Data Ontologies for Data-Driven Decision-Making: Research Approach and Findings (2026)
Chapter: Appendix A: Literature and Practice Review
Appendices
Appendix A – Literature and Practice Review
A.1. Introduction
A.1.1. Background
Asset managers and decision-makers are at an inflection point. In an environment with heightened performance-based management, cross-cutting analytics, and transparent decision-making, it’s proving more critical than ever to be able to balance organizational culture with the need to harness quality and timely data and information across functional areas, programs, and modes.
As DOTs collect more and more data, they face persistent challenges in converting that data into a business asset and instead often resort to ad hoc methods that produce unreliable results and different interpretations. This is because information systems are typically structured according to a “silo”-based architecture, which is populated by several independent, distributed data sources, each serving a specific application. In addition, advancements in technology and regulatory requirements have left agencies with many legacy systems, architectures, and an accumulation of separate systems. Although limited in many aspects, these legacy systems are still highly relevant because they are well understood by long-standing experts who have worked with the data. Notwithstanding their relevance and value in decision-making, legacy systems are costly to maintain and do not easily integrate with other organizational data and newer data systems, leading to data silos.
A.1.2. Research Objectives
This research aims to develop a guide for DOTs on strategies for implementing data ontologies that support agile and efficient data-driven decision-making. To achieve this objective, a targeted desktop scan was conducted to understand the current practice, identify gaps, and leverage ongoing DOT practices in re-engineering legacy systems. This appendix highlights the findings in the following areas: definition of standard terms; types of ontologies; frameworks; solutions for knowledge engineering; and State DOT examples in re-engineering legacy information systems. The last section discusses key findings and challenges.
A.2. Business-Driven Data Representation
Data representation refers to the methods used to represent information stored in a database. Many data models designed to represent data are user-driven, not business-driven. For example, data modelers in system implementation usually employ high-level system user requirements to design a data model to satisfy a narrow data analysis need, making the model context-specific with no flexibility for other business functions
across an agency. This is common for many legacy systems currently in use. On the other hand, data models that are driven by business functions facilitate cross-functional data use and support agency-wide business processes. In this framework, practitioners design ontologies to model the data and the entities the data refers to. As such, ontologies are considered business-driven, presenting formal definitions of classes and relationships between entities in a domain.
Business process integration is a critical part of the integration framework for legacy systems [1]. Ma and Molnar (2019) emphasize the need to analyze and consider the architecture for legacy system integration in constructing an ontology-based system integration framework. Figure 1 shows an example of an ontology learning process for legacy Enterprise Resource Planning (ERP) systems [1]. It is evident that a business-driven data structure and model can support the development of effective information systems, leveraging legacy systems. Realizing this key benefit requires practitioners to represent and communicate data using a business-driven approach – not a user-driven approach – in designing and developing business intelligence solutions.
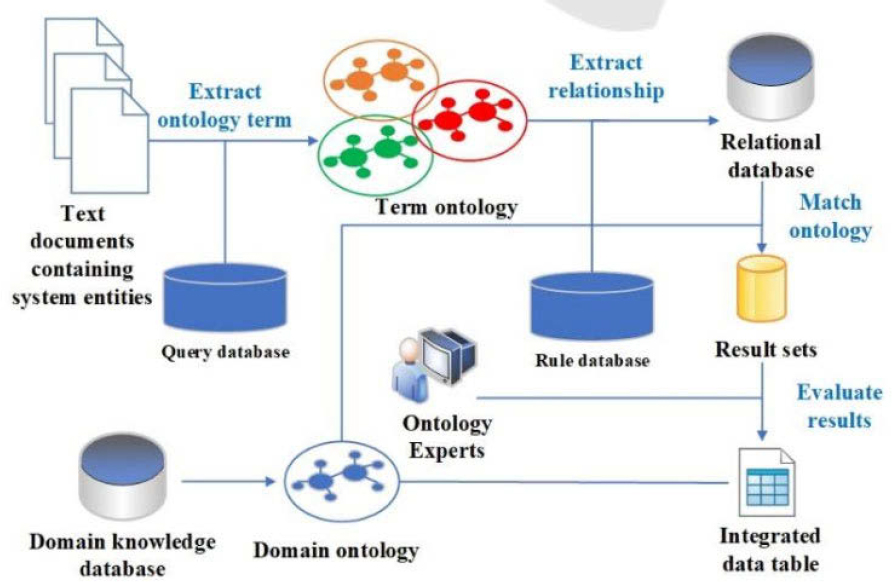
To develop a shared understanding of the relevant components of this topic, the next section defines a list of terms that will be used throughout the research and products. It is important to note that the list includes many relevant terms but is not exhaustive.
A.2.1. Definition of Terms
The literature contains several definitions of ontology, though there is no evidence of a single agreed-upon definition in the literature. Multiple sources provide the most relevant definition of ontology as “a formal, explicit specification of a shared conceptualization [2] [3].” Lemaignan et al. [4] describe ontology as a formalized description of concepts and relationships (both taxonomic and semantic) that exist between concepts. Finally, Baader et al. [5] define ontologies as a high-level description of a domain, which can be used by intelligent applications to draw implicit consequences from explicitly represented knowledge.
Effectively, ontologies provide the necessary semantics to enable data integration and systems interoperability. Although these definitions describe ontologies as a formal representation, they can be classified along a range of informal to formal, depending on the degree of formality [6]. Informal ontologies contain a simple representation of the relationship between concepts, while formal ontologies emphasize the role of logic as a way of representing an ontology. Thus, formal ontologies rely on semantic structures and taxonomies, employing strict logical constraints and operations in implementation. Yang et al. [7] streamline and define the building blocks of ontology to consist of four key components that form the vocabulary legacy systems use: classes, relations, functions, and instances.
A class is a conceptual grouping of similar objects. Members of the same class have characteristics that are similar to each other, just as they do with other groups of classes. Each class is specified using slots, values, and logical statements referred to as axioms.
A relation is an elementary component that describes the relationships among multiple terms inside a class. Description of relations is vital in discovering knowledge about a system because it explains the interaction between classes. The two common types of relations are taxonomic and associative. Relations enable users to conduct queries and retrieve vital information in a system -- for example, to find all grade-separated intersections close to schools and within a selected county. This example describes the spatial relation between two entities. In a social context, other examples describe the connection between two people, such as mother, father, and friend.
A function is a special type of relation that relates some number of terms to exactly one other term. A function is a relation such that no two relationships of n terms in the relation have the same first n-1 terms. For example, a mother is a function that relates an animal to exactly one female animal [7].
Instances are the elements (i.e., classes, slots, relations, functions, facets) represented by a concept. Classes are instances of a class, functions are instances of a function, etc. For example, in the transportation system, a timber bridge is an instance of the class “Bridge.” An instance and an individual are different because an instance may be
considered a class, whereas an individual cannot be a class. In the same example, timber bridges can be a whole class of bridges in which a timber bridge with a unique identification is considered an individual bridge.
