releases.”2 The last comment period ended May 16, 2022, and there are plans to release a second round of demonstration data for comment in August 20223 that will reflect close-to-final settings.
The Census Bureau conducted outreach through workshops, webinars, blogs, newsletters, and presentations; it also produced a Differential Privacy Handbook4 (referred to later in Jill Kaneff’s presentation). Feedback in response to the initial Federal Register notice—more than 400 comments, many of which involved use cases—helped inform the initial design of the DHC File. Based on this feedback, some tables were added back into the DHC File, and no tables were removed. Most of these comments raised concerns about accuracy of data by age and sex, with a specific concern for the accuracy of counts of children.
Devine noted that—despite concerns from data users regarding the release of redistricting data and accuracy of census counts, as well as the perception that the accuracy was from the disclosure avoidance system—so far the concerns brought to the Census Bureau were determined not to be connected with the application of disclosure avoidance, once they were investigated internally. The feedback on redistricting demonstration data led to a substantial amount of additional privacy-loss budget for that product. Concerns raised about lower accuracy of data for tribal geographies and other off-spine geographies, such as places of minor civil divisions, led to changes to what is considered the optimized spine.
U.S. Census Bureau Assessment of Feedback
Devine provided examples of how the Census Bureau has been successful in listening to feedback and seeking opportunities for improvement. First, the allocation of additional privacy-loss budget and the infusion of greater block-level noise led to improvements in the disclosure avoidance system that resulted in substantial increases in accuracy from the first demonstration product released in 2019. The Census Bureau held six successive comment periods that benefited from improved understanding of the new disclosure avoidance system methodology by both Census staff and data users. The Census Bureau has also held multiple workshops and webinars
___________________
2 https://www.census.gov/newsroom/blogs/random-samplings/2022/04/2020-census-data-products-next-steps.html
3 The new demonstration data were released on August 22, 2022.
4 https://www2.census.gov/library/publications/decennial/2020/2020-census-disclosure-avoidance-handbook.pdf
and participated in conferences to help inform stakeholders. The aforementioned summary of these comments to be released soon is another example of its outreach efforts.
Despite these efforts, Devine stated that more feedback is needed. The demonstration products have been difficult to use. The Census Bureau needed to split the files into unit (housing) and person files; then an error caused a need for rerelease of the unit file. It has been difficult to integrate the use cases into acceptable levels of accuracy for the DHC File. The Census Bureau has also expected data users to accept inconsistencies within the data without enough explanation of why they are there and why they cannot be eliminated. Devine stated the Census Bureau will listen to and use the presentations at the workshop to help inform its decisions for the files scheduled for release in August 2022; the Data Stewardship Executive Policy Committee will then make the final production settings for the disclosure avoidance system to conclude with the May 2023 release of the DHC product.
Discussion
Co-chair Elizabeth Garner commented that Devine’s focus on central tendencies means losing out on the tails, and it is important to remember that these outliers, or tails, are not cells in a spreadsheet: they are people in communities. She implored the Census Bureau to shift its attention to the tails of the distribution to understand who the “winners and losers” are. Those tails are smaller communities that “tend to lack resources to analyze the data and come up with fixes.” The lack of resources (in smaller communities) impacts the equity of how differential privacy is applied and who it affects. Garner asked the Census Bureau to consider the communities from whom they are not receiving use cases—who are likely to be smaller, under resourced entities—especially given Devine’s acknowledgment of the complexity and difficulty of using the DHC demonstration data. Garner concluded by noting that the decennial data are the only source of data on blocks for small-area analysis so they do not have a back-up source of data.
Devine acknowledged the concern about outliers and replied that they reflect real places and that some of them were reeled in by reducing the number of outliers as the Census Bureau continued its work. Devine commented on blocks by noting that the data at the block level is where it is most disclosive, and that a decision was made with the redistricting product that led to more accuracy for those geographies above the tract level. He underscored that not producing block data for any of the tables to obtain the accuracy necessary for the higher levels of geography may be a very real prospect going forward. Devine concluded by noting that, from this demonstration product and feedback received, the Census Bureau is not far off from being able to provide data that are both protected and acceptably accurate.
Craigle mentioned that it was a challenge to complete analysis for use cases during the time frame provided. She asked for clarification whether feedback is still being considered. Devine confirmed that this feedback could be included in the second round of demonstration data that will be released in the same format, and he speculated, “Once users have done their analysis once, maybe it will easier and faster the second time around.”
STATUS UPDATE ON POPULATION ESTIMATES
Christine Hartley (U.S. Census Bureau) provided an overview of the Population Estimates Program (PEP) with regard to its use of decennial census data and compliance with the Census Bureau’s disclosure avoidance policies. Hartley opened her presentation by stating that the PEP is a major customer of the decennial census data. She explained that the PEP disseminates official measures of population and housing units between decennial censuses, and it is a legal mandate by Congress per Title 13 § 181. These official measures are the official estimates of housing and population for the Census Bureau and are used to allocate federal funds, develop weights for demographic surveys, produce key statistical indicators, and facilitate planning at state and local levels.
