Creating an Integrated System of Data and Statistics on Household Income, Consumption, and Wealth: Time to Build (2024)
Chapter: 6 Governance, Legal, and Privacy Issues
6
Governance, Legal, and Privacy Issues
This report has proposed the development of statistical and data products to support a better understanding of income, consumption, and wealth (ICW), one that rests on linking multiple sources of restricted microdata. The use of blended data raises a number of governance issues and legal and privacy concerns, which are especially complex due to the desire for both a standard suite of published statistics disaggregated by person and household characteristics and access for researchers to conduct additional analyses. The privacy concerns are heightened because meeting the panel’s objectives will require the integration of many sources of sensitive financial and demographic information, over time, for the same individuals.
This chapter discusses the governance, legal, and privacy issues related to the construction and use of ICW data. The chapter first described issues associated with building the ICW data infrastructure, including access to the potential input datasets described in Chapter 5, and desirable linkages with their corresponding privacy risks. Next, the issues associated with data user access to ICW products are described, noting that a tiered access approach will be necessary. Finally, a potential governance model is described, including a possible roadmap for creating and releasing the new statistical and data products.
Before delving into these issues, there are four assumptions regarding ICW data and product development that should be considered.
- The ICW data will be used in statistical activities with a statistical purpose, with the deep involvement of statistical agencies. Statistical activity means “the collection, compilation, processing, or
- analysis of data for the purpose of describing or making estimates concerning the whole, or relevant groups […] within the economy […]” Statistical purpose means “the description, estimation, or analysis of the characteristics of groups, without identifying the individuals or organizations that comprise such groups [… Statistical purposes include] the development, implementation, or maintenance of […] information resources that support these purposes” (Office of Management and Budget, 2014, p. 2). As described in Chapter 3, the panel envisions that statistical agencies will use the ICW infrastructure to produce statistical estimates. As described in Chapter 5, the panel proposes that new blended data sets be created for use by both government analysts and academic researchers to better understand the distribution of ICW and its response to policy changes.
- Whether they are at the high or low end of the income and wealth distributions, the privacy and confidentiality of all data subjects is paramount. This ethical principle arose out of the Belmont report (National Institutes of Health, 1979) and the Common Rule1 and aligns with the Principles and Practices for a Federal Statistical Agency (National Academies of Sciences, Engineering, and Medicine, 2021; see also National Academies, 2023b). It will guide the development of the ICW infrastructure. Methods for protecting individuals’ privacy will include privacy-preserving record linkages, using hashed data and enabling sharing, and linkage of data files between agencies without release of personally identifiable information. Match parameters and results for ICW linkages will be reviewed to assess bias and error, in line with Recommendation 5.8 of the Advisory Committee on Data for Evidence Building Year 2 Report (Advisory Committee on Data for Evidence Building, 2022).
- The unit of analysis for the ICW data infrastructure will be the household. Much of the available data on income and wealth, however, is collected for individuals within households. However, when aggregating individuals to households, rosters from census, survey, or tax data may not agree (see Larrimore et al., 2022), so assumptions may be required.
- As recommended in Chapter 5 (see Box 5-3), a coordinating entity will be created to resolve administrative, legal, and technical challenges. Specifically, this will be needed to resolve challenges to the integration of data from multiple federal entities, as well as from private businesses that collect microdata on individuals and households. It will also be needed to codify agreements and protocols
___________________
1See Code of Federal Regulations, 45 C.F.R. 46.
- that enable data acquisition, integration, exchange, and access; to support the publication of privacy-protected statistics; and to coordinate pilot projects.
The panel also recommends the adoption of the Five Safes framework to guide decisions and protocols for access to the ICW data. The Five Safes framework was originally developed by Felix Ritchie in a discussion of the operations of the United Kingdom’s Office of National Statistics’ Virtual Microdata Laboratory (see Ritchie, 2008). He proposed that when implementing data governance models and access pathways, consideration be given to ensure (1) Safe Data, (2) Safe Projects, (3) Safe People, (4) Safe Settings, and (5) Safe Output (see Box 6-1).
POTENTIAL DATA SOURCES: LEGAL AND PRIVACY ISSUES
Chapter 5 proposed multiple approaches to obtain data needed to build the ICW infrastructure: using currently open data; collecting new panel data from a sample of households; and linking existing datasets from government agencies and private-sector sources.
The first approach—combining publicly available data sources—poses no new privacy concerns. These data are already in the public domain and, at least with regard to data released by the federal statistical agencies, measures such as rounding, suppression, top-coding, modeling, binning, and noise injection that are intended to prevent the disclosure of individual-level information have already been applied. For this approach, linkages between publicly available datasets would occur through modeling, imputation, and statistical matching. While the panel identified this as a possible approach, the panel also questions whether public-use files will continue to be available in the future. The federal statistical agencies are increasingly concerned about the potential re-identification of data subjects in household surveys for which individual-level records are released.
Privacy concerns for the second approach—launching a new panel—revolve around the linkage of administrative data to the survey responses for panel participants. Any such linkages would require the informed consent of survey participants. Starting with an address-based sample, gathering information through a survey instrument, and then using linkages to administrative and private-sector data, this approach would build in privacy by design.
There are significant legal and privacy issues surrounding the approach of combining restricted data sources, but this also is the most robust approach to generating the desired ICW summary statistics and restricted access microdata files. Population-level data linkages have the potential to produce the most geographically and demographically disaggregated
BOX 6-1

SOURCES: Federal Committee on Statistical Methodology (2022) Data Protection Toolkit: Report and Resources on Statistical Disclosure Limitation Methodology and Tiered Data Access, rev. 2022.01.
The Five Safes framework offers a guide to the interaction of users with ICW products. Chapter 3 in this report described the panel’s expectation that, at a minimum, there would be publicly available ICW summary statistics and restricted-access ICW research microdata. These products have very different risk and utility profiles and require a tiered access approach, meaning that different access criteria will exist for open data compared to highly sensitive person-level data.
Publicly available summary statistics could be published on an ICW website, available for download. They may include experimental statistics that make use of different data sources or different definitions in addition to the estimates the statistical agencies choose to feature, but all of these statistics would be aggregated and sufficiently privacy-protected before release. In contrast, restricted access to ICW linked microdata would require safe projects, people, settings, and outputs. A Federal Statistical Research Data Center (FSRDC) or other secure enclave could implement controls to reduce risks of unauthorized access, use, or disclosure of the underlying ICW data.