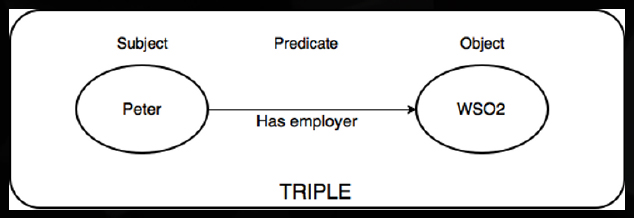
A triple refers to a combination of classes and relationships. Triples follow the structure (S, O, P), where S is the subject, O is the object, and P is the predicate, establishing the relation between the subject and the object. This structure is the foundation of an ontology, as represented by Figure 2 [8]. Combining these triples provides a comprehensive view of the natural world within an ontology. Developing more triples implies that there is an increasingly comprehensive system for a selected ontology.
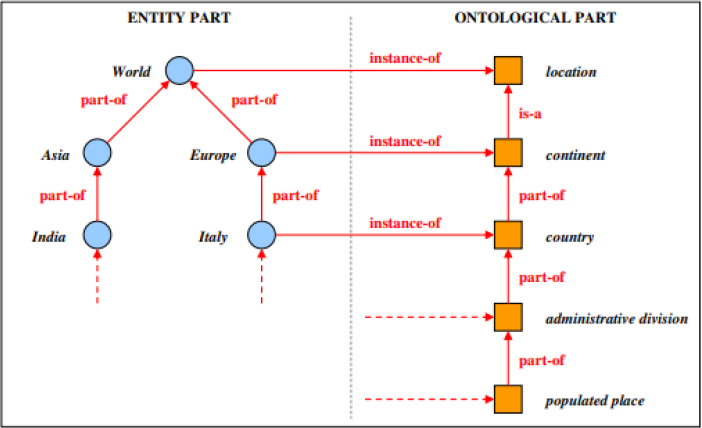
A facet is a group of hierarchically related concepts [9]. Facets consist of a hierarchy of homogenous terms describing an aspect of engineered knowledge, where each node in the hierarchy signifies a class or instance. Using the principles of facet analysis, a well-known technique developed by Ranganathan [10], a hierarchy can be characterized from the concepts. Two typical relations, namely “is_a” (genus/species) and “part_of” (whole/part), are the principal means for structuring hierarchies within a facet. Figure 3 depicts an example of a facet, showing the Administrative Division facet [9]. This process can be followed to construct similar facets from other feature classes.
A domain is an area of knowledge or field of study that we are interested in or communicating about, or an organized field of knowledge that deals with specific subjects. Domains can be conventional fields of study (e.g., library science, mathematics, physics), applications of pure disciplines (e.g., engineering, agriculture), or aggregates of fields (e.g., physical sciences, social sciences). Domains may also capture knowledge about our day-to-day lives, which we call the Internet domains (e.g., music, movie, sport, space, time, recipes, tourism).
These terms and their interactions are critical to understanding and developing ontologies for a system.
A.2.2. Building an Ontology
Types of Ontologies
Uschold and Gruninger [11] describe methods for building ontologies. These methods can be classified as top-down, middle-out, or bottom-up approaches. Although all ontology-building efforts take on one of these methods, they can differ in techniques. The level of conceptualization determines how an ontology is classified. The highest level of conceptualization applies to top-level ontologies, which are relevant for semantic reasoning and integration across domains. Domain ontologies correspond to the lowest level of conceptualization and are used to represent the knowledge and terminology specific to a professional, scientific, or similar domain [12] [13].
Figure 4 [14] classifies the three levels of ontologies based on abstraction and provides examples of an ontology for each level, including the Basic Formal Ontology (BFO), the Descriptive Ontology for Linguistic and Cognitive Engineering (DOLCE), the Suggested
Upper Merged Ontology (SUMO), the General Formal Ontology (GFO), the European Materials & Modeling Ontology (EMMO), the Chemical Entities of Biological Interest (ChEBI), and the Coordinated Holistic Alignment of Manufacturing Processes (CHAMP). Each level of abstraction provides examples of classes or entities that could be part of the ontology.

Classification and Descriptive Ontologies
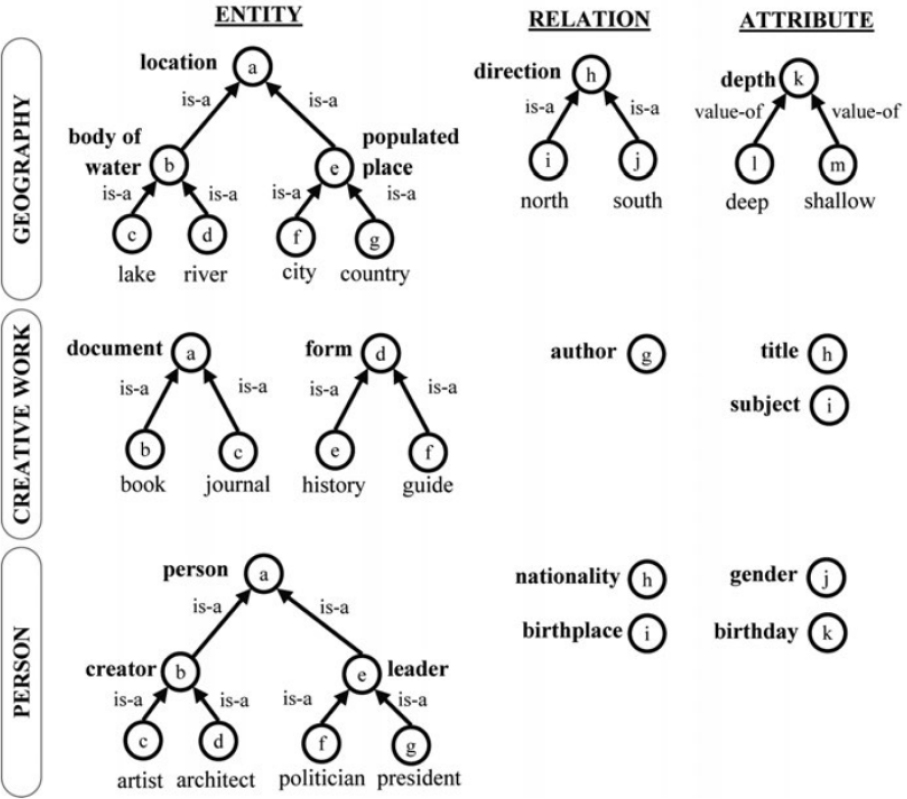
In building ontologies, it is essential to understand each one’s purpose and how to represent the knowledge gathered. Giunchiglia et al. [15] distinguish between classification ontologies and descriptive ontologies. The researchers describe classification ontologies as mainly used to describe, categorize, and search for objects such as documents. This type of ontology focuses on documents and would be useful for state DOTs in managing the extensive amounts of documents they produce. The goal of classification ontologies is to index instances of the description of documents, tasks, etc. An example of classification ontologies is depicted [15] in Figure 5. In this example, facilities can be considered to be in the class of transportation modes.
