Reference Manual on Scientific Evidence: Fourth Edition (2025)
Chapter: Reference Guide on Computer Science
Reference Guide on Computer Science
BRIAN N. LEVINE, JOANNE PASQUARELLI, AND CLAY SHIELDS
Brian N. Levine, Ph.D., is Professor, Manning College of Information and Computer Science, University of Massachusetts Amherst.
Joanne Pasquarelli, Esq., Washington, D.C.
Clay Shields, Ph.D., is Professor, Department of Computer Science, Georgetown University.
CONTENTS
Binary Encoding, Bits, and Bytes
Central Processing Units (CPUs)
Graphics Processing Units (GPUs)
Flash Memory, SSDs, and USB Drives
File Systems, File Metadata, and Databases
Algorithms, Programs, and Software
Programs and Programming Languages
Cryptographic Key Sizes and Attacking Encryption
Attacking Cryptographic Hashes
IP Network and Link Layer Addresses
Cloud Computing and Serverless Systems
Wireless Networking and Mobile Devices
Virtual Private Networking (VPN)
Anonymous Communication Systems
Network Identifiers and Third-Party Data Collection
Investigating Peer-to-Peer File-Sharing Systems
Investigating Anonymous Communication Systems
What You Have (Physical Tokens)
Forensics and Digital Evidence
Computer Science from the Perspective of Federal Rule of Evidence 702
FIGURES
1. The components of a computer system
3. Network Address Translation box hides a larger network behind it from the rest of the internet
4. Racks of computers or “rack” servers in a data center
5. A client-server network architecture. Dotted lines represent connections across the internet
6. A peer-to-peer network architecture. Dotted lines represent connections across the internet
7. Tor Browser connects a user to a website in a multi-proxy setting
Introduction
Computers have become inescapable. Virtually every adult and teen carries and uses a computer in the form of a smartphone holding incredible amounts of information about the user. Computers are present as wearable devices that monitor our health or are present in our buildings as fixtures that monitor and control our environment. Cars and critical infrastructure no longer work without them. We commonly use computers to communicate, seek and find information, navigate, and supplement our memory—and evidence of our actions often remains. Companies store massive amounts of data electronically about their activities and, where applicable, those of their customers. Accordingly, our everyday movements, communications, and actions often result in critical evidence that is relevant to both criminal and civil disputes. Court cases often depend on a forensic analysis of this stored digital evidence of the computational activity that has occurred or been recorded, particularly in the realm of emails and other communications. Computers will be part of many legal cases, in some aspect, for the foreseeable future.
In this reference guide, we provide a brief overview of how computers operate and communicate; the basics of algorithms, software, and cryptography; how computers communicate over networks like the internet; computer security goals and the process of meeting them; and what digital forensic evidence can be collected to support or refute some legal theories. Given the wide scope of topics, we are necessarily brief in our treatment of these topics, but we hope this reference guide provides a basis for understanding the technology that is involved in many legal issues. Standard textbooks are available that cover many of these topics in greater detail, such as from Kurose and Ross,1 Anderson,2 Bishop,3 and Kernighan.4 See also Darrell5 and Kerr6 for legal textbooks concerned with technology and computers.
Computer Organization
We begin with a general overview of computer organization, including hardware, file systems, databases, and virtual machines. Computer networking is covered in a later section of this guide.
1. James Kurose & Keith Ross, Computer Networking: A Top-Down Approach (7th ed. 2016).
2. Ross Anderson, Security Engineering: A Guide to Building Dependable Distributed Systems (3d ed. 2020).
3. Matt Bishop, Computer Security: Art and Science (2d ed. 2018).
4. Brian W. Kernighan, Understanding the Digital World: What You Need to Know about Computers, the Internet, Privacy, and Security (2d ed. 2021).
5. Keith B. Darrell, Issues in Internet Law: Society, Technology, and the Law (11th ed. 2018).
6. Orin Kerr, Computer Crime Law (5th ed. 2022).
Overview of Computer Hardware
A computer is a tool that processes information at blazing speeds. It performs this feat by encoding the information as electrical signals that can be processed as billions of operations per second, stored in huge quantities, or sent over a network. The hardware of a computer is designed to process data quickly through simple mathematical operations. It is the combination of computational power with functionality provided by programs that makes it incredibly useful. We describe programs and how they are created in “Algorithms, Programs, and Software.”
Binary Encoding, Bits, and Bytes
Every computer performs computations using a series of high and low voltages that represent a series of 1 or 0 values, each value being called a bit. All information on the computer, including programs or data files, is a series of bits, with the series representing some numeric value that has meaning in a particular context. This representation is called binary encoding. Each added bit in a series doubles the number of possible values that can be represented. A single bit can represent two values; two bits can represent four values; three bits eight values, and so on. The most common unit of data is 8 bits combined; this unit is named a byte, and it can represent 256 possible values and often represents one character of text. Most data are measured in terms of bytes, and it is common for measurements of bits to be represented with a lowercase b and bytes with an uppercase B. Units of a thousand bytes are called a kilobyte, abbreviated KB; units of a million are a megabyte, or MB; units of a billion bytes are gigabytes, or GB; and units of a trillion bytes are terabytes, or TB.
Buses and Controllers
Almost all computers have a similar physical structure. Typically, there is a motherboard that provides a base for other components and for communication between them, using electrical connections called buses. The buses connect components called controllers that handle receiving data from the user, from storage, or from the network and sending that data to the central processing unit (CPU). A typical motherboard will have a variety of buses, some that are very high speed to access random access memory (RAM) or to other components like graphical processing units (GPUs), and others that are lower speed and connect devices like Universal Serial Bus (USB) mice and keyboards.
Central Processing Units (CPUs)
The primary computational component that is mounted on the motherboard is the central processing unit (CPU), which is often the single most expensive component. Older computers most often had one CPU that contained one computational core whose speed was governed by a clock that generated electrical signals to keep computations internally synchronized. Some higher-power computers had more than one CPU mounted on the motherboard and could perform multiple computations at the same time with one set of computations in each CPU.