Some research suggests that the Five Safes Approach may not be sufficient (see Culnane & Rubinstein, 2023); however, the Advisory Committee on Data for Evidence Building Year 2 Report encourages use of the Five Safes framework in designing secure and privacy protecting data linkage projects. The Office of Management and Budget (OMB) references the framework in OMB Memorandum M-23-04 (Establishment of Standard Application Process Requirements on Recognized Statistical Agencies and Units) when describing the multiple dimensions of risk that must be considered when approving access to restricted government administrative data.
information. By blending data from multiple data sources, the ICW infrastructure could support the modeling of more accurate estimates and benchmarks. As shown in Figures 5-1A and 5-1B, the following data sources will be essential:
- Individual income tax and information returns (Internal Revenue Service)2
- Master Address File (MAF; Census Bureau)
- Master Address File – Auxiliary Reference File (MAF-ARF; Census Bureau)
- Title 13 race files (Census Bureau)
- Social Security numident and parent-child bridge files (Social Security Administration)
- Decennial Census program data (Census Bureau)
The Internal Revenue Service (IRS) individual income tax data (Form 1040 and associated Schedules) and information returns (e.g., Forms W-2 and 1099) are controlled by U.S.C. Title 26. Under the IRS’s tax administration authority, data may be used by IRS contractors or Intergovernmental Personnel Act appointees with an IRS coauthor for tax administration and tax policy purposes (Section 6103(n)) or for special studies conducted by IRS employees on a cost-reimbursable basis under its Special Project Authority (Section 6108(b)).
The IRS shares selected federal tax information from income tax returns and information returns with the Census Bureau under U.S.C. Title 26 Section 6103(j), which permits statistical analyses that advance the Census Bureau mission. The IRS, which provides explicit approval for each project using tax data, permits access to individual income tax or information returns only for Census Bureau-led projects. The panel heard reports on three such “internal” projects relevant to improving the understanding of ICW—the Comprehensive Income Dataset (CID) project, the Administrative Income Statistics project, and the National Experimental Wellbeing Statistics (NEWS) project. Continued research and development on ICW topics depends on Census Bureau leadership buy-in and staffing resources. In some cases, such as on the CID project, Census Bureau resources have been supplemented with external funds through a Joint Statistical Project.
The Treasury Office of Tax Analysis and the Joint Committee on Taxation can access IRS tax data to evaluate distributional issues under the authority that Title 26 provides in Section 6103(h)(1) or 6103(j)(3). The panel heard from Jeff Larrimore, David Splinter, and Jacob Mortenson (Larrimore
___________________
2Chapter 5 also mentions Form 5500 (Pension Plan Reporting).
et al., 2022) about their use of the tax data; these datasets, however, are currently available only to Treasury Department researchers.
In addition to the tax records, there are other data on earnings that would be useful to improve the accuracy of income estimates and distribution. Unemployment insurance (UI) wage records are included in the Longitudinal Employer-Household Dynamics program that have been linked with Census Bureau household surveys such as the Survey of Income and Program Participation (SIPP) and have been used in evaluating earnings distributions (as shown in Figure 1-2 in Chapter 1). Researchers at the Census Bureau and in academia have also used the Detailed Earnings Records of the Social Security Administration (SSA) to evaluate earnings in household surveys including the Annual Social and Economic Supplement to the Current Population Survey (CPS-ASEC) and SIPP. Both the UI wage records and the SSA Detailed Earnings Records are potentially valuable sources of information on earnings that, used in conjunction with the tax data captured by information returns and the Form 1040s, could help to improve distributional estimates. However, accessing these data sources would require obtaining approvals from additional actors for their use, such as from states for their UI wage record data and from SSA for the earnings records.
Chapter 5 noted that the NEWS project uses the Detailed Earnings Records from SSA to improve measures of earnings. These records are technically IRS data, governed under U.S.C. Title 26 and requiring IRS permission for research use. There is some overlap between the Detailed Earnings Records and the IRS 1040 data, which include Form W-2 records. The NEWS project demonstrates that earnings data can be improved by using all available information on earnings, including information from Form 1040s, Form W-2s, SSA earnings, and quarterly UI wage records from the Longitudinal Employer-Household Dynamics program (Bee et al., 2023).
Chapter 5 also noted three population-level administrative files maintained at the Census Bureau. The MAF is a list of all known addresses with unique identifiers for residential housing units as well as congregate/group quarters units. The MAF is compiled from U.S. Postal Service and local community data, with Census Bureau field work additions and verifications. The Master Address File–Auxiliary Reference File (MAF-ARF) is an index of person-place information, with records for each validated person matched to the Social Security Number (SSN) register and assigned a Protected Identification Key (PIK) located at a housing unit located in the MAF (and assigned an MAF ID). Multiple administrative data sources are
used to identify individuals’ residence locations.3 The MAF-ARF is viewed as a Census Bureau product, using the agency’s identifiers and not containing any indication of the source of the records used to assign any specific residence location. Finally, the decennial census is another Census Bureau product that the panel considers to be an administrative file because it is a register of U.S. residents for a point in time.
To use any of the Census Bureau datasets, a project must benefit the agency’s mission. The Census Bureau engages in Joint Statistical Projects under 13 U.S.C. 8(b) on a cost-reimbursable basis. It also permits unpaid researchers to use confidential Census Bureau data. These Special Sworn Employees can access restricted data under 13 U.S.C. 23(c), provided their work benefits the Census Bureau, is viable, has scientific merit, and will produce releasable results. To comply with 13 U.S.C. 9, the Census Bureau must maintain confidentiality for all the data it collects and procures. Disclosure avoidance experts at the agency review all projects before approval and all statistical outputs prior to public release. Some past research has found that disclosure avoidance protocols used for the decennial census may distort the blended data (Hotz et al., 2022).
Using data from the IRS, SSA, or the Census Bureau requires linkages at either the person level or the address level (or both) to intentionally append sensitive information. When these joins are made at the Census Bureau, they use PIKs (the persistent unique identifier that Census assigns to validated person records) and MAF identification numbers. As Brown (2022) discussed in his presentation to the panel, about 16% of people do not receive a PIK, and some addresses do not match the MAF (see Brown et al., 2023),4 such as in the examples of an international graduate student without an SSN or a person whose address is a P.O. Box. Flaxman (2022), in his presentation to the panel, also addressed the issues of nonmatching and link quality. The fact that there are errors in the linkage process may help with privacy concerns.