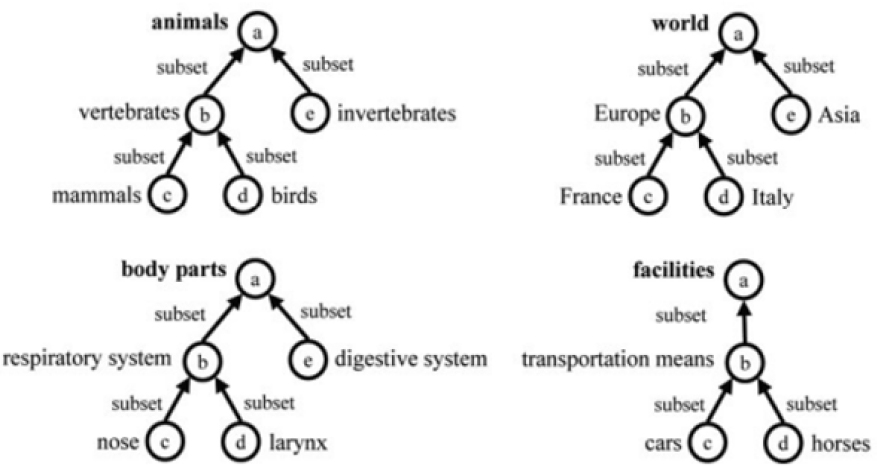
Conversely, the purpose of descriptive ontologies is to specify (describing and reasoning) the terms with their meanings and to structure the domain they model. Descriptive ontologies describe objects in terms of classes, attributes, and relations. For instance, they may specify that bridges deteriorate due to some defects and that certain types of treatments are needed to address them. In general, descriptive ontologies formally describe administrative properties so that these properties become easily retrievable and interoperable. Classification ontologies define a conceptualization of these properties in terms of topics they deal with, enabling semantic relations among heterogeneous properties. Figure 6 shows examples of descriptive ontologies in different domains [15].
A.3. Knowledge Engineering
In practice, different people may describe the same concept using different words. However, by applying rules and controlled vocabularies, experts can standardize domain terminologies to facilitate the creation of expert systems. As such, expert opinion, particularly from a given field of knowledge and data modeling expertise, will add value to the knowledge engineering and ontology development process. This is because experts possess background knowledge fundamental to operating semantics-based systems.
A.3.1. Knowledge Organization Framework
Description and retrieval of information resources requires well-structured knowledge organization systems (KOS) such as classification systems, gazetteers, lexical databases, ontologies, taxonomies, and thesauri. An extensive body of knowledge exists in the field of KOS. However, this effort provides a targeted review of some of the relevant work in this area, including exemplary knowledge engineering frameworks and
approaches that can support methodologies for developing ontologies. Classification is fundamental to knowledge organization. For example, the Library of Congress Classification (LCC) system, one of the world’s most widely used library classification systems, is used to organize and arrange the book collections of the Library of Congress.1 Researchers and practitioners from various domains have replicated this system to model the underlying semantic structure of their fields of study to advance interoperability. Through these efforts, access to documents, data, and information systems has improved using common vocabulary.
Yang et al. [7] document an extensive list of knowledge-sharing efforts for discovering the conceptualizations used by legacy systems. A more specific example of knowledge organization frameworks is the Domain, Entity, Relation, Attribute (DERA) framework, which offers a faceted framework for the development of ontologies with the ability to describe and reason about relevant entities of a domain [15]. It is designed to be flexible and agile, allowing users to extend and scale to accommodate virtually unbound quantities of knowledge. The framework is rooted in the following fundamental ideas:
- Knowledge should be organized in domains; a domain is an area of knowledge or field of study we are interested in or communicating about. For example, a domain could be transportation, medicine, music, agriculture, etc.
- Each domain should be organized into several facets; a facet is a hierarchy of homogenous terms describing an aspect of the knowledge being codified, where each term in the hierarchy denotes a primitive atomic concept.
- The Universal Knowledge (UK), its domains, and its facets should be designed using the Analytico-synthetic approach, a well-established methodology from library science that has been successfully used for several decades to classify books [16].
Although DERA is built on document search principles, it is entity-centric rather than document-centric. Some key features of this framework are its ability to address challenges with existing ontologies, such as extendibility, modularity, scalability, and the automation of reasoning using Description Logic (DL). The framework can be easily extended to accommodate new domains, facets, and terms. Secondly, it has flexibility of use by different semantic-based applications, making it highly modular. Finally, the framework can be scaled to use any domain independent of the number and size of the domains. Although built manually, DERA can be fully automated using direct encoding in DL [15].
___________________
One of the attractive features of the DERA is that it was built manually with many human validation enforcements to achieve a desired high level of quality. This feature is attractive because in the transportation domain, ontology development has not matured to fully automated reasoning. Hence, manual and semi-automatic approaches are more welcoming, although manual work can tend to be expensive in terms of time, effort, and proneness to errors. In practice, DERA has been used to develop a large-scale knowledge base called the UK. It contains millions of entities, thousands of terms, and tens of millions of axioms developed manually and supported by thorough, manual quality control.
A.3.2. Knowledge Engineering Solutions
Several emerging solutions that reuse legacy systems information have emerged to enable the extraction of concepts from data. This has led to creating requirements for enterprises to transform potential data and system users’ needs into complete, precise, and consistent requirement specifications, and for analyzing, selecting, and using available tools. Several tools and methods are available for resolving problems related to revitalizing legacy systems [2] [7]. However, many have not been practical solutions because they have tackled the problem from a technological perspective but failed to deliver semantically rich models of legacy systems’ business data [17].
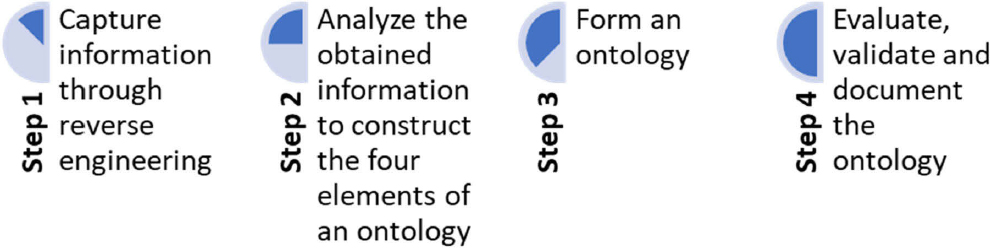
Domain ontologies aim to develop a structured vocabulary of concepts, syntax, and semantics to foster communication and use of systems, such as legacy systems. Yang et al. [7] proposed a four-step method for extracting ontologies from legacy systems. Their approach is viewed from three levels: the requirements and environment level, the schema level, and the data and application code level.
- The requirements and environment assessment are driven by the need to improve business functions. At this level, existing requirements of the legacy system are analyzed to fit emerging business functions, advanced strategies, and business rules and processes that will be integrated into the new systems.
- The schema-level assessment ensures smooth migration of the legacy database. A thorough decomposition process allows for cross-referencing the conceptual database schema, functional schema, and generated target schema.
- The data and application code level ensures that there are no inconsistencies in the data structures between the legacy database and the upgraded database.
The four-step method in Figure 7 is based on the approach described above. It consists of:
Daga et al. [17] provide a high-level overview of technology-dependent renovation approaches to reuse legacy system information. In this review, the researchers evaluated three main knowledge engineering approaches (shown in Table 1) and highlighted key features, explicitly noting how these approaches have failed to address current issues. They noted that the major limitation of current approaches is their inability to capture business knowledge. To mitigate this limitation, a new approach called Computational Sophistication (CS) was developed to help re-engineer (extract and document) the business knowledge contained in agency business data. This sustainable, business-driven approach enables an organization to understand and document knowledge in terms of its business semantics, providing scope for future refinements and reuse.
Sophistication is defined as a process of gradually improving a business model by removing any discrepancy between the semantics of the data from an application perspective and what exists in the real (business) world [17]. The researchers noted that sophistication lays a stronger foundation for developing a stable knowledge base through the following principles: explanatory power, fruitfulness, generality, objectivity, precision, and simplicity. Figure 8 shows the six core principles of ensuring stability, as defined by [17].