Advances in computational speed initially came from increasing the tick speed of the internal clock. However, this approach reached physical limits, mostly in terms of power consumption and related heat generation. More recently, designers started adding additional computational cores to a single CPU so that each CPU could perform multiple computations simultaneously. Now a single physical CPU typically has many computational cores, which enable new uses like hosting virtual machines, as discussed below. The number of cores varies depending on design and cost of the CPU; low-cost CPUs might have 1 to 4 cores, while high-end CPUs might have 64 cores or more, with a range in between. With mobile computing becoming widespread, designers often work to decrease the power required for computation so that mobile devices, like phones and laptops, can last longer while running on battery power.
Graphics Processing Units (GPUs)
The other component that is increasingly used for computation is the graphics processing unit, or GPU. The GPU was originally used to increase the speed of on-screen video, particularly for games, but over time other uses have become popular. GPUs are excellent for machine learning and cryptocurrencies, and they have become essential to those areas.7
GPUs differ from CPUs in that they have many more computational cores than a CPU, though each core is more specialized and limited in what it can do. Whereas a CPU might have between 4 and 32 cores, a GPU might have thousands of less-powerful cores. In addition, GPUs execute tasks delegated by the CPU during the execution of a program, and they do not run programs on their own.
7. For a detailed discussion of machine learning, see James E. Baker and Laurie N. Hobart, Reference Guide on Artificial Intelligence, “What is Machine Learning?” section, in this manual.
Random Access Memory (RAM)
The CPU stores some working data in its own circuitry, but such storage is expensive and displaces circuitry that could be used for computation. Each CPU has several caches of memory: the high speed but smaller level 1 cache, and one or more other levels of caches, each larger and slower than the prior level. More storage is supplied off the CPU in random access memory (or RAM). RAM is a large bank of hardware memory that can be accessed relatively quickly by the CPU when it needs data. RAM is often connected to the CPU on a dedicated, high-speed bus so there is no conflict with other data coming from other devices. GPUs have less cache, instead having high-bandwidth connections to the RAM to supply the data needed.
RAM is volatile memory, meaning it requires continuous power to store data. For desktop computers this means that data can be lost when power is lost. For laptops and some battery-powered devices there is usually a mechanism to store the contents of RAM in longer-term storage when it appears the battery will become exhausted; other devices have a memory-preserving sleep mode.
Data Storage
Flash Memory, SSDs, and USB Drives
Most computers now use flash memory for internal data storage. Flash memory is a type of hardware-based storage similar to RAM, except that it is nonvolatile. When power is removed from flash memory the data is not lost. Flash is not a replacement for RAM in part because it is much slower and in part because flash has a characteristic that the memory cells can only be written to a limited number of times. Flash memory is commonly used for solid state drives (SSDs). These drives are an improvement over hard drives that are based on spinning magnetic platters, described below. SSDs have faster access speeds and lower power usage, but they can be more expensive for the same amount of storage.
Flash is also commonly used in portable storage. It is incorporated into a huge range of cards, sticks, and keys, which sport a variety of connectors. Perhaps the most common type of portable storage is the USB drive—often referred to as a “USB key fob” or “USB key”—which connects via a computer’s USB port. Card readers that support a variety of formats are available, and some laptops include built-in readers.
Hard Drives
Non-SSD hard drives use an older mechanical technology based on magnetism to store bits of data on a rotating platter. While these drives are less common in laptops and PCs, they are still used in many server applications for bulk data storage. The size of the platter has been getting smaller over time, though the density of information written on the platter continues to increase. Desktop drives commonly use 3.5-inch platters, while laptops use 2.5-inch platters, and embedded devices and the smallest laptops use drives with 1.5-inch platters.
Other Media
While SSDs and hard drives are most common, there are other types of media still in use. Optical media, such as compact discs (CDs), digital video discs (DVDs), and Blu-ray discs, encode data in a way that they are readable by laser light. Current technologies store data on discs by encoding bits as tiny pits that change the reflectivity in reflective media and can be read as bits by a laser. Tape is sometimes used as a backup media. It is a long, magnetic, ribbon-like material that is stored on spools that are often inside a cartridge. Tape provides sequential access to data instead of random access. The tape must be read from front to back. Tape can provide significant amounts of storage inexpensively, though the access rate is slow.
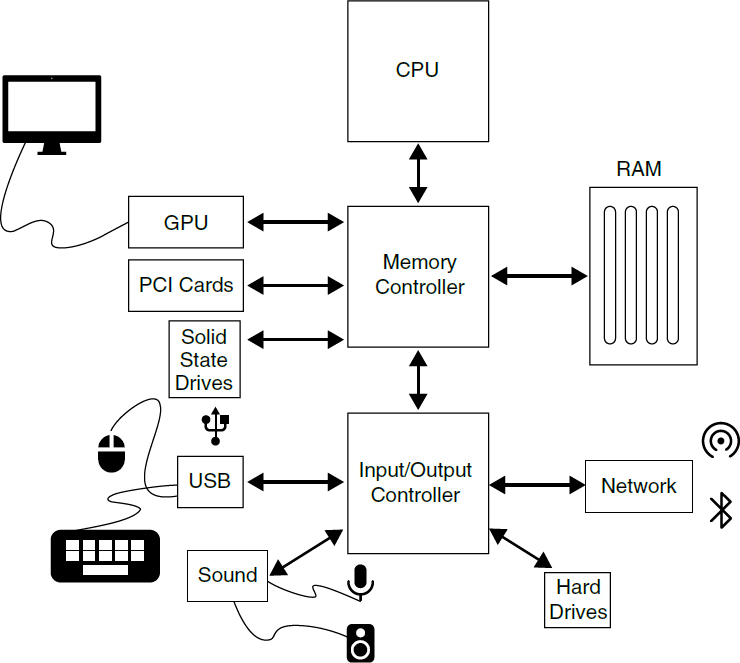
General System Diagram
Figure 1 shows the basic layout of the devices in a computer. The high-speed bus and low-speed bus are separate components on older computers, but some or all of that functionality might be incorporated directly into modern CPUs.
Operating Systems
The hardware of a computer is shared across all the programs using it. Operating systems (OS) are a common and specialized type of software that mediates between the system hardware and the software that wants to use it. Operating systems provide a number of useful functions. They manage resources shared between programs, such as access to devices like storage and input/output devices and allocating memory. They provide a common interface to hardware so that programmers don’t need to be aware of specific differences between individual hardware brands or components by providing an interface for drivers, which specify how the OS can interact with hardware. They provide a user interface so that users can start
and stop programs and access files and other information. Computer programs written for one operating system are generally not compatible and will not work with others. Some OS are designed for desktop and laptop use, like Microsoft Windows and Apple’s macOS. Others are used for mobile devices, like Google’s Android or Apple’s iOS. Still others are most commonly used for servers, like Linux.