Chapters 4 and 5 discussed many additional administrative datasets, surveys, and commercial datasets that could contribute to creating an ICW data infrastructure, noting also that there may be legal and policy barriers to accessing or integrating these sources. As described in Chapter 5, federal
___________________
3The sources of information used to identify individuals’ residence are as follows: the Census Numident file, the Census Unedited File, the IRS 1040 and 1099 files, the Medicare Enrollment Database, the Indian Health Service database, Selective Service System, Public and Indian Housing, and Tenant Rental Assistance Certification System data from the Department of Housing and Urban Development, and National Change of Address data from the U.S. Postal Service (see Dillon, 2021).
household surveys that could contribute to the ICW data infrastructure include these:
- Survey of Consumer Finances (SCF)
- Consumer Expenditure Survey (CE)
- CPS-ASEC
- American Community Survey (ACS)
- SIPP
Various issues arise with blending these surveys with administrative data. Of these surveys, only the ACS is mandatory; all the others are voluntary. Each survey explains expected data uses to respondents and asks for their consent for linkage, giving them an opportunity to opt out of linkages. Consent rates are higher when an opt-out protocol is used (i.e., when respondents are asked to say whether they do not want their records linked) than when respondents are asked to provide affirmative consent. The CE has used an opt-out consent format in the past. However, recent survey linkages (including CE, CPS-ASEC and SIPP) to IRS tax records and a variety of administrative data sources have used a new method for T-13 surveys where the Census Bureau relies on the commitment to confidentiality and that the data will only be used for statistical purposes (Brummet et al., 2018; Hong et al., 2023). The CPS, CPS-ASEC, SIPP, and ACS have used an opt-out consent format and have been linked to administrative and commercial data sources; however, the Census Bureau has changed the opt-out method for these surveys. When the opt-out method is used, respondents who opt out are excluded from the person-validation processing and are not assigned PIKs for subsequent data linkages.
Currently, a variety of projects at the Census Bureau involve linking surveys, administrative data, and the decennial census. The Next Generation Data Platform is a joint project between the Economic Research Service of the U.S. Department of Agriculture and Census Bureau hosting state administrative linked to household surveys to analyze program eligibility and access. Data on benefits received through the Supplemental Nutrition Assistance Program and the Women, Infants, and Children program can be requested through an FSRDC. Linkages have been created between the CPS and the ACS with the earnings records from SSA (Meyer et al., 2023). The SIPP has been matched to the Detailed Earnings Records, Form 1040 records, program administrative data, and the Longitudinal Employer-Household Dynamics program data (see Fox et al., 2022; Meyer & Mittag, 2019). The NEWS project links to these data along with some commercial data (Bee et al., 2023).
These valuable projects face a variety of governance and sustainability problems. The data sharing agreements for administrative or commercial
data may have narrow or explicit uses that would need to be modified to allow the data to be used to build the ICW infrastructure the panel envisions. There are multiple decision makers involved across agencies and companies, often with conflicting aims or interpretations of contract language and regulations. When multiple surveys are involved, their administrators must consider how the risk of linkages and resultant studies may affect their respondents’ willingness to provide information. As work to create the ICW infrastructure proceeds, it will be important for these interests to be appropriately balanced and that a clear value proposition be provided for the planned statistics and restricted microdata.
In addition to the household surveys administered by federal statistical agencies, as discussed in Chapters 4 and 5, the ICW data infrastructure may benefit from using the data produced by federally sponsored household surveys conducted by nonfederal survey organizations. These include:
- Panel Survey of Income Dynamics (PSID)
- National Longitudinal Survey
- National Longitudinal Study of Adolescent to Adult Health
- Health and Retirement Study (HRS)
- National Mortgage Database
- Understanding America Study
Each of these surveys has been linked to administrative or commercial data. The way in which consent for linkage is obtained and linkages are performed is governed by the applicable institution’s Institutional Review Board. PSID and the HRS both use the University of Michigan Institutional Review Board for approval for linkages; however, they each have their own procedures for data access and are linked to different administrative data. Because it was too difficult or impossible to obtain consent from all respondents, many of whom had died by the time the linkage exercise was undertaken, both surveys are linked to 1940 census data without consent. This is an application of the Common Rule (National Institutes of Health, 2019), where risk-utility tradeoffs are considered in depth, sometimes permitting linkages and analyses without explicit consent. Similar interpretations of the Common Rule may allow linkages to other data sources, including commercial data from providers such as Zillow or with tightly controlled census data, especially if coupled with privacy enhancing technologies.
As discussed in Chapter 5, a number of federally sponsored blended data products have been produced and are housed at various statistical agencies:
- Decennial Census Digitization and Linkage Project
- Administrative Income Statistics
- NEWS
- Mobility, Opportunity, and Volatility Statistics (MOVS)
- CID
- Opportunity Insights
- Income Distributions and Dynamics in America (IDDA)
- Wealth and Mobility Study
These products rely on large-scale administrative data linkages, often with household survey integration. All of these are in-house Census Bureau projects, except the last project. Some of these include both internal and external researchers (e.g., CID, Opportunity Insights, and Income Distributions and Dynamics in America). The final project, the Wealth and Mobility Study, is an IRS Joint Statistical Research Program project. As with these projects, what the panel envisions for the ICW data infrastructure is a blending of data from many sources (see Box 6-2 for a “wish list” of possible variables).
In addition to the governmental data employed in the projects just mentioned, there are a variety of private-sector data sources that could make a valuable contribution to the ICW data infrastructure. Examples of such private-sector data and their sources:
- Financial transaction and banking data from JP Morgan Chase Institute, FirstData, and Mint.com
- Asset and credit bureau data from Equifax IXI and Experian
- Payment data from Apple Pay and PayPal
- Housing data from Black Knight, Zillow, and Corelogic
- Investment data from Addepar and Vanguard
- Business transactions data from Bizcomps and DealStats
A few of these data sources (e.g., Black Knight, Experian, Corelogic) have already been linked to Census Bureau data in the NEWS project and other Census Bureau projects.5 Contracts or licenses are needed to access data from these private companies. Some companies (e.g., Corelogic,
___________________
5For example, the following are ongoing Census FSRDC projects: Improving the Efficiency of Model-Informed Decision-making in Responsive and Adaptive Survey Designs (James Wagner, investigator) uses Experian header info; How Does the Mortgage Liability Affect Career Decision? Evidence of Cash Flow Hedging in Household Financial Planning (Wei Jiang, investigator) uses data from Corelogic; Neighborhood and Metropolitan Racial Differences in Rental Property Management (Eliz Corver Glenn, investigator) uses data from Corelogic; and The Urban Geography of Household Mortgages and Housing Returns (Jonathan Halket, investigator) uses data from Black Knight.