Daga et al. [17] approached the problem with two fundamental principles based on grounded theory. Their approach is rooted in empirical observations, understanding that ontology is about the objects that exist in the real world. Their approach recognizes that the extent of data contained in legacy systems can be overwhelming and also recognizes the need to develop a methodical approach to collect, analyze, and identify essential patterns in the data. Finally, they emphasize the importance of grounding the knowledge engineering process in legacy system’s available data by minimizing deduction.
Table 1. Technology-based Renovation Approaches
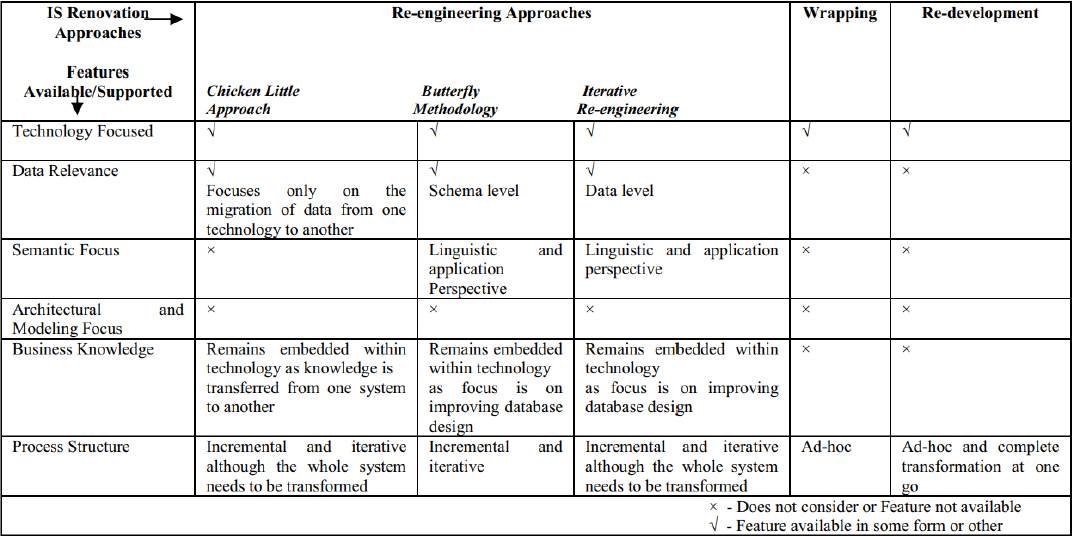
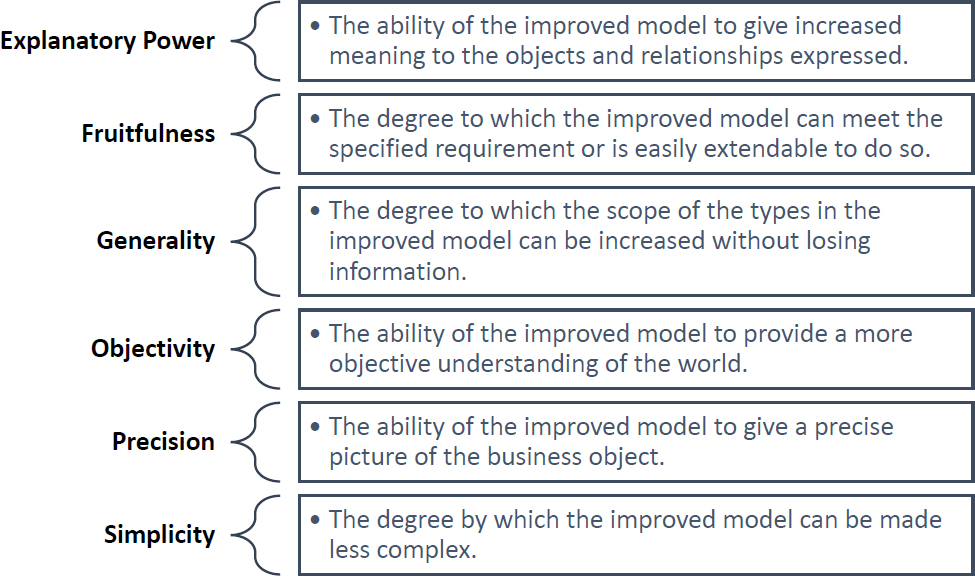
Figure 9 shows the CS process for extracting business objects from the data of operation legacy information systems.
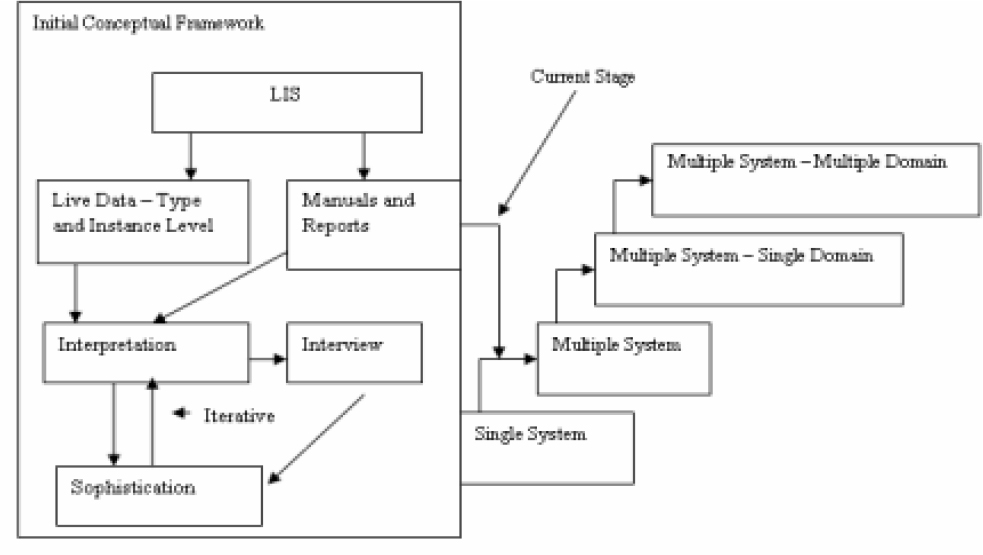
As depicted, the process can handle multiple systems and domains due to its generality and flexibility. Aseem et al. demonstrate this process by implementing an example of a Sophisticated Instance (SI). A SI is a CS artifact whose purpose is to enable the benefits of CS to be easily presented to and understood by a business audience, like the finance department [17]. The SI was used to renovate an extensive financial system to demonstrate its efficacy. These efforts are all aimed at standardizing knowledge for reuse across different business functions. The availability of standards can facilitate this process.
A.3.3. The Role of Standards in Ontology Development
Data standards and schemes complement ontology development. Whereas several data standards and schemas exist for representing and sharing data, no single one is universally accepted for use. However, with the push for Building Information Models (BIM) across transportation agencies to enable the seamless transfer of data across platforms, there is a need for single or multiple industry standards to minimize the potential loss of data through translation across applications. There are several national and international efforts to standardize this process. Specifically, at the international
level, buildingSMART International is leading an effort to extend the Industry Foundation Classes (IFC) standard data schema to accommodate infrastructure projects, including IFC Bridge and IFC Road.