File Systems, File Metadata, and Databases
Computer storage media provide the ability to store information, but they do not inherently organize it; they come as large blank storage areas. Computer operating systems format storage media with a file system that provides a structure for storing and retrieving directories and files. Operating systems typically protect
files that are critical for the OS to function and isolate user-generated files between users. The file system also keeps accounting information about each file. This is generally referred to as the MAC times, which are the times a file was last modified, when it was last accessed, or when it was created. These times may or may not be entirely accurate, depending on the operating system being used, if the system clock is accurately set, and the circumstances of the file creation; they also might be manually changed. They are not inherently reliable. These data are a type of metadata, which is data about or related to other data.
File metadata can be instrumental in litigation as it can reveal many facts relevant to key issues in litigation, such as the location and the date and time files were created, accessed, or modified. Often the most important role of file metadata is to support or attack the credibility of evidence—both testimonial evidence and document evidence. For example, in a contract dispute metadata revealed the creation date of a key document was almost one year later than the defendant had represented. Of note, the creation date shown by the file’s metadata was in fact just two days prior to the document being disclosed to the court. While metadata still requires authentication to be introduced as evidence of the true creation date, it provided sufficient grounds to challenge the credibility of the defendant’s prior assertions regarding the existence of the document.8 A court may deem metadata to be self-authenticating if the opposing party shows no reason to doubt the authenticity of the metadata.9 Metadata regarding the time a file is created, accessed, or modified can also be relevant in medical malpractice cases where electronic medical record systems are utilized. In today’s world of electronic files, metadata can be relevant in any case where the creation and access times for key files are important to pending litigation.
When a file is written to storage by a program, it is itself formatted in a very specific way according to the design of the program and the information the program needs to store. The internal format of the file depends on the program being used, but many files include additional useful information about the file that may not be visible to the user without special tools or without using program features to access it. For example, one image file format is the exchangeable image file format (EXIF) standard, which can include the time and date the photo was taken, a GPS location, as well as details on the camera that took the image. Similarly, Microsoft Office documents contain metadata about the creation of the document, often including the author and the amount of time spent editing the document and changes made, among many other things. Any file under the control of a user can be altered. Thus, just like the images themselves, EXIF data could be easily altered by the owner of a file, meaning the authenticity of the metadata should be confirmed before accepting it as evidence.
8. SPV-LS v. Transamerica Life Ins. Co., 912 F.3d 1106, 1114 (8th Cir. 2019).
9. Tamares Las Vegas Props., LLC v. Travelers Indemnity Co., 586 F. Supp. 2d 1022 (D. Nev. 2022), cited by CNA Ins. Co. Ltd. v. Expeditors Int’l of Wash., 2023 WL 6892565 (W.D. Wash.).
EXIF data can become critical evidence in criminal cases. For example, an image of child sexual abuse material (otherwise known as child pornography) containing EXIF data revealing the GPS location where the image was taken with an iPhone 4 was posted to a website. This EXIF data led the FBI to the owner of the iPhone who admitted to taking the image. During the resulting prosecution, the defendant filed a suppression motion arguing the EXIF data was protected by the Fourth Amendment because it was not visible to anyone viewing the image on the website. The court denied the motion holding there is no Fourth Amendment protection for the EXIF data as it was publicly accessible when the image was publicly posted.10
It is also important to note that the internal format of the data may not translate directly to what is shown on the screen. Additional information may be recoverable from careful analysis. For example, a portable document format (PDF) file is used to format and display documents for printing. Making a PDF file is often the final step in releasing documents in public settings. Information that was intended to be redacted from PDF documents is sometimes recoverable with special tools or simple mechanisms. For example, if the redaction involves covering text with a black rectangle, the redacted text may still be stored within the file and recoverable using the right tools.
A database is an alternative way of organizing a collection of information. Instead of files, the database has entries stored in tables. Most often, all items in a table are related information. For example, one table might consist of a set of names; another table might consist of a set of addresses. Internal identifiers are used to relate items across tables. Databases use a different interface than file systems. Most often, there is a computer language that can issue queries to the database so that it can retrieve items that match the queries. (For example, a query may be issued to identify all rows in a table related to a specific city.) In contrast, files are most often accessed by the file name and perhaps what directory the file is in; while some operating systems support searching files by content, it is not the primary means of accessing data.
Virtual Machines
Computers exist in the physical world, each taking up some space and requiring cabling for power and networking—which can be inconvenient for those who need an additional computer, for example, to run different operating systems or for those who want their own isolated server for security reasons. Providing these individual devices—real, physical devices—can be cumbersome and expensive.
10. United States v. Post, 997 F. Supp. 2d 602 (S.D. Tex. 2014).
Virtual machines (VMs) have become a commonplace solution to this problem. A virtual machine is a software program that pretends to be computer hardware while running on a host’s real hardware. A virtual machine makes use of one or more of the host computer’s CPUs or computational cores like any other program running on the host. The VM is allocated storage on the host computer, and it provides network access through the host computer. Within the environment provided by the VM, it is then possible to install the same or a different operating system as the host and then run programs on the VM. Programs operating in a virtual machine most often run the same way they do on a physical machine; some malicious software will attempt to detect if it is in a virtual machine and change its operation as a result, but few if any benign programs do so. Virtual machines are designed to be completely separate from each other and to isolate operations in the virtual machine from the host systems and other VMs.
Virtual machines have several uses. The most common is internet server hosting. Instead of paying to have an expensive physical server placed in a secure co-location facility, users and companies can instead rent virtual machines from services such as Amazon Web Services, Google Cloud, or Microsoft Azure, among many others. The use of rented servers is often called cloud computing or a serverless architecture (see section titled “Cloud Computing and Serverless Systems” below) and represents a multibillion-dollar market, although not all such services are provided through virtual machines. VMs are also commonly used to increase security. Untrusted software can be run in isolation on a VM in case the software acts maliciously. If it does, the impact is isolated, and the virtual machine can be easily discarded. Finally, individual users might run virtual machines to experiment with different operating systems. Rather than having a computer for each, one computer can host many different operating systems that can run different software.