Experian) sell data extracts with personal identifiers. Alternatively, some companies, such as JP Morgan Chase, will only allow linkages to occur within their firewalls (Wheat, 2022). The conditions of use and linkage capabilities will need to be assessed during the initial phases of development of the ICW infrastructure. The information available from many of these sources reflects financial transactions involving consumption, saving, and investing, and debt for the client base of a particular firm, not the entire population. Nonetheless, narrow linkages with the data from cooperative companies may be valuable, even if those companies’ clients are not fully representative of the population as a whole. For example, credit card transactions from JP Morgan Chase will not be representative of all credit card transactions nor will they capture all expenditures, but they may contain valuable information about spending trends and the distribution of spending. In addition, the fact that some households are omitted from the dataset may help with privacy protection, essentially integrating sampling variability into the dataset.
DATA LINKAGES: GOVERNANCE AND PRIVACY ISSUES
As discussed in Chapter 5, linking administrative and commercial data with census and survey data will enable filling in missing information, improving accuracy, and assessing bias in the ICW infrastructure. The panel’s operating premise is that a coordinating entity for the ICW project will be needed to establish a governance model and identify technical solutions, such as Privacy Preserving Record Linkage, to guard against unauthorized access. Data linkage could rely on existing production systems within federal statistical agencies or on an honest broker or intermediary. The Coleridge Initiative acts as an intermediary for data linkages within and across states, often linking quarterly wage data to postsecondary and other state government program data. The Reigenstreif Institute acts as an honest broker for the National Center for Advancing Translation Sciences at the National Institutes of Health (NIH) to link patient data across 80 submitting institutions. Also at NIH, the All of Us program, as described to the panel by Dr. Abel Kho, links health records, survey data, administrative data, information from wearables, and genomic data, proving that privacy-preserving multi-sector joins of extremely sensitive data are possible (see presentation to panel, Kho, 2022).
Construction of the ICW infrastructure also may require data linkages between very small or experimental cohorts and the linked population-level administrative dataset. For example, if permission could be obtained from the data owners, Addepar or Equifax IXI data could be hashed for integration, and measures of wealth could be constructed based on wealth data from wealth management companies and banks. While coverage for
BOX 6-2
Other Variables That May Be Useful for ICW Data Infrastructure
Some variables may not be available in all datasets, such as those needed to obtain race and ethnicity, which are unavailable in some administrative datasets. Some variables may only be available in household surveys and therefore will be unavailable for all households in the ICW data. Some variables will be available in administrative records data at the Census Bureau, and some may be available for linkage to other data. Finally, some variables may only be available in commercial datasets or may be unavailable in any dataset.
Below is a list of some variables that may be useful to include in the ICW data infrastructure, which could be viewed as a potential “wish list.” It would be useful to have not only an indicator for the occurrence of these variables, but also the levels or dollar amounts. More research is needed to determine the available datasets and mechanisms for obtaining access to these variables, and the methods to use variables for ICW data and products.
- Credit card transactions
- Vehicle purchases
- Subsidized health care
- Subsidized housing
- Business scanner data
- Government transfers
- Employer benefits
- Transfer between households
- Alimony
- Child support paid and received
- Regular support to family members
- Remittances
- Lump sum cash transfers
- Cash gifts paid or received
- State agency program data
- Employer and employee pension contributions
- Interest and dividends on retirement accounts
- Pension income received and withdrawals
- Health insurance benefits
- Net imputed rent for homeowners
- House values
- Outstanding credit
- Debts paid or incurred on behalf of others
- Student debt
- College savings plans
- Inheritances and bequests
- Child support debt
- Prison-related debt
- Medical debt
- Legal debt
- Unrealized capital gains
- Mortgages
- Consumer debt
these small samples would be incomplete and not necessarily representative, testing individual-level joins could inform future expansions of the ICW infrastructure, perhaps involving a periodic set of linkages between an ICW cohort and multiple investment houses. Linkages to federal student aid data could also be especially valuable in this context.
Protecting Privacy of Linked Data
ICW data for individuals and households are sensitive, and layering on social and demographic data increases the sensitivity. Because they single out people or households with unique or outlying data points, the existence of atypical combinations of assets, debts, location, or personal attributes can make output privacy protection difficult. The need for stock and flow measures, indicating change over time, further complicate the privacy challenges for the release of ICW data. As discussed in the National Academies (2024) report on privacy, concerns arise at every step of the blending process. With the ICW data, privacy concerns are elevated using financial data blended with tax records, census records and commercial data (as described in Figure 5.1). Disclosure is not a “yes/no” concept but rather on a sliding scale. Every additional statistic computed from a confidential dataset leaks some amount of confidential information. Given enough statistics, the cumulative effect could result in a disclosure.
Privacy-utility tradeoffs must be considered before linking population-level datasets, as well as after the linkage when microdata extracts are prepared for research use. The aims for the ICW data infrastructure include having comprehensive coverage of both the top and bottom of the income and wealth distributions, demographic and geographic detail, reconciliation with published aggregates, and national representativeness, all of which will require careful planning.
There are numerous ways to protect privacy for linked data, and new methods are in development at the federal statistical agencies (IRS, Census Bureau, National Center for Health Statistics). Research from the National Secure Data Service demonstration project (NSDS-D) may inform the development of the ICW infrastructure, especially the research that will involve secure multiparty computation, privacy-protecting record linkage, and synthetic data.
As stated in the Year 2 report from the Advisory Committee on Data for Evidence Building (2022), disclosure risk is not binary but instead runs on a continuum, and not all data are equally sensitive. In the development of the ICW data infrastructure, binning or coarsening data can reduce the sensitivity and disclosiveness of some income or asset type information. As the above-cited Year 2 report notes, there is shared responsibility between
the statistical agencies and users for protecting data (Advisory Committee on Data for Evidence Building, 2022, p. 34). The panel agrees with the recent Committee on National Statistics (CNSTAT) report on privacy (National Academies, 2024, p. 43) that the “[…] framework for making decisions about acceptable disclosure risks given expected usefulness of data depends on whether that framework is dynamic,” and also with Conclusion 3.2 in that tiered access is a “[…] key component of key component of a dynamic disclosure risk/usefulness framework, to reflect differences in acceptable risks given policy priorities.”
Recommendation 6-1: In the initial phase of building the proposed income, consumption, and wealth infrastructure, the coordinating entity, in collaboration with relevant statistical agencies, should jointly develop a risk-utility framework and a combination of traditional disclosure limitation strategies and privacy-enhancing technologies to support the agencies’ publication of summary statistics of household income, consumption, and wealth.