At the national level, the Federal Highway Administration (FHWA) and the American Association of State Highway and Transportation Officials (AASHTO) are undertaking several efforts to facilitate the adoption of standards to enable data sharing and interoperability across disciplines. These efforts resulted in AASHTO’s recommendation to adopt the IFC Schema as the national standard for AASHTO member states. Similarly, FHWA is championing an effort to build a National Roadway Base Map to facilitate a consistent means of collecting, maintaining, and publishing spatial data across all levels of the transportation agency. Through this effort, FHWA has published a guidebook, “Application of Enterprise GIS for Transportation (AEGIST),” to enable technical and organizational implementation. The guidebook addresses the specific needs for defined objects and attributes at the technical level, whereas the organizational level deals with developing reliable and sustainable strategies to govern data [18].
These efforts indicate the industry is heading towards a common means to share data and improve interoperability. As it stands, there are multiple approaches accepted throughout the industry, requiring the development of ontologies to improve interoperability among these standards and data systems. The two primary standards that govern the construction of ontologies are the “Resource Description Framework (RDF)” and the “Web Ontology Language (OWL).” These two standards describe an ontology with two components: classes and relationships.
A.4. Re-engineering Legacy Information Systems: State DOT Examples
To gain insight into how State DOTs are re-engineering their legacy information systems, a desktop review was conducted using hit words like “legacy systems,” “data integration,” “ontologies,” “State DOTs,” data management, etc. There was evidence of DOTs replacing legacy systems with commercial off-the-shelf (COTS) and homegrown application systems. For example, Ohio and South Carolina DOTs were in the process of preparing to replace their legacy Right-of-Way (ROW) information management systems, while Vermont DOT is expanding the integration between its ROW system and other internal systems [19]. Other ongoing implementation examples from the desktop scan are presented in the following sections. These examples will be foundational to the targeted survey to uncover additional details of the individual State DOTs.
A.4.1. New York State Department of Transportation
As an early adopter of a linear referencing system (LRS) for transportation and safety data management, New York State DOT (NYSDOT) has several management systems in place that are outdated due to advancements in technology [20]. As data systems become outdated and technologies advance, the need for a new, customized safety tool becomes apparent. As a result, the NYSDOT is developing a Crash Location and Engineering Analysis and Reporting (CLEAR) tool to replace three legacy safety program data systems. CLEAR is a state-of-the-art, spatially enabled Safety Information Management System (SIMS) that integrates crash, roadway inventory, and traffic volumes on all public roads. As an enterprise-wide web-enabled solution, CLEAR will replace several NYSDOT legacy systems: the Accident Location Information System (ALIS), SIMS, and the Post Implementation Evaluation System (PIES). Table 2 contains the key data that will be part of CLEAR.
Table 2. CLEAR Key Data Sources
| Data | Source |
|---|---|
| Crash Data (2007 – present) | DMV/DOT |
| Crash Report Images and Diagrams | DMV (AIS) |
| Roadway Network (Statewide LRS) | OPPM |
| Work Requests/Orders (Agile) | DOT |
| Statewide Intersection Inventory | DOT |
| Geospatial Reference Data | Various |
When fully functional, CLEAR will enable users to geocode crash locations accurately, manage and edit crash data, manage and edit the statewide intersection inventory, query, visualize, and analyze crash data, enhance the development of safety solutions, and integrate with the New York State Department of Motor Vehicles and other existing NYSDOT systems. CLEAR reinforces existing standards through improved tracking and quality assurance when operational. The effective enforcement of standards will enable authorized users from multiple agencies to use different functions of the tool.
Figure 10 shows a screenshot of the interactive dashboard displaying a crash summary report based on multiple selection criteria [21].
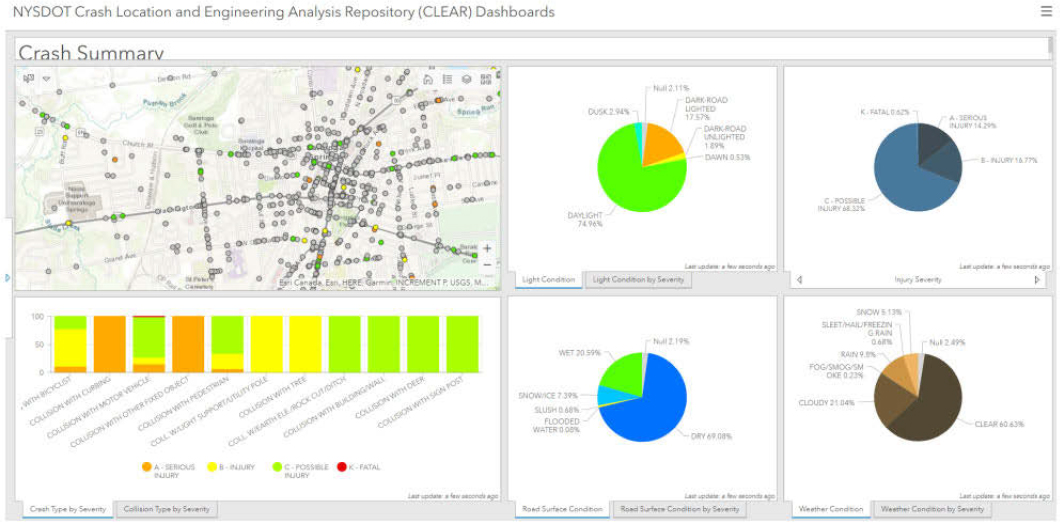
Documentation is a vital part of organizational knowledge management efforts to support the development of ontologies. Critical to the agency’s initiative is the opportunity for NYSDOT to revise and document its highway safety business processes and workflows, as well as train and educate both internal and external stakeholders to ensure the program’s sustainability. These elements of organizational cultural factors need effective management strategies to enable change.
A.4.2. Hawaii Department of Transportation
The Hawaii DOT (HDOT) embarked on an effort to expand its statewide data program, including implementing a COTS data platform. This effort included the assessment of the quality of data within the existing technology systems supporting each of HDOT’s key business functions [22]. To achieve its objective, HDOT had to re-engineer the existing data before integrating them into business intelligence tools to ensure that the modernized solution added value. The Agency used a prioritization process to integrate all data systems, ensuring it prioritized organizational data that supported programs such as asset management and safety programs. The asset management business function allows the Agency to manage and report on roads, bridges, and other ancillary assets that support safe operation of the transportation network. In addition to adding value to HDOT’s business process, this effort has enabled HDOT to comply with Federal requirements, such as 23 CFR part 490 and 23 CFR part 515.
The systems impacted by this effort include MicroPaver, which stores HDOT’s pavement data, and the various spreadsheets that contain the condition of HDOT’s bridges and other structures. Also, the existing paper-based traffic and safety data system will be transformed into an electronic format that can be used within the
analytics and management platform. These applications are locally owned and accessed across different regions. The asset management analytics platform uses GIS capabilities and integrates data from siloed asset management processes and systems from individual Districts to form a centralized business platform. The improved solution provides a holistic view of assets of all types, including roadway surfaces, signs, guardrails, guardrail end treatments, lighting, striping, bridges, etc.