Algorithms, Programs, and Software
The operation of programs is central to understanding other topics surrounding computing. Here, we provide an overview of how programs are developed and turned into software products, which is relevant to legal issues that address what software does and how it was developed.
An algorithm is a series of ordered steps used to complete a task.11 We use algorithms in many aspects of our daily life: a recipe to cook a certain dish or the diagnosis and repair of an item are both common examples of algorithms that
11. Algorithms (and in particular complex algorithms) are discussed in detail in James E. Baker and Laurie N. Hobart, Reference Guide on Artificial Intelligence, in this manual. See, e.g., sections titled “Complex Algorithms,” “The Heart of AI Is the Algorithm,” “Forms of Algorithmic Bias,” and “Algorithms that Predict Human Behavior.”
humans follow. An algorithm must be specified in terms that the person following it can understand and complete; you couldn’t give a child direction on how to drive somewhere as they don’t know how to drive, for example. It is also possible to define an algorithm as a combination of many smaller algorithms. For example, one might follow one algorithm to diagnose the cause of an item’s malfunction, and then repair the item following an algorithm determined by the diagnosis.
Programs and Programming Languages
A computer program is an algorithm that a computer can run to solve a computational problem or task. An application is a program that a user interacts with directly. When a program is in a format that the computer’s hardware can execute directly, it is called an executable. Because this executable format is difficult for humans to edit, programs are instead created by programmers who determine what the algorithm should do and then write source code that specifies the steps of the algorithm in a human-understandable programming language.
Some programming languages are called interpreted languages; sometimes these are called scripting languages, or scripts. In these languages there exists an executable called an interpreter that takes the source code and executes the algorithm one step at a time, essentially performing the interpretation and execution concurrently. Other languages are compiled languages. Programs in these languages are translated into executable form using a program called a compiler. This resulting executable can then be distributed and run independently of the source code. For compiled languages, translation to an executable occurs entirely ahead of the execution of the program. In general, compiled programs have better performance than interpreted programs but require more programmer time to develop and are closely tied to the system where they are expected to run; they often cannot run on other systems without changes or special support. To be able to run on many different types of hardware, some languages are designed to use an intermediate format that is independent of the hardware being used and which gets translated as needed to run on a local processor. For example, Java is designed to run on a Java virtual machine (JVM) or equivalent. Instead of recompiling the Java source code for each computer platform, the JVM only is recompiled. To execute a compiled Java program, the JVM translates from the program’s instructions to the actual hardware instructions; performance is better than purely interpreted code.
There are many different programming languages, each of which is generally used to solve some class of problems. Some languages are most convenient to use for the web, with some on the web server (such as Ruby and PHP) and some in the web browser (like JavaScript); some for data analysis (like Python, R, and Julia); others for games (commonly C++ and C#); others for computational infrastructure (like C and Rust); and still others for mobile application
development (like Swift and Java). There is a significant overlap between languages, and most can be used for multiple purposes.
It is also possible to partially reverse the compilation process, which is called decompilation. It is not straightforward to decompile code. For example, decompilation typically does not produce the exact source code used to create the executable because information of use only to human programmers, like names or labels indicating what a value means, is often removed as a step in the compilation process.
Computer programmers often split programs into smaller pieces for a variety of reasons, including to reuse algorithms and to allow many programmers to work on the same program at once. Because of this, code is often written in a modular form where smaller sub-algorithms can be assembled to form the larger overall algorithm. Within a program, these sub-algorithms might be called functions, methods, or procedures interchangeably. Often, so that such functions can be shared among many programs, they are placed into libraries. These libraries might natively be part of the ecosystem of the programming language; they might be libraries that are freely available for download; they might be libraries that are commercially available for license; or they might be part of the computer’s installed operating system, as described above. The term software refers to any or all of these various executable portions of code, from applications to libraries to the operating system.
Software Engineering
Programming is just one aspect of the larger topic of software engineering. Software engineering is a process that also involves design, testing, documentation, and maintenance of software. Many factors affect the complexity of the process, including the number of users of the software, the complexity of the software, the longevity of the software, the level of reliability needed, and the number of programmers coordinating simultaneously or longitudinally over time. A critical aspect of software engineering is communicating and documenting the requirements of a project.12
A variety of tools are commonly used to manage these processes. For example, splitting software into modules helps with the development of larger projects. Different teams of programmers can work on and test each module separately,
12. For a general discussion of the engineering design process, see Chaouki T. Abdallah et al., Reference Guide on Engineering, “The Engineering Design Process” section, in this manual. The role of computers and the implications of their use in design and complex systems is discussed in the Reference Guide on Engineering in the “Complex Systems” and “Computers, Artificial Intelligence, and Machine Learning” sections.
then combine them into a larger program. This approach leads to a model where most programs are layered. Each layer is independent and presents an interface known as the application programming interface (API) that defines how the software in that layer can be accessed. Each layer can then be changed or replaced without major modifications overall as long as the layer maintains a consistent API. APIs can be an important part of commercial products. For example, services like Amazon Web Services, Google Cloud, and Microsoft Azure provide computational services for rent that can be accessed through an API.
Software projects can vary significantly in size. Software size is often measured in lines of code, which is what it seems: a count of how long the programming language portion is. This metric is not easily comparable between languages and is a rough approximation of effort at best.
A small module or program might be only a few tens or hundreds of lines of code. A large project, like the source code for a computer operating system, might contain thousands of smaller modules and be many millions of lines long. It is thought that the code for Microsoft Windows totals over 50 million lines; the Linux operating system has about 28 million lines of code as of the time of this writing.
Code is typically stored in a source code repository. This is a specialized database, often called version control software, that can track changes made by different programmers to the code, which can help programmers and forensic investigators alike understand when and where code was added. A repository is helpful in merging new code with existing code, including new code in a program for testing, and submitting code for managerial or peer review before final inclusion. It also allows for different code versions and reverting source code changes should there be errors. Common tools for source code management include git, CVS, svn, and Visual SourceSafe. These can be useful sources that can show how software was developed over time.