ACCESS TO ICW PRODUCTS FOR DATA USERS
Building an ICW data infrastructure will involve many agencies and billions of records, but it should provide benefits to many groups. The deep investments made in infrastructure, governance, subject matter expertise, and oversight will generate summary statistics for public consumption and restricted microdata for rigorous research. The ICW coordinating entity can apply tiered access to ensure data protections that align with risk models. For example, annual benchmarks on consumption and wealth may be designed as downloadable modeled estimates, available as open data. Linked survey-administrative microdata could be made accessible through the FSRDC network for approved projects and qualified researchers. Currently, there are successful blended data projects that include both Census Bureau researchers and outside academic researchers (e.g., CID and IDDA). The goal for the coordinating entity would be to expand these blended data projects to more outside researchers. Integrated data from private-sector companies reflecting saving and dis-saving behavior may need to be partially synthesized before researchers with controlled access can use it. These tiers of varying access will optimize the availability of ICW data while protecting privacy. The ICW data infrastructure will need to have privacy built in by design, from the start.
The panel heard from speakers about several examples of data-access infrastructure. These included the protocols for accessing the data contained
in Abel Kho’s Capricorn project (Kho, 2022); NIH’s All of Us linkages;6 and Mary Ann Bates’ in-process data infrastructure, which will link data on California public school students from cradle to career (Bates, 2022). The Criminal Justice Administrative Record System illustrates how sensitive administrative data on arrest, convictions, incarceration, and probation can be integrated and matched to Census Bureau data to produce statistics—and how the resulting linked data can be made accessible for approved researchers through the FSRDC network.
Many governance issues will need to be resolved, of course, regarding matters such as the number of access tiers, types of privacy protections to be applied, and structures for making decisions about access. Focusing just on access to restricted microdata, the following questions (and more) will need to be resolved:
- Who decides what suitable project topics are?
- Who can access the data (e.g., will access be restricted to citizens?)
- Is virtual access permitted?
- Which statistical disclosure limitation methods will be used for estimates produced by researchers using the microdata (e.g., aggregation, noise infusion, suppression or some combination)?
- Who decides on privacy rules and parameters? With what input?
- How will equity in data access be monitored?
- How will measures of uncertainty in the data be conveyed to users?
Further issues to be addressed will be the adequacy of agency staffing for planning and research and the adequacy of agency computing infrastructure to prepare the ICW data for use. Following the SIPP report (National Academies, 2023d) and the Evidence Act, the panel agrees with tiered access.
Conclusion 6-1: Expanding access to the data infrastructure for household income, consumption, and wealth will require building a tiered access system that relies on open data (statistical series that are regularly published) and a set of public data products such as tables, public-use files, and/or synthetic data as well as restricted access to microdata for approved projects and users who work in secure enclaves, in Trusted Execution Environments, or using secure query servers.
Given the envisioned linkage of multiple sources of data, it is most likely that the fullest use of integrated household microdata on household
___________________
6See allofus.nih.gov
ICW will occur under the auspices of the FSRDC and the NSDS. Agencies can take advantage of these data enclaves, such as the FSRDC network, to share confidential blended data. As described in Garfinkel et al. (2023, p. 33), these data enclaves restrict “[…] the export of the original data and instead accepts queries from qualified researchers, runs the queries on the de-identified data, and responds with results.”
Given the likelihood that release of these data as a public-use file will not be feasible, it also would be valuable to explore the possibility of producing a synthetic dataset that could be made more widely available. The Census Bureau is currently evaluating the use of a synthetic data and validation process for the ACS,7 following its successful creation of the SIPP Synthetic Beta file. The Current CNSTAT Panel to Create a Roadmap for Disclosure Avoidance in the Survey of Income and Program Participation is also tasked with evaluating synthetic data approaches. Finally, the panel heard from McClelland (2022) about the IRS/Urban Institute project to develop a synthetic validation server for synthetic IRS data (see Bowen et al., 2022).
The data access ecosystem continues to evolve, with implementation of the Foundations of Evidence-Based Policymaking Act (known colloquially as the Evidence Act), forthcoming OMB data access regulations, and the NSDS-D at the National Science Foundation. NSDS-D was authorized under the CHIPS and Science Act, which was signed into law in August 2022. A report to the Congress on the NSDS-D is due in August 2024, and the demonstration project is slated to end in 2027. NSDS-D is advancing the recommendations and focus areas of the Commission for Evidence Based Policymaking (the Evidence Commission) and the Advisory Committee on Data for Evidence Building. The overarching goal of the demonstration project is to facilitate the use of federal data for evidence building. The project is intended to be a collection of services focusing on outreach, methodological solutions, technical solutions (like secure multiparty computing and privacy-protecting record linkage), and tiered access to data. Those responsible for setting up NSDS-D intend to foster a strong culture of data protection and to promote the linking of data, including data held by nonfederal entities.
The NSDS-D operates within the National Center for Science and Engineering Statistics at the National Science Foundation. During its demonstration period (2023–2027), the project is focused on innovation: novel research collaborations, data linkage methods, and privacy-enhancing technologies. It opened an Idea Box in Fall 2023, gathering topics and complex problems
___________________
7Details about the Census Bureau’s synthetic data projects are at www.census.gov/about/what/synthetic-data.html
for future rounds of research. One or more projects related to the development of the ICW data infrastructure would be well suited to be NSDS-D pilots. The NSDS pilot, America’s Datahub Consortium, is currently managing projects involving privacy-protecting record linkage, synthetic data, and other privacy-enhancing technologies, as well as environmental scans on secure environments and concierge services. It could solicit proposals related to standing up the coordinating entity and tackling the technical and privacy issues described in this report. As recommended in the Advisory Committee on Data for Evidence Building report, the NSDS also could be the locus of linkage work and an ICW demonstration project that illustrates the value of large-scale linkages could be proposed.
Recommendation 6.2: The coordinating entity, in collaboration with relevant statistical agencies, should propose options for a National Secure Data Service pilot to be created through which approved researchers would be allowed to access linked microdata consistent with standard definitions of income, consumption, and wealth through the National Secure Data Service.
DATA ACCESS REALITIES
For the envisioned ICW data infrastructure to be successfully created and used, legal and technical issues that cut across agencies must be identified and resolved. These issues loom especially large for Census Bureau and IRS data. These data are crucial inputs for the project, but currently individual tax data held by the IRS cannot be used in the FSRDC (per IRS Counsel), and Census Bureau MAF IDs, PIKs, and demographic characteristics cannot be shared with nonagency personnel.