In addition, HDOT sought to improve its maintenance management system. This improvement requires HDOT to migrate maintenance ticket data in its two legacy systems (AS400 and the 4Winds). Bringing this data into the business intelligence tool will improve transparency and efficiency in generating insightful reports and inform how the organization makes business decisions and uses resources effectively. For instance, a fully functional system will allow external stakeholders to see maintenance tickets based on the type, the region, and a selected date range, improving external communication.
A.4.3. Utah Department of Transportation
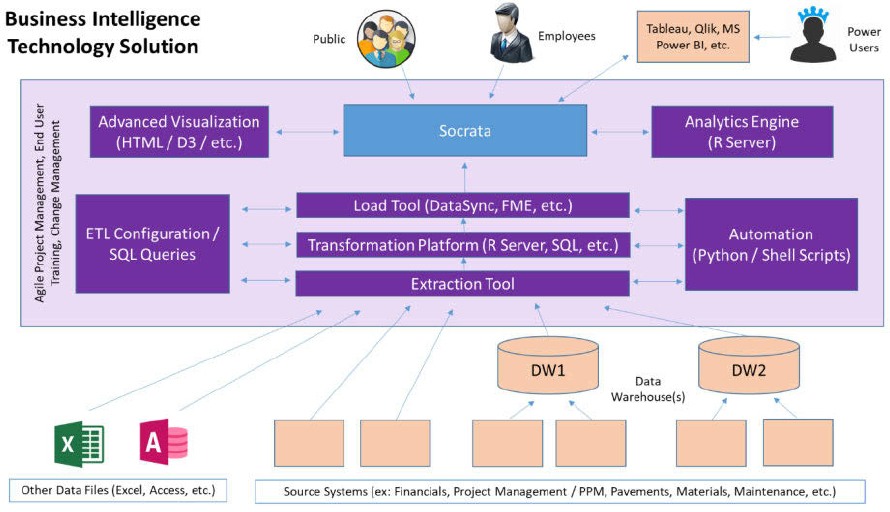
In 2016, the Utah DOT (UDOT) began a program to implement a flexible, cloud-based business intelligence and data analytics platform that embraces an open data philosophy, uses open standards, and adopts an agile deployment approach to drive these changes [22]. The goal of the project was to improve data sharing efficiency across key functional areas within the agency: finance and accounting, capital projects and programs, asset management and GIS, bridge and structures, pavement management, maintenance, traffic and safety, etc.
Figure 11 [22] shows the data-driven approach UDOT is taking to modernize its transportation systems through technological innovations that will significantly improve efficiency, cost savings, customer service, and performance and safety of agency transportation assets. UDOT achieved this goal by pursuing a workable solution that permits easy interoperability across the multiple systems and software operating systems underpinning the heterogeneous data systems. The ability to develop a semantic model of the data existing in these systems and combine them with the associated domain knowledge will help UDOT take advantage of advanced technology while leveraging legacy systems to improve decision-making.
A.4.4. Vermont Agency of Transportation
The Vermont Agency of Transportation (VTrans) embarked on an initiative to deliver a centralized repository of information related to its transportation infrastructure network. This Civil Integrated Management (CIM) or BIM approach involves making an accurate digital simulation model, referred to as a “Digital Twin” [23]. The Agency uses several systems and software programs in executing engineering, construction, and asset management activities. Most of these systems are proprietary, which limits sharing of information across them. But data and information must be shared across these tools effectively, requiring data- and business-centric models that allow interoperability between the systems. When fully implemented and advanced, this initiative will revolutionize how VTrans manages engineering and construction documents and conducts asset management. When VTrans successfully integrates this model with other asset models (legacy systems), the agency will have comprehensive information about its entire transportation infrastructure network.
A.4.5. Texas Department of Transportation
Texas DOT (TxDOT) Statewide Planning Map is an application that combines data and maps from various sources to provide an aerial view of TxDOT’s planning operations. The list of maps includes:
- ➢ Council of Governments (COG)
- ➢ Control sections
- ➢ Future traffic estimates
- ➢ Highways
- ➢ Imagery
- ➢ Legislative and congressional boundaries
- ➢ Metropolitan Planning Organizations (MPO)
- ➢ National Highway System
- ➢ Planned projects
- ➢ Railroads
- ➢ Texas Trunk System
- ➢ Traffic counts
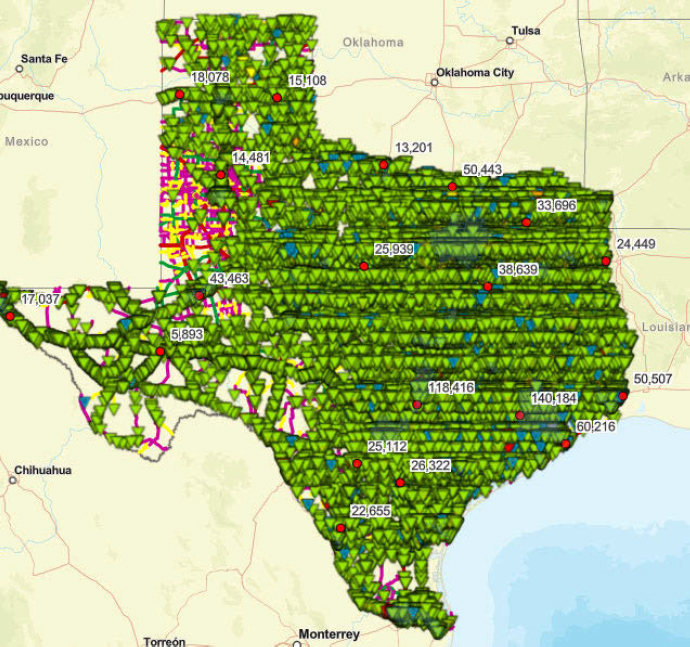
As a business intelligence tool combining various information, the Statewide Planning Map allows users to make interactive queries. Figure 12 shows a screenshot of bridges and annual average daily traffic (AADT) as filtered by the tool.
A.4.6. Summary of Reviewed State DOT Efforts
In general, the State DOTs studies, tools, and methodologies presented here provide exemplary frameworks for integrating data programs, particularly those related to financial and accounting, asset management, and highway performance management, including safety. However, as discussed earlier, there is a need for an adaptable, feasible, and implementable ontology development approach to use the rich information in legacy data systems. This approach should be tailored to include data
stakeholders at all organizational management levels (strategic, tactical, and operational) while acknowledging diversity across State DOTs. This will be the goal of the guide to be developed.
In addition to the state DOT examples, there are several research initiatives to support practice. For example, Varga et al. [12] discuss different ontologies in the infrastructure sector, including transport. They indicate that the transport sector has seen numerous attempts at development domain ontologies with varying scope. The literature also indicates there are varying ontologies across the private and public transport systems [24], focusing on urban infrastructure planning and maintenance ontologies for integrating various types of infrastructure and environmental data [25].
The key gap in the review was the lack of strategies to address organizational cultural factors.
A.5. Organizational Cultural Factors
Organizational culture (OC) is widely accepted as the collection of deeply rooted values and beliefs shared by personnel in an organization. The cultural factors of an organization indicate what is important to its members and leadership, what it supports, and how it operates. For many State DOTs, the development, deployment, and sustenance of ontology-based data integration may be a new concept requiring effective management strategies to adopt and sustain. For example, the agency may need to institute organizational, operational, or tactical changes to adapt to a new program. As such, building an agency culture and capacity that can influence the change approach is essential. Ignoring this part of the business process can adversely impact the strategy to implement ontologies, train the workforce, practice effective communication, improve workflows, determine processes, acquire technology, and other critical determinants of OC that support implementation and advancement. These factors may be considered internal factors, which can be influenced from within the agency, or external factors, which are not within the agency’s purview and need to be managed effectively to achieve success.