Many kinds of testing methodologies are involved in verifying the correct operation of software. For example, unit tests ensure that the smallest components of a code base function as expected. Regression tests ensure that as new features are added or as repairs are made the current level of performance of a software system is not reduced or new errors added. Integration tests ensure that distinct subsystems interoperate as expected. Often software systems involve a continuous integration continuous delivery (CI/CD) pipeline where new changes are tested against a battery of tests before they are accepted into the main code base; this testing often occurs overnight. The goal of CI/CD is that software is always available in a state that is operational and correct, so that it can be delivered to the customer at any time. As a code base is expanded, developers add to the battery of tests to keep the CI/CD pipeline current. Finally, many larger projects will involve a team of quality assurance (QA) tests that test for bugs, rate performance, and ensure a high-quality user experience before software is released.
Source Code Distribution and Software Licensing
Most commercial programs that are developed by companies do not disclose source code, and the program’s source code is not shared with others. This closed-source approach helps protect trade secrets and avoids aiding competitors. In contrast, some programs are developed openly, and the source code is publicly available. For example, Microsoft’s GitHub.com platform hosts many open-source projects.
Software is commonly licensed, rather than being sold outright. Licensing allows the software vendor to impose conditions on its use, including prohibitions on copying, distribution, and reverse engineering. Many commercial programs are licensed under proprietary End User License Agreements (EULAs) that users must accept to acquire or use the software, and copyright is retained by the company.
Open-source software is often distributed under what are commonly called Free and Open Source (FOSS) licenses and are sometimes referred to less accurately as “free software.” There are a variety of open-source licenses; most allow use, copying, and modifications of the program. They vary on whether the code can be sold, redistributed, or sublicensed. Some licenses, most notably the GNU Public License (GPL), allow modification and private use but require that any such modifications that are sold or distributed are also licensed under the GPL, ensuring that source code improvements become available and that software will be improved over time by interested parties but remain available to all. As this approach is quite different from usual copyright, this license is referred to as copyleft.
Other open-source licenses allow sale and modification without requiring source code distribution; the BSD license, for example, allows use of and modification of code if the original license is included in future distributions. Similar licenses exist for other material, such as writing and photographs. A common one is called the Creative Commons license.
Source Code Review
In many situations, parties in a legal proceeding disagree about what software does, making source code review a key part of the discovery process so that both parties can assess essential evidence. This scenario arises in cases involving product liability, trade secrets, and patent infringement and is sought by defendants in criminal cases where key evidence was collected through software. Source code review intrudes on information protected as proprietary, trade secret, or law-enforcement sensitive information and therefore should only be used when the threshold has been met to overcome these software protections. Source code
review occurs when the software code is the central evidence to the case, such as in the seminal software copyright case of Google, L.L.C. v. Oracle America, Inc. Source code review was also used by plaintiffs in a key Toyota product liability case to argue that the software governing the electronic throttle control system was defective, causing sudden acceleration events that resulted in numerous deaths and injuries.13
However, protections for trade secret, proprietary, and law enforcement sensitive information should prevent disclosure of source code when the software is not the central evidence of the case itself. For example, in a patent infringement case involving wireless communication technology, a U.S. district court denied the plaintiff the opportunity to review a third party’s source code, holding that the third party’s concerns regarding the security of the source code could not be ignored despite the protective order. The court stated that the entity owning the source code was not a party to the lawsuit nor were they accused of patent infringement. Furthermore, the court held that the relevant information could be obtained from deposing a company engineer rather than from reviewing the source code.14 Similarly, software used in criminal investigations becomes essential when it is used to collect evidence in the prosecution’s case-in-chief. For example, in United States v. Budziak, the Ninth Circuit held that the source code was material to the defense’s case relying on the fact that the evidence presented at trial to support the distribution of child pornography charge was devoted to the government’s investigative software (called eP2P) and the evidence that was collected by its use. No court has held the investigative source code was material to the defense when the prosecution’s case-in-chief does not include evidence collected through the software.15
The demand for source code review in civil cases has resulted in an industry of source code review companies offering experts who can conduct code reviews and testify in court proceedings. Often the code being reviewed is proprietary and may contain information like trade secrets, so the source code is made available only on a secure machine, disconnected from any network, sometimes at one of the parties’ representatives’ offices. The parties often agree to provide the same set of tools to be used in the code review that the programmers used to develop it, or sometimes an even more minimal subset of similar tools is chosen by the legal representatives without expert guidance.
Programmers need to change code, however, to create new features and then turn those into a working, executable program. Source code reviewers usually
13. Bookout et al. v. Toyota Motor Sales USA Inc. et al., No. CJ-2008-7969, verdict returned (Okla. Dist. Ct., Okla. Cty. Oct. 25, 2013).
14. Realtime Data L.L.C. v. MetroPCS Tex. LLC, No. 12cv1048-BTM (MDD) (S.D. Cal. May 25, 2012).
15. See United States v. Pirosko, 787 F.3d 358 (6th Cir. 2015); United States v. Hoeffener, 950 F.3d 1037 (8th Cir. 2020); United States v. Arumugam, 2020 WL 949937 (W.D. Wash.); United States v. Feldman, 2015 WL 248006 (E.D. Wis.).
have different needs, as their goal most often is not to create or redesign code. Instead, the focus is on being able to read existing code easily to understand the underlying algorithm, to search the code for features, and to print code for reference in a way that allows ease of reference in legal discussions. This goal requires a different set of tools that focus on reading and searching code. For example, doxygen is a tool that converts source code to non-editable local files that can be opened as web pages that include the file name and line numbers for easy reference to the original source, and dngrep is a free tool that can conduct fast searches.
It is worth noting that the term “source code” might refer to different things depending on context. To a computer scientist, the term typically refers to the programmatic source code that is compiled or interpreted to produce a program. In a legal context, however, the term commonly applies to all files that are produced as part of discovery, which can include many other related files. These often include the following: build system configurations files or scripts, which are used to compile and link together the many modules that make up a large program; code that conducts testing of the program to detect errors; and other files, such as design documents, notes about the code, or histories of when files were added during development. These additional files often provide useful context to a source code reviewer.