The panel agrees with Recommendation 11-1 in the National Academies (2023c; p. 202) report on intergenerational poverty, that there should be “[…] a presumption of secure access to confidential data for research and policy evaluation, explicitly superseding provisions in U.S.C. Titles 26 and 13, which require research to benefit the IRS and the Census Bureau, respectively.” There may be scope for the staff of these agencies to broaden their interpretations of what is permitted under these titles, but changes in the law might be required. One possible path forward that might be more acceptable to lawyers and cybersecurity experts would be to limit access to modalities that provide greater privacy protections, such as trusted execution enclaves or secure multiparty computation models. This would mean a new way of working for many researchers, but it would go a long way toward broadening secure access to data. National Research Council (2007) also included Recommendation 12 on broadening the criteria for data access. Efforts are underway at both the Census Bureau and IRS to improve
data discoverability and access. The IRS is exploring methods to improve access to its data, such as releasing synthetic data with a validation server, as described by McClelland (2022). The Census Bureau is developing new products internally (e.g., NEWS) that will support outputs similar to those the panel has in mind for publicly available ICW summary statistics. Despite these efforts occurring at each of the two agencies, there is a need for progress on linkages between the agencies. In that spirit, NEWS is actively pursuing options to obtain additional information and variables from the IRS to improve the project’s ICW estimates.
As mentioned earlier, the panel would expect researcher data access to the ICW data infrastructure to occur through the FSRDC. The federal statistical agencies involved in the FSRDC network have made great strides in reducing the review time required for access to the FSRDC, providing virtual access to many projects, and providing metadata through the new Standard Application Process. The panel hopes that these efforts continue, with an eye toward tiered access methods that can improve access while enhancing privacy protection.
The IRS recently used the Standard Application Process to solicit project ideas for its Joint Statistical Research Program. Selected research projects will move forward within IRS infrastructure (not the FSRDC infrastructure), with an IRS employee embedded in each research team. This requirement limits the number of projects that can be approved each cycle, but it keeps the projects in line with their legal stance on using tax data.
Having an expert from the IRS, or from another data-owning agency such as the Census Bureau or the Federal Reserve, would benefit future projects. Agency staff involvement is crucial. In the short run, the development of ICW data could start with local solutions, where agencies identify sources for developing ICW data. Outside researchers or organizations then could seek access to the various data sources to conduct linkages, working with the agency staff on imputation, modeling, product development, weighting, and disclosure avoidance. In the longer run, the development of the ICW data infrastructure could shift to a federated system that links population-level datasets in situ (with no copies shared) to produce statistics and support ICW microdata building and validation services.
LEARNING FROM INTERNATIONAL PEERS
One common theme that emerged from the public presentations to the panel was that cooperation between data owners, data producers, federal agencies, and researchers is critical. The Organisation for Economic Cooperation and Development (OECD) presentations and all the national statistical office participants stressed that having all needed data available
under one umbrella organization is critical. Since the U.S. system is so fragmented, the panel believes that obtaining cooperation on creating the new standard estimates and new integrated data requires oversight.
As an example of the potential that data linkage holds, statistical agencies in other countries and academic researchers demonstrated the feasibility of using alternative data sources to replace aspects of the existing sample-based structure for price measurement. Lessons for the ICW project can be gleaned from the experience gained through these and other statistical data linkage projects (see also Norwood, 1995, who recommended creating one federal statistical agency).
Conclusion 6-2: The success in using multi-source data and data integration in other countries that operate with a single centralized statistical agency can provide guidance to improve the collaboration within and integration of the current U.S. statistical system.
Previous CNSTAT reports have recommended new data governance structures, greater cross-agency collaboration, and steering committees to facilitate that collaboration (see National Academies, 2017, 2022, 2023a,b). This interagency collaboration is also recommended in a recent Government Accountability Office (GAO) report to improve measurement of work arrangements (Government Accountability Office, 2023).
Data producers and users have been waiting since the passage of the Evidence Act for OMB to issue the regulations that will implement the Act’s key provisions regarding data access. The release of these regulations should accelerate the development and deployment of additional access tiers, enabling the dual goals for ICW data of regular production of summary statistics from joint distributions and restricted access to research microdata.
While the United States lacks a single statistical agency to prioritize ICW data goals, this country does have supportive leadership in the person of the Chief Statistician of the United States and at the NSDS-D. If the ICW data infrastructure project is to succeed, the Chief Statistician and NSDS-D leaders must affirm its value proposition, noting its utility for studies of economic mobility, antipoverty programs, and studies of equity. They also must ensure that agencies are resourced to provide tiered access so that ICW datasets will be accessible to user groups with varying needs. The panel believes that access should move beyond a binary view, that is, that data are either open or restricted. Through a tiered access framework, users can be contractually bound to terms and conditions about system use and disclosures.
Recommendation 6-3: The Office of Management and Budget’s Chief Statistician, in collaboration with the Interagency Council on Statistical Policy, should establish an income, consumption, and wealth technical steering committee that includes academic researchers, leadership from statistical agencies, and government researchers. The steering committee’s functions could include determining value propositions and risks; making recommendations about improvements to estimation methods; ensuring that the relevant statistical agencies cooperate to implement the panel’s recommended production of statistics; coordinating the release and communication of the new estimates; and working with the coordinating entity to develop an acquisition and collaboration system for sharing survey, commercial, and administrative data.
ROADMAP FOR MAKING PROGRESS ON ICW DATA AND PRODUCTS
Building an integrated system of data on ICW and producing coordinated and consistent estimates of the distributions of ICW require collaboration across the federal agencies, with the help of the Chief Statistician, NSDS leadership, and the Interagency Council on Statistical Policy. The panel believes that the best way forward is to create a coordinating entity that will oversee the data acquisition, linkage, and access (as in Recommendation 5-1) and collaborate with a new steering committee (as in Recommendation 6-3). The separate agencies will continue to produce their own estimates and collaborate on methods to improve estimates (as, for example, the Bureau of Economic Analysis (BEA) and the Bureau of Labor Statistics (BLS) are doing on the distribution of personal income and personal consumption expenditures). As they have done in the past, they also will continue to commission studies to evaluate specific data solutions and estimates (see National Academies, 2017, 2023a,b). The creation of the steering committee will also benefit from the three CNSTAT reports on the 21st century data infrastructure, and new plans to evaluate the NSDS and the NSDS-D pilot projects.8 Figure 6-1 highlights the roadmap activities and presents four phases—preliminary, initial, medium, and long-term.