Several practice examples from DOTs about building and sustaining a well-rooted culture are found in the literature [26] [27]. These practices highlight strategies and organizational models that can be transferred to support ontology implementation in DOTs.
A.5.1. Organizational Design
“Organizational design is the process of creating a system where people can work together to achieve common goals. It is as much an art as it is a science [28].” As such, there is no one approach to developing an organizational model that serves the needs of the organization. However, a workable model must address relevant functional
elements to be effective. Literature has relevant studies that can equip practitioners to design models responsive to their needs. Two authoritative guidance documents that can be used to support OC, organizational models, and build the necessary agency capacity include:
NCHRP Research Report 1088: State DOT Models for Organizing and Operating Emergency Response: A Guide
“This guide presents state-of-the-art information to assist DOTs in assessing emergency response programs in foundational governance, programmatic planning and support, and building capacity for response for emergency surges. The Guide provides models that illustrate DOTs’ choices among various organizational and operational dimensions. The Guide also presents case studies of solutions DOTs have implemented across many organizational and operational facets, from specialized capacities, such as strike teams or mobile equipment teams, to integration of emergency management with security functions to close teaming of emergency management operations with Transportation Systems Management and Operations [29].”
NCHRP Project 20-24 (83), “Alternative DOT Organizational Models for Delivering Service”
“This report provides a big-picture snapshot of why and how DOT leaders are redesigning their organizations. It includes a discussion of the primary drivers of these changes, characterizes the current state of DOT organizational design, describes the prominent organizational adaptations DOTs are making or plan to make, presents a new organizational ideal for DOTs, and offers observations about key success factors for initiating meaningful organizational change, including seeking Senior Leadership support, keeping it simple, considering the scope of the change, identifying the right people to be part of the team, and investing the right resources [30].”
These guides demonstrate that there is no one-size-fits-all framework. However, one of the most universally accepted frameworks for organizational design is The Star ModelTM. This model consists of design policies developed by management to influence team members’ behavior. The Star Model highlights five key elements around which policies are designed: Strategy, structure, processes, rewards, and people [31].
Of key importance for sustaining the OC needed to deploy and advance ontology use in decision-making are the following factors, which align with the five key elements defined by The Star Model:
B.1.1. Strategy
State DOTs have defined goals and objectives as part of their strategic direction. Sometimes, there are measurable performance metrics to assess agency progress. New programs are more likely to sustain and gain higher and lower management buy-in if
the programs are linked to the overall agency strategy. Suppose stakeholders understand how their actions and program goals impact the agency’s mission and the value added to providing customer services. In that case, they are more likely to support the initiative. Many new initiatives have failed because stakeholders have not recognized an initiative’s value to overall agency goals. This can even impact the resources that are made available to the new program.
A.5.2. Leadership Support
Upper management support is an important factor in creating organizational culture. Securing buy-ins at all levels of the organization is essential. However, sustained support from the leadership team, including the organization’s Chief Executive Officer (CEO), is most critical. As an advocate for the change, the CEO commits to it and highlights its benefits to employees and essential stakeholders. Most importantly, upper management support can translate to receiving the needed resources (both financial and staffing-related) to sustain the change.
A.5.3. Governance Structure
Developing robust ontologies involves working with stakeholders across several functional areas, integrating multiple modes, and engaging with external partners. This requires delegating roles and responsibilities, identifying job functions, and delineating decision-making authority. There is no universal structure to support successful adaptation. The form of the structure depends on several variables, including the number of levels of authority, the number of people who will be involved, and the units across the agency that will be involved. Examples of current trends driving organizational change across many DOTs include a shift toward hybrid silo/workflow-based organizational designs that promote nimbleness, efficiency, and innovation; organizational re-centralization of key functions that ensure efficiency, consistency, and a refocus on a core mission; and increased interest in outsourcing as a means for operating effectively in a lean fiscal environment [31].
A.5.4. Workforce Management
Attracting, retaining, and developing the right workforce to support ontology implementation is critical. Agencies may need to institute proper knowledge management and training strategies to ensure stakeholders develop the right skills to support the activities. Several studies, including NCHRP Research Report 1008: Attracting, Retaining, and Developing the 2030 Transportation Workforce: Design, Construction, and Maintenance, provide guidance that facilitates the development and maintenance of a high-quality workforce in transportation agencies. The guide enables agencies to analyze their unique agency workforce needs and provides practical strategies to address the needs. In addition, NCHRP Report 636: Tools to Aid State DOTs in Responding to Workforce Challenges provides tools to help State DOTs respond to workforce challenges by recruiting, developing, and retaining a productive and
effective workforce [32]. These tools will serve as industry-accepted practices in support of the guidance development.
A.5.5. Rewards
People get motivated when they see rewards. Demonstrating rewards by answering the question “What is in for me?” will get stakeholders’ buy-in and provide a backbone for long-term sustainability. In this situation, rewards may not come as fiscal benefits. However, demonstrating how the actions would bring efficiency to stakeholders’ business can be helpful. This can be achieved by documenting and sharing use cases and pilots, and by conducting peer-to-peer exchanges for colleagues to share lessons learned. The guide will document practical examples and tips to help users demonstrate rewards for sustainable support.
The guide will address these organizational factors to assist users in fully implementing and taking advantage of the necessary resources to build agency capacity.
A.6. Findings, Challenges, and Next Steps
A.6.1. Summary of Findings
The following findings were gathered from the literature:
- There is an increasing need for semantic interoperability between legacy and emerging data systems to support effective and efficient decision-making across the business functions of DOTs.
- It is evident that a business-driven data structure and model can support the development of effective information systems, leveraging legacy systems.
- Ontologies can be classified along a spectrum of informal to formal, depending on the degree of formality.
- There are different approaches to developing ontologies, including top-down, middle-out, or bottom-up, depending on the level of conceptualization.
- Research on ontologies in the infrastructure sector is advancing, but has not developed enough to meet practice. There are varying ontologies across private and public transport systems, focusing on urban infrastructure planning and maintenance.
- The literature contains several knowledge organization frameworks, tools, and methods for solving problems related to revitalizing legacy systems. However, many have not proven practical because they tackle the issue from a technological perspective while failing to deliver semantically rich models of legacy systems’ business data.
- Several emerging solutions that reuse legacy systems’ information have emerged to enable the extraction of concepts from data in programs; the acquisition of requirements for enterprises to transform potential data and system users’ needs
- into complete, precise, and consistent requirement specifications; and the analysis, selection, and use of available tools.
- State DOTs have conducted studies and developed tools and methodologies that serve as frameworks for integrating data programs, particularly those related to financial and accounting, asset management, and highway performance management, including safety. These examples provide real-world context for future DOT implementation of ontologies.
- The creation of ontologies itself is a collaborative process that aims to streamline business processes, requiring strong organizational cultural strategies to be successful.
- To sustain a culture for deploying and advancing ontology use in data-driven decision-making, there must be a long-term strategy, buy-in from leadership, a functional decision-making structure, effective workforce management strategies, and a way to communicate the rewards associated with the change.