Reverse Engineering
Aspects of hardware and code that are protected as a trade secret are subject to reverse engineering, in which others attempt to discover the secrets through independent discovery. Kewanee Oil Co. v. Bicron Corp.16 established that trade secrets do not receive patent protection and that it is legal to reverse engineer items in the public domain.
Reverse engineering is also used as an innovative tool for chip design. In 1985, Congress passed the Semiconductor Chip Protection Act (SPCA),17 which protects semiconductor design while providing a reverse engineering provision that allows copying of the entire chip design. The law does not distinguish between the protectable and nonprotectable portions of the chip as long as the copying is for the purpose of teaching, evaluating, or analyzing the chip. The law was written to specifically protect industry practice and encourage innovation. In intellectual property litigation where chips appeared to be similar, Congress assumed that admitting expert testimony to assist in determining whether subtle changes in a chip layout (called a “mask work”) were significant would resolve the problem of distinguishing a copy from a legitimate reverse-engineering attempt in most cases.18
16. 416 U.S. 470, 94 S. Ct. 1879 (1974).
17. 17 U.S.C. §§ 901–904 (1984).
18. Altera Corp. v. Clear Logic, Inc., 424 F.3d 1079 (9th Cir. 2005).
Reverse engineering of software is often prohibited. License agreements and non disclosure agreements can limit the right to work with software to determine its function. A copyright owner can disallow making copies of a work for reverse-engineering purposes. The Digital Millennium Copyright Act (DMCA) prohibits “circumvention of ‘technological protection measures’ that ‘effectively control access’ to copyrighted works.” In some cases, however, it has been found legal to reverse engineer software in particular circumstances, primarily to provide interoperability between systems.19
Overview of Cryptography
With a basic background of computing hardware and software complete, we move toward a brief description of the cryptographic mechanisms that have become essential tools for securing information stored on computers and transmitted across networks. These algorithms are fundamental to many areas of computer science as they relate to legal issues. We introduce concepts here that appear in later sections.
Encryption is used to maintain the secrecy of information. Encryption can be a legal issue when, for example, critical evidence is held inaccessible within an encrypted file. Cryptographic hashing algorithms are widely used to preserve the integrity of data and to recognize known content accurately and easily. Cryptocurrencies are complex networked systems that can allow transfers over the internet of funds that have public value without the involvement of financial institutions; their rise has enabled new types of criminal activity and new ways to launder money.
Encryption
The most common way to ensure the confidentiality of data is to encrypt it. The net effect of encryption is to take a large secret (the data being encrypted) and reduce it to a small secret (the key used for encryption). This approach makes handling sensitive information easier, as data can be stored and transported securely on the open internet in an encrypted form. In general, if the data is obtained by others, it will remain confidential as long as the key remains a secret. The keys are transported by a separate, more secure mechanism, which is easier because they remain small regardless of the size of the data. The terms passwords and keys are similar concepts but often used differently. The term password most often refers to a collection of characters that can be entered with a keyboard (letters, numbers, and punctuation) and are human-readable. A key is a more general term as the collection can contain additional values that cannot be entered
19. Sega Enters. v. Accolade, Inc., 977 F.2d 1510 (9th Cir. 1992); Sony Computer Ent. v. Connectix, 203 F.3d 596 (9th Cir. 2000).
with a keyboard, or perhaps a collection of values that is too long for a human to reasonably enter. In other words, the set of possible keys is much larger than the set of possible passwords. Keys are best chosen randomly, but they can be derived from passwords when needed so a human can remember them more easily.
When we encrypt data, we are altering data so that it no longer has any visible structure. The process of alteration is governed by the encryption algorithm and the encryption key chosen. Taking the original bits, referred to as the plaintext, and running them through the encryption algorithm with a given key produces the ciphertext. A good encryption algorithm produces a ciphertext that appears to have been generated completely at random. When we later want to recover the plaintext, we decrypt it by running the ciphertext through the encryption algorithm with the correct key.
If the algorithm works correctly, the secrecy of the data lies entirely with the key. For proven encryption algorithms the operations are publicly available and the best-known attack is to painstakingly attempt every possible key. We say that information is secure if an adversary cannot possibly attempt all keys in any reasonable amount of time given the resources (i.e., time and money) they have available or before the information loses its value. The number of possible keys for modern algorithms is so large that it is impossible in practice to search through all of them for the correct one, as we discuss below.
Shared Key Encryption
Algorithms that use the same key for encryption and decryption are called shared key or symmetric key algorithms. The standard shared key algorithm today is the Advanced Encryption Standard (AES), which is commonly implemented in hardware on many modern computer CPUs to increase performance.
While shared key encryption is common and efficient, it does have its drawbacks. The primary one is that if you want to have secure communication with many independent people, you need to share a different key with each individual separately. A simpler approach to this key management problem is to use public key encryption, as we describe below. The advantage of shared key encryption algorithms is that they are generally much faster than public key algorithms.
Public Key Encryption
Public key encryption algorithms use a linked pair of keys: anything encrypted with one key can only be decrypted using the other key. It is called public key encryption because one of these keys—the public key—is not kept secret. The other key is the private key and is kept secret by the owner. The advantage of this approach is that everyone who wants to send a confidential message to a recipient can
use the recipient’s public key for encryption; pairwise keys between individuals are not required as they are in shared key algorithms. All messages can be decrypted by the recipient using their private key.
Public key algorithms are based on the fact that mathematically there are problems that are difficult to solve but very easy to check if a solution is correct. By analogy, it is easy to see that a jigsaw puzzle has been solved; but it takes effort to complete a puzzle given a bag of pieces. A real cryptographic example is that given two large prime numbers it is easy to multiply them together to determine if their product is equal to a third value. But given a large number alone, it is difficult to factor out the original prime numbers. One of the original public-key algorithms, called RSA after the initials of its inventors, was based on this factoring challenge. Other algorithms are based on similar mathematical problems that are easy to solve for the person who has the private key but essentially impossible to solve without it.
Because these algorithms work differently than shared key algorithms, the key size is not an accurate indicator as to how long it would take to search for and find an unknown key, and because of the mathematical operations that need to be performed, public key encryption is often much slower than shared key encryption. It is also possible that some breakthrough in mathematics or computer science will render a previously difficult to solve problem suddenly easy to solve, making any algorithm based on that problem immediately breakable. Common public-key algorithms include RSA, elliptic curves, and El Gamal.