One of the main projects to be undertaken during the preliminary phase and throughout the development and implementation of the panel’s recommendations is the improvement and expansion of the current distributional and blended data projects at the agencies, mainly Census, BEA, BLS, Statistics of Income, Board of Governors of the Federal Reserve Board, and
___________________
8The NSDS-D project is “required under the 2022 CHIPS and Science Act to inform a governmentwide effort on strengthening data linkage and data access infrastructure.” The NSDS concept was introduced by the Commission on Evidence-Based Policymaking in 2016 (Commission on Evidence-Based Policymaking, 2017).
Congressional Budget Office (CBO; as in Conclusion 3.1). The Census Bureau has already outlined the next steps for NEWS (see Rothbaum, 2022), including adding additional years and greater geographic coverage, expanding to a measure of after-tax-and-transfer income, investigating sources of measurement error such as that commonly found with self-employment income, refundable tax credits, and obtaining additional variables from the Statistics of Income/IRS files. The Federal Reserve has projects to expand the definition of wealth to include pension wealth (and even Social Security wealth see Jacobs et al., 2021). BLS has plans to expand its definition of consumption to include the value of time use, and BEA and BLS have initiated calculations of the joint distribution of personal income and personal consumption expenditures.
With these individual efforts and the creation of the new coordinating entity and steering committee, the panel created a roadmap for developing an integrated system and a consistent set of statistics on ICW (see Figure 6-1). The panel differentiates between what can be done at different stages by identifying tasks to undertake immediately in an initial phase, in a medium-term phase (up to 5 years out), and in a longer-term phase (beyond 5 years).
The initial phase (Phase 1, 1-3 years), highlighted in Recommendations 5-1, 5-2, and 5-4, involves identifying and evaluating the administrative, legal, and technical challenges to integrating household data from multiple federal entities and private businesses and expanding on current efforts to blend multiple datasets that have key components of ICW using the resources, models and methods that exist today. In particular, this initial phase will evaluate modeling and statistical matching methods to improve ICW estimates and the joint distributions of ICW as in Recommendation 5-4 and Conclusion 3-3. For example, the SCF Distributional Financial Accounts focusing on wealth could add income, and impute additional consumption, with BLS and BEA statistically matching CPS-ASEC and CE to obtain an improved income and consumption distributions, and using CE and SCF to obtain joint distributions of ICW.
As discussed in Chapter 5, the panel-recommended steering committee will work to establish pilot projects focusing on the following issues:
- expanding NEWS to include government in-kind transfer programs, health benefits, income taxes and refundable credits, and capital gains;
- building on efforts to measure spending in commercial data to improve consumer expenditure data in the CE;
- evaluating both data constructions in Figures 5-1A and 5-1B to compare the estimates of income and population characteristics, particularly those in the tails of the distributions; and
- comparing the consumption (or spending) estimates using the budget identity or actual estimates.
Some of these pilot studies could be conducted by agency researchers, others could be joint projects involving collaborations between agency and outside researchers who have access to data in the FSRDCs, or new Standard Application Process (SAP) for access to the restricted data, and finally, the last project could be initially conducted with publicly available data.
During this initial phase (as shown in Figure 6-1), the steering committee should work with both researchers and agencies to produce alternative measures of ICW that more closely represent those described in Chapters 2 and 3. This includes a measure of income from CBO with all capital gains, a measure of consumption that matches personal consumption expenditures, a measure of after-tax-and-transfer income using the blended survey and administrative data (à la NEWS), and a measure of wealth that includes pension wealth (see Jacobs et al., 2020; Sabelhaus & Volz, 2022). Measures can also build on current projects, such as the OECD adjusted disposable income measures produced by BEA. Initially, these new estimates could be included in the interactive CNSTAT webpage with the documentation and estimates of the varied sources identified in the report, and any changes, updates or comparison studies. This is to help build the ICW report (à la Recommendation 3-1).
Finally, agencies should be guided by this report (and U.S. and international standards) to finalize the appropriate and transparent definitional concepts of ICW and produce consistent estimates of the distributions of ICW, as in Conclusions 2-1, 2-4, 2-5, 2-6, 2-7, 3-1, and 3-3. With these definitions, agencies should initiate estimation of ICW statistics as in Recommendation 3-1, with an integrated first ICW report published within 3 years. The OECD efforts will also continue and expand the G20 Data gap initiatives.9 The broader research community and agency staff should be encouraged to work together of specific topics, including expanded access to the blended data through the SAP and FSRDCs. Agencies (mainly Census Bureau, BEA, and BLS) should continue to be involved in the OECD efforts to produce internationally comparable distribution of ICW statistics.
Further, agencies and researchers during this initial phase should investigate the surveys and blended data that contribute to the construction of joint distributions of ICW. Constructing a dataset with ICW is essential to evaluate not only the joint distributions, but also the impacts of income
___________________
9See www.imf.org/en/News/Seminars/Conferences/g20-data-gaps-initiative
changes on consumption and how wealth levels affect this relationship. Another key research area is the impact of retirement savings, and how spending (consumption) and saving (wealth) are impacted by retirement decisions. Finally, all macroeconomic questions concern the relationship between income and consumption both at a point in time and across periods of time, all in the context of the household’s wealth levels. This analysis requires a blended ICW dataset. By expanding on Fisher et al. (2022), much progress could be made improving methods to impute consumption estimates in the SCF. Efforts are also needed to examine the relationship between wealth accumulation and lifetime earnings (see Jacobs et al., 2021) and the role of capital gains vs. active savings over business cycles (Batty et al., 2019). Finally, to increase data consistency and transparency, estimates of wealth and income in the SCF can be compared to the national aggregates (see Batty et al., 2019, for wealth and Dettling et al., 2015, for income). Similarly, the CE collects information on all three, ICW, which could be compared to the national aggregates and used to construct joint distributions (see Fisher et al., 2015; Garner & Short, 2013).
Part of the dissemination plans for the report include developing pilot projects, conducting seminars at professional conferences, statistical agencies, and academic and policy institutions. These seminars could be sponsored by research institutions, like the Washington Center for Equitable Growth, Brookings Institution, Urban Institute, and the various Stone Centers for Inequality. The dissemination will also include development of an online webpage that allows comparisons of the many existing estimates of ICW (following the examples in Chapter 1). These comparisons can help lay the groundwork for establishing a new joint report (à la Recommendation 3-2).
Building on the comparisons of measures of ICW currently produced by the agencies, researchers and agency staff can begin (a) documenting the specification of their measures, (b) assessing how their measures compare to those produced elsewhere (as in Recommendation 3-2), and (c) evaluating the demographic and other categories that can be produced in their statistics (as in Table 3-3).