A.6.2. Challenges, Gaps, and Analysis
Based on the understanding of the topic area and the literature, the following challenges were identified as the starting point for the Guide to address. The challenges and gaps include:
- Legacy systems lack internal data standards and documentation to facilitate the building of ontologies.
- There is limited or no documentation (standard operating procedures) on DOT business functions and processes, which are foundational to the building of ontologies.
- Ongoing integration of legacy systems and migration to an enterprise asset, mainly focused on the technical and data integration aspects. They have not effectively addressed organizational cultural factors. Taking this holistic approach would enable DOTs to address resource limitations issues, such as manpower and financial resource needs, as well as support program sustainability.
- The constant turnover in State DOTs has exacerbated the loss of valuable knowledge for developing business rules and ontologies. Agencies need change management approaches, knowledge management strategies, and workforce development to address this challenge.
- There is a gap in workforce knowledge and competencies in developing and applying data ontologies in State DOTs. As such, there would be a need to build strategies for developing and delivering quality professional learning opportunities to develop the needed skillset in ontologies.
To address these challenges and the objectives of the research, the guide focuses on organizational, operational, and tactical strategies to enable DOTs to develop and use data ontologies as part of their data-driven decision-making processes.
Bibliography
[1] C. Ma and B. Molnar, “A Legacy ERP System Integration Framework based on Ontology Learning,” in 21st International Conference on Enterprise Information Systems, Heraklion, Greece, 2019.
[2] T. Gruber, “Toward Principles for the design of Ontologies used for Knowledge Sharing,” International Journal of Human-Computer Studies, vol. 43, no. 5-6, pp. 907-928, 1995.
[3] S. Staab and R. Studer, Handbook on Ontologies (International Handbooks on Information Systems), Berlin: Springer, 2nd ed., 2009.
[4] S. Lemaignan, A. Siadat, J.-Y. Dantan and A. Semenenko, “MASON: A Proposal For An Ontology of Manufacturing Domain,” in IEEE Workshop on Distributed Intelligent Systems: Collective Intelligence and Its Applications, Prague, Czech Republic, 2006.
[5] F. Baader, D. Calvanese, D. L. McGuinness, D. Nardi, and P. F. Patel-Schneider, The Description Logic Handbook: Theory, Implementation and Applications, Cambridge, United Kingdom: Cambridge University Press, 2007.
[6] O. Lassila and D. McGuinness, “The Role of Frame-Based Representation on the Semantic Web,” Electronic Articles in Computer and Information Science, vol. 6, no. 1401-9841, 2001.
[7] H. Yang, Z. Cui, and P. O”Brien, “Extracting Ontologies from Legacy Systems for Understanding and Re-engineering,” in IEEE, Phoenix, AZ, 1999.
[8] K. M. Sugathadasa. [Online]. Available: https://keetmalin.wixsite.com/keetmalin/post/2017/02/17/what-is-anontology#:~:text=3)%20Basic%20Structure%20of%20an,up%20of%20classes%20and%20relationships. [Accessed 9 Febraury 2024].
[9] M. S. F. Farazi, “Faceted Lightweight Ontologies: A Formalization and Some Experiments,” University of Trento, Trento, Italy, 2010.
[10] V. Broughton, “Facet Analysis: The Evolution of an Idea,” Cataloging and Classification Quartely, vol. 61, no. 5-6, pp. 411-438, 2023.
[11] M. Uschold and M. Gruninger, “Ontologies: Principles, Methods, and Applications,” Knowledge Engineering Review, vol. 11, no. 2, 1996.
[12] L. Varga, L. McMillan, S. Hallet, T. Russell, L. Smith, and I. Truckell, “Infrastructure and City Ontologies,” in Proceedings of the Institute of Civil Engineers - Smart Infrastructure and Construction, 2022.
[13] T. Hagedorn, B. Smith, S. Krishnamurty, and I. Grosse, “Interoperability of Disparate Engineering Domain Ontologies using Basic Formal Ontology,” Journal of Engineering Design, vol. 30, pp. 625-654, 2019.
[14] B. M. Torres, C. Volker, S. M. Nagel, T. Hanke, and S. Kruschwitz, “An Ontology-based Approach to Enable Data-Driven Research in the Field of NDT in Civil Engineering,” Remote Sensing, vol. 13, no. 2426, 2021.
[15] F. Giunchiglia, B. Dutta, and V. Maltese, “From Knowledge Organization to Knowledge Representation,” Knowledge Organization, vol. 41, no. 1, 2013.
[16] S. R. Ranganathan, Prolegomena to Library Classification, London: Asia Publication, 1967.
[17] A. Daga, S. D. Cesare, M. Lycett and C. Partridge, “An Ontological Approach for Recovering Legacy Business Content,” in International Conference on System Sciences, Hawaii, 2005.
[18] FHWA, “Applications of Enterprise GIS for Transportation: Guidance for a National Transportation Framework (AEGIST Guidebook),” Washington, DC, 2019.
[19] Caltrans Division of Research, Innovation and System Information, “Right of Way Information Management Systems: Preliminary Investigation,” 2016.
[20] M. Albee, I. Hamilton, and C. Chestnutt, “Data Integration in CLEAR,” FHWA Office of Safety, Washington, DC, 2020.
[21] L. Spraker and G. Stevens. [Online]. Available: https://www.dot.ny.gov/divisions/operating/osss/highwayrepository/CDV_Intro.pdf. [Accessed 9 February 2024].
[22] FHWA, Office of Operations, “Data Driven Approach to Modernize the Delivery of Transportation Services,” Washington, DC, 2019.
[23] State of Vermont Agency of Transportation, [Online]. Available: https://vtrans.vermont.gov/planning/research/projects/CIM. [Accessed 13 February 2024].
[24] B. Lorenz, H. J. Ohlbach, and L. Yang, “Ontology of Transportation Networks,” 2005.
[25] H. Du, L. Wei, V. Dimitrova, D. Magee, B. Clarke, R. Collins, D. Entwisle, M. E. Torbaghan, G. Curioni, R. Stirling, H. Reeves and A. G. Cohn, “City Infrastructure Ontologies,” Computers, Environment and Urban Systems, vol. 104, 2023.
[26] NCHRP Project 20-24(42), “Guidelines for State DOT Quality Management Systems.” Transportation Research Board, Washington, DC, 2006.
[27] SHRP 2 Report: Guide to Improving Capability for Systems Operations and Management. Transportation Research Board, Washington, DC, 2011.
[28] M. Hallowes, “The Org,” 12 May 2023. [Online]. Available: https://theorg.com/iterate/the-ultimate-guide-to-organizational-design. [Accessed 2 February 2024].
[29] Matherly, D., P. Bye, and E. Dinsdale. NCHRP Report 1088: State DOT Models for Organizing and Operating Emergency Response: A Guide. Transportation Research Board, Washington, DC, 2023.
[30] NCHRP Project 20-24(83), “Alternative DOT Organizational Models for Delivering Service,” Transportation Research Board, Washington, DC, 2012.
[31] J. Galbraith, 2016. [Online]. Available: https://www.jaygalbraith.com/services/star-model. [Accessed 02 February 2024].
[32] Spy Pond Partners, LLC. NCHRP Report 636: Tools to Aid State DOTs in Responding to Workforce Challenges. Transportation Research Board, Washington, DC, 2009.



