Cryptographic signatures
Public key encryption can also provide proof of who sent a particular message, called a digital signature. The basic idea is that if someone encrypts some data with their private key, decrypting it with the known public key verifies it was encrypted by the private key owner. Proving it was encrypted with the private key is therefore equivalent to the private key holder signing it (under the assumption that the private key would never be disclosed by the owner). For convenience and speed, some digital signatures do not encrypt the entire document. Instead, a cryptographic summary of the document is computed (called a hash, as described below), and that is encrypted. The hash is small and unique to the document being signed. Not all cryptographic digital signatures operate this way, but it’s a good high-level model for understanding how digital signatures are computed.
Certificates
One problem with public key cryptography, however, is verifying who owns a particular key. This verification must be managed by computers, be performed
in milliseconds, and be mathematically based. The common solution to this is the use of cryptographic certificates, which make use of digital signatures to verify public key ownership; certificates provide much of the cryptographic foundation of the internet. Individual operating systems or software, such as web browsers, are preloaded with root certificates. These certificates are, in short, the public key of trusted organizations that serve to verify other certificates. In this hierarchical system of trust, a shopping website would create a public key to include it in a certificate of its own, and then pay one of the root certificate organizations to sign it. Consumers are trusting the root certificate organizations to sign with integrity.
For example, when a secure connection is made over the internet to shop using a web browser, the shopping website presents its own certificate to the browser. As described above, this certificate contains the public key for the shopping website and a digital signature from one of the root certificate organizations. The browser uses one of the preloaded root certificates to verify the trusted organization’s signature on the shopping website certificate. When the browser finds that the shopping site certificate is correctly signed, it then trusts that the shopping site certificate belongs to the shopping site (and not some impostor) and that it is safe to conduct transactions. The site public key is then used to exchange a shared key used during only this session for encrypting the transactions between the user’s browser and the shopping website. The actual process has a few more steps, including some intermediate certificates and keys, but conceptually the result is the same.
Cryptographic Key Sizes and Attacking Encryption
Cryptographic operations depend on the fact that the number of possible keys and hashes are so large that they represent values far outside human experience. Each key or hash is a series of individual bits, each a single 1 or 0 value, often hundreds of bits long. Each time a bit is added, the number of possible combinations for the series doubles. By the time the length of the series is 128 bits, the number of possible combinations is 2128 which is about 1038 (or 1 followed by 38 zeros). To put this in perspective, some estimates put the number of grains of sand on the earth at about 1024. In other words, there are about 100 trillion times as many possible values for a 128-bit sequence than grains of sand on earth. Moving to 256 bits or 512 bits produces combinatorial sizes that are even less comprehensible. A sequence of 256 bits produces about 1077 possibilities; for 512 bits the set of possibilities becomes about 10154.
Breaking encryption for these size sequences by trying all keys is impossible; there is not enough computational power to do so nor is it possible to create
enough computational power to do so. If keys or hashes are random then they are incredibly unlikely to be broken this way.
Attacking Encryption
It is impossible to try every possible key to attempt to decrypt something encrypted; there are too many keys to try as bounded by the laws of physics. For that reason, when users let their computers pick their keys or passwords randomly then decryption through automated guessing will not work. On the other hand, people are frequently not random when picking their own passwords, and they are often poor at securing the storage of those passwords. For example, passwords might be based on pets and birthdays and be written down in a notebook, or on a scrap of paper, or recoverable from a computer memory or disk. In these cases, there might be some hope that the password might be recovered. It is also possible to try and brute force passwords by repeated guessing. Humans often use statistically predictable patterns, and software exists that will work through trillions of combinations of statistically probable passwords to see if they create a key that can be used for decryption; this approach can be very effective for poorly chosen passwords, and very ineffective for randomly created ones.
In cases where the password is not recovered, it might be possible to get it from the user.20 Some courts have reached a variety of conclusions whether a court can issue an order to compel disclosure of a password or even compel someone to unlock a device. Some courts hold there is no Fifth Amendment violation to compel a password’s disclosure if the ownership of the device is a foregone conclusion.21 Other courts have explicitly refused to apply the foregone conclusion doctrine and denied orders to compel disclosure of passwords.22
20. Orin Kerr, Compelled Decryption and the Privilege Against Self-Incrimination, 97 Tex. L. Rev. 767 (2019).
21. See, e.g., United States v. Apple Mac Pro Comput., 949 F.3d 102 (3d Cir. 2020) (court upheld court order under the All Writs Act compelling disclosure of password under the foregone conclusion exception to the Fifth Amendment); State v. Andrews, 234 A.3d 1254 (N.J. 2020), cert. denied, 141 S. Ct. 2623 (2021) (the foregone conclusion exception allows the defendant to be compelled to communicate his memorized passcodes to the government); Commonwealth v. Jones, 481 Mass. 540 (Mass. 2019).
22. See Seo v. State, 148 N.E.3d 952 (Ind. 2020) (discussing concerns with extending the foregone conclusion exception to the Fifth Amendment in the context of compelling production of an unlocked smartphone); Commonwealth v. Davis, 220 A.3d 534 (Penn. 2019) (foregone conclusion exception to the Fifth Amendment is inapplicable to compel the disclosure of a defendant’s password to assist the government to gaining access to a computer).
Cryptographic Hash Functions
A cryptographic hash is a mathematical function that takes any digital content as input of any length and produces a short unique numeric signature as output, typically 512 bits or fewer. This reduced number of bits, which is often referred to as the hash, is like a digital summary or identifier of the content that was input. Changing any single bit in the input changes the output hash significantly and unpredictably. We can therefore use hash functions to verify the integrity of large amounts of data, at any input size, at a level of granularity involving single bits. Good hash functions have the following properties that ensure the hash is secure:
- First, given a hash, it is not possible to recover the original data. This means that you can share the hash with anyone, and they cannot tell what was used to create it. If you give them the original data, though, it is easy to run those through the hash function to ensure that they are the same. Hashing is a one-way function.
- Second, given a hash, it is virtually impossible to find any other content that produces the same hash when run through the hash function. This property is related to the size of the hash output in bits: increasing the length of the hash output increases the difficulty of finding other content.