Each year a time series of estimates is constructed that starts at the date of the last decennial and extends through the “vintage year,” which represents the latest year of estimates available. The latest estimates are for July 1, 2021, and include estimates for more than 80,000 areas in the United States and Puerto Rico for a variety of geographic levels down to cities and towns (municipios for Puerto Rico) with varying demographic detail. Typically, the decennial census is used as the base population to build estimates for the nation, states, and counties using the cohort-component method, while cities and towns use the distributive housing-unit method.
Under normal conditions, Hartley explained, the PEP would use the decennial census for its estimates base along with inputs from administrative records. Proportions from the census are used to assign race and Hispanic origin to birth data using the Kidlink file that matches children ages zero to their parents by household. In another process key to estimates production, the demographic characteristics file—a compilation of administrative and census data—is used to assign race and Hispanic origin to individuals in the domestic migration universe.
Hartley explained that the PEP had some challenges for the development of its vintage 2021 estimates. Delayed by the COVID-19 pandemic, only limited 2020 Census data were available. The alternative was to model one more year of change relative to the 2010 Census and essentially tack one more year onto the vintage 2020 time series, which extends from 2010 to 2020. However, there was information from the 2020 decennial Census
that the 2020 vintage estimates were a little lower; consequently, Hartley stated this would have significantly limited the utility of vintage 2021 data.
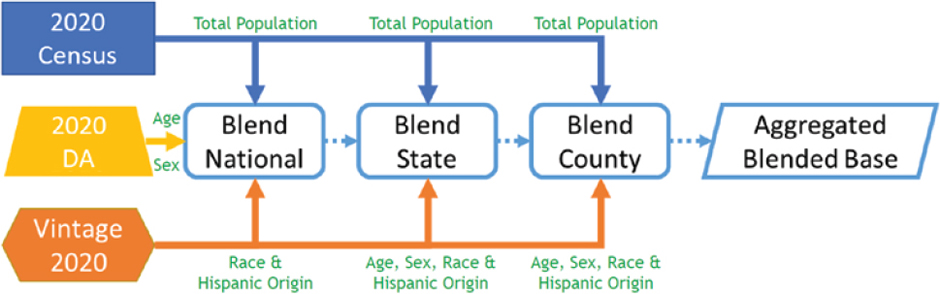
Blended Base Approach
The alternative developed is the blended base approach depicted in Figure 3-3. Hartley explained that this blended base combines the vintage 2020 with the 2020 Census total population for counties from the Public Law 94-171 redistricting file and the national 2020 demographic analysis estimates by age and sex for April 1, 2020, using an alternative administrative records methodology. A major benefit of the blended base is that it can continue to be used as long as needed and improved upon for each series of estimates. Hartley stated that current work includes incorporating more data from the 2020 Census, including group quarters and household population at the county level and demographic analysis up to 100 years old and above. Hartley also mentioned the following caveat: looking ahead to vintage 2023 and beyond, it is important to acknowledge that the blended base was intended as a temporary solution and not a permanent methodological shift.
Hartley pointed out the importance of ensuring that 2020 Census data quality and disclosure avoidance adhere to agency guidelines to protect confidentiality. The Census Bureau has established the Base Evaluation and Research Team (BERT) to research the feasibility of taking coverage measures into account in the development of population estimates. The BERT team includes subject matter experts in the following areas:
- population estimates;
- age and sex statistics;
- coverage measurement;
- race and ethnicity;
- demography; and
- disclosure avoidance.
With respect to infusing differential privacy noise, the Census Bureau is seeking a solution specifically for the county level and above. Existing options include using the microdata detail file, which already features noise, or the CEF, which does not have noise infused, and then applying the differential privacy mechanism into the data for the estimates program. The microdata detail file would not draw upon additional privacy-loss budget, but the file lacks some key variables needed for estimates processing. Alternatively, using the CEF would require development of a differential privacy mechanism to infuse noise into a very detailed tabulation of census data that would need to be done annually, although with this base the estimates methodology could otherwise run normally without changes.
NOTE: DA = demographic analysis.
SOURCE: Christine Hartley workshop presentation, June 21, 2022.
Discussion
Garner, serving as the moderator and discussant for Hartley’s presentation, acknowledged the level of work that has gone into the estimates, especially developing the blended base approach. Garner encouraged the Census Bureau to look beyond its internal teams, such as BERT, and also look outside, perhaps to the FSCPE and be open to evaluation. Garner opined that some folks may be happier with the blended base than results from the 2020 Census. This could be more pronounced in smaller areas with populations under 1,000, where, Garner said, “We have seen differential privacy make large effects.” Moreover, the reason that differential privacy has to be applied each year has not been explained well, even to the Census Bureau’s tighter user groups, such as the FSCPE. For example, Garner asked what kind of re-identification studies have been done and what their results are.
Hartley responded that the scope and complexity of topics for the public is understood and the Census Bureau is appreciative of the insight from the FSCPE for identifying gaps. She also confirmed that developing a differential privacy mechanism to use the CEF in the base would mean that every year there would be different noise, which would be another challenge if that is the direction taken.
Craigle also expressed concern to Hartley that as the PEP becomes more complex, it is more challenging to find partners with the quantitative skills to review it. Hartley noted that the Census Bureau is looking for any opportunity to bring in partners for more review. She also stated that the Census Bureau is continuing to seek partnerships and welcomes feedback and more communication.