Following the initial phase, in the medium term (Phase 2, 2–5 years as shown in Figure 6-1), agencies should work with the steering committee and coordinating entity to move beyond the initial report and begin regular publication of estimates and reports, as in Recommendations 3-2 and 5-2. Following Recommendation 5-2, agencies should expand work blending survey and administrative data, using two alternative spines—the IRS data and the Census Bureau data (as in Figures 5.1A and 5.1B). This data blending task should include effort to expand on the NEWS and CID projects, incorporate work with IRS data (as discussed in Recommendations 5-1, 5-2, and 5-3), and evaluate the results of the pilot project comparing alternative
dataset constructions. Further investigation will be needed to examine the procedures to impute wealth via capitalization methods (building on the research of Fagereng et al., 2020; Smith et al., 2021; and the WAM10). The list of research topics can be expanded to include improving methods for the hard-to-measure items (identified in Chapter 2), such as the value of health insurance, retirement income, measures of time use and home production, and especially interhousehold transfers.
During this medium term phase, the steering committee can work with the statistical agencies to develop quality measures as in Recommendations 4-2 and 4-3. As stated in Recommendation 6-3, the medium term includes working with the coordinating entity and the steering committee to develop an NSDS pilot project to make data accessible for researchers.
Finally, the medium term includes the investigation of a new survey, or adding questions to a current commercial database, for the purpose of including detailed financial information such as spending and wealth, as in Recommendation 5-5. BLS researchers should consider how to use Opportunity Insights Economic Tracker or Inequality.org to improve the measure of consumption in the CE; another possibility is to add questions to a financial app, such as mint.com, or include information about households’ consumption in the Home Mortgage Database or the Making Ends Meet survey at the Consumer Financial Protection Bureau. These strategies should also include comparisons to data produced by existing online surveys, such as the Understanding America Study (as discussed in Chapter 4). Finally, research should continue along the lines of the recommendations in the Modernizing the Consumer Price Index report (National Academies, 2022) by using transactions-level spending data or receipt panels (as in the Circana or Nielsen Homescan panel) to improve consumption measures, or to include consumption measures on surveys with income and wealth.
In the longer term (Phase 3, 4–6 years), work should be oriented toward improving the data and methods that lie behind the regular reports. The vision is that the steering committee, coordinating entity, NSDS pilot, and agencies work together to establish secure methods for researchers to access the various blended datasets and expand the blended data by creating new linkages (e.g., commercial data such as Corelogic and Experian).
This phase will focus on creating a blended dataset that incorporates ICW information, and on developing tiered access protocols (as in Recommendation 6-1) to allow researchers to obtain access to the same data used by the agencies to develop the estimates. This will likely require using the FSRDC and forthcoming NSDS access points. The steering committee will need to incorporate current projects, such as NEWS and CID, into the ICW data infrastructure.
___________________
With new blended data infrastructure, work can advance to improve ICW statistics (Recommendation 3-1 and 3-2), update models, improve geographic data (as in Recommendation 3-4), generate more timely data (Recommendation 5-6), include additional demographic groups (Conclusion 3-6), and create pilot projects for data access to expand outside research.
Finally, the eventual goal is to link the ICW database to a longitudinal file and create a panel of ICW data (as in Recommendation 5-2). This could begin with a longitudinal database of income links across generations (as suggested in the Intergenerational Poverty report (see National Academies, 2023c), expanded to include wealth, and eventually consumption, and measures for each generation. This includes incorporating new Census Bureau projects such as MOVS and Decennial Census Digitization and Linkage project, and joint projects such as IDDA. Research should continue to use the current longitudinal files (such as the PSID and HRS) that contain ICW data, and evaluate whether consumption could be added to other longitudinal income research projects, such as the Global Repository of Income Dynamics.
Figure 6-1 shows the flow of these tasks for each of the project phases. Through all of the processes and stages, the steering committee and responsible agency personnel will be able to continually improve the statistics, data, methods, and access to data that are needed to evaluate the economic wellbeing of the population and its drivers.
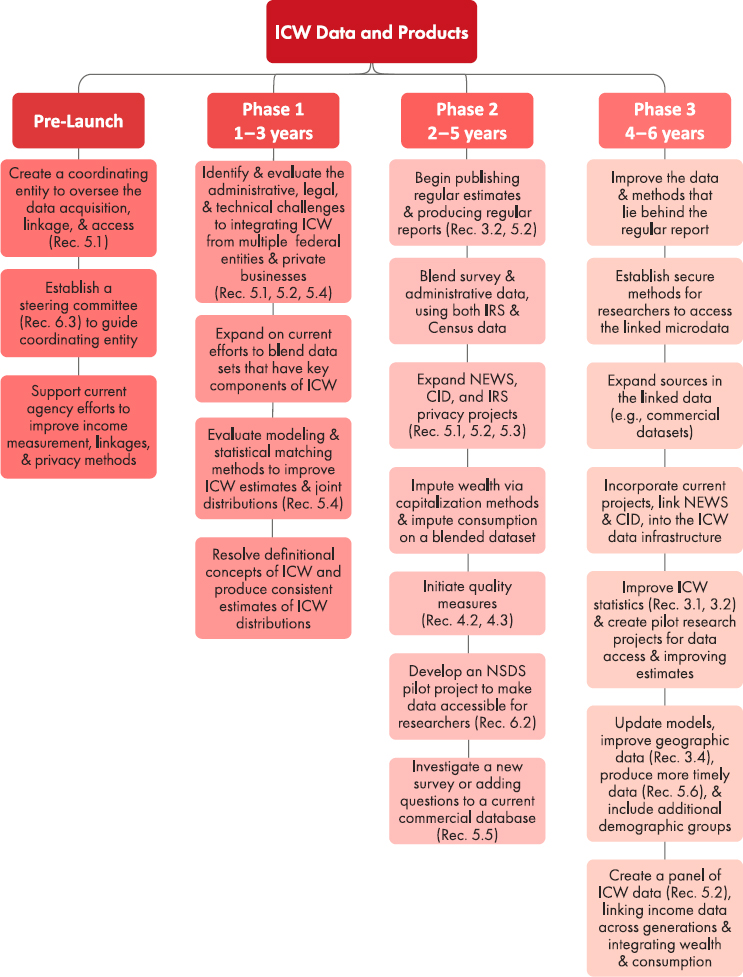
NOTES: Rec. refers to the Recommendations (by number) in this report. CID = Comprehensive Income Dataset; ICW = income, consumption, and wealth; IRS = Internal Revenue Service; NEWS = National Experimental Wellbeing Statistics; NSDS = National Secure Data Service.
SOURCE: Panel generated.
This page intentionally left blank.



