- Third, it is very difficult to create two different digital objects that have the same hash. This task isn’t as hard as the second property, as we describe below, but it is still very hard for good hash functions. (By “hard” and “difficult” we mean that an adversary cannot acquire sufficient computing resources to achieve the desired result with even the smallest probability of success.)
Cryptographic hashes have myriad uses, the most common as digital summaries. To detect changes to a file, the hash of a file or other digital object is taken and recorded separately from the object itself. Later, the hash can be recomputed from the object or a copy of it. If the object has changed, then the hash will have changed. Similarly, no two objects will have the same hash value, as described above.
Accordingly, hash values are an important tool used in e-discovery as they provide a guarantee for the authenticity of an original data set and can be used as a digital equivalent of the Bates stamp used in paper document production.23 Amendments to Federal Rule of Evidence 902 provide a procedure to authenticate electronic documents without calling the testimony of a witness. Committee notes to the 2017 amendment specifically point to the use of hash values to self-authenticate, relying only on a certification by a qualified person that they checked the hash value of the proffered item and that it was identical to the original.
23. Managing Discovery of Electronic Information 52 (Federal Judicial Center Pocket Guide, 3d ed. 2017).
Attacking Cryptographic Hashes
There are a variety of commonly used hash functions. Some older ones, particularly MD5 and SHA-1, have been shown to be weak or broken in ways that newer hashes such as SHA-256 are not. Specifically, attackers can violate the third property above and produce multiple data files that have the same cryptographic hash.
In contrast, for cryptographic hash algorithms that have no known weakness, the chance of generating a second file that has the same hash as a given, fixed first file is vanishingly small. For example, given a file with a particular cryptographic hash value that is n bits long and violating the second principle above, one would expect to have to generate 2n candidate files before finding a match. For example, when using SHA-256, which produces a 256-bit output, one would have to generate 2256 (roughly 1076) candidate files before expecting to find a match, which is essentially impossible in practice.
The process of creating hashes is subject to the so-called birthday attack, however, which violates the third property above. This attack is so named because while the chance of any one specific person having a set birthday is 1/365 (ignoring leap years), the chances that some two people in a group of 23 having the same birthday is about 50%. In the first case, we have fixed on a single birthday date; in the second case, any matching birthday date achieves success. These are analogous to principles one and two above. Producing a large set of random digital objects will produce two objects that have the same hash more often than when fixing a file to match against. Specifically, one would expect to generate 2n/2 candidate files to find any pair that match from among all generated candidates. In the case of SHA-256, finding a matching pair requires generating 2128 (roughly 1038) candidate files in expectation, which is still impractical.
Hash values are also used by electronic service providers to detect images of apparent child pornography. They typically configure their systems to watch for such images being transmitted or stored across their networks by computing hashes of the images and comparing them against hashes known to be illegal.24 It is, however, easily possible to make alterations to the image that will not be visible but would change the hash.
Cryptocurrency
Cryptocurrencies have become the de facto standard form of conducting online payments for many illegal activities; in addition, there seems to be a growing
24. See United States v. Miller, 982 F.3d 412 (6th Cir. 2020) (analyzing Fourth Amendment concerns when Google used hash values to identify images of apparent child pornography transmitting across their network).
number of financial fraud cases involving cryptocurrency companies. In this subsection, we provide a very brief overview of how Bitcoin, the original cryptocurrency, works. There are many different cryptocurrencies that are based on a variety of cryptographic principles, but others are often similar in their design.
The fact that many cryptocurrencies have “coin” in their name is misleading. Instead of tracking individual currency units, most cryptocurrencies instead operate on the concept of a shared ledger. On this ledger there are a series of identifiers called addresses (analogous to a bank account number) that are each associated with an amount of cryptocurrency; the ledger is essentially a shared database that maps addresses to the cryptocurrency balance. This approach is as if a bank kept track of how much money is in an account without recording the serial numbers of any cash deposited and without attaching a name to the account.
Transactions cause some portion of a balance to be transferred from one address to another and recorded on the ledger. This ledger is called the blockchain and contains a history of every transaction that has ever happened in Bitcoin (or other cryptocurrency). By processing through the list of transactions listed on the blockchain, anyone can determine the balance associated with any address. In Bitcoin, each address is a public cryptographic key. Only the person who knows the corresponding private key may create transactions with that identity. Transactions are analogous to bank checks: they transfer currency controlled by one private key to the control of a different private key. One person might have control of any number of addresses. Transactions, however, are not anonymous in that they are inseparable from the addresses listed in the ledger. It is often possible to associate these Bitcoin addresses to real-world persons by finding Bitcoin transactions that are associated with real-world financial actions, like purchasing Bitcoin using a bank account or using Bitcoin to order physical items mailed to a postal address.
The major innovation of Bitcoin was to establish a mechanism by which a large group of computers could come to a consensus, without a central organizing authority, on which transactions become part of the blockchain despite some minority of participants attempting to cheat or otherwise influence the outcome. This mechanism, called mining, also creates new Bitcoin, and it incentivizes participation in the Bitcoin protocol, which helps make it resilient against attack.
The value people see in Bitcoin is that it is exceedingly difficult to alter the blockchain; to do so would require a very significant amount of computational power, in general roughly more than about half the computer power already performing mining on a chain; for the more popular cryptocurrencies it’s most often an amount out of reach of any single entity. As long as a majority of participants, as rated by computational power, behave consistently then changing the blockchain should be quite challenging and therefore secure.
For some cryptocurrencies it is possible to anonymize the relationship between currency deposited in an address and later expenditures from that address. This process is often called mixing. Because the blockchain is a public ledger, it can be used by criminal investigators to follow illegal transactions. Blockchain
analytics can become key evidence in criminal activity involving virtual currency. For example, IRS investigators analyzed the blockchain and de-anonymized Bitcoin transactions allowing for identification of hackers compromising celebrities’ Twitter accounts. The affidavit supporting the criminal complaint steps through the blockchain analysis leading to the identification of several co-conspirators.25
Networking
The internet’s core feature is the connections it creates among the world’s people, computers, and devices. The internet is supported by an enormous amount of infrastructure, including: equipment commonly used in homes and offices, such as Wi-Fi access points and cable modems; equipment deployed by internet service providers (ISP) that have home and business customers; and the connections among ISPs that connect the world together. The internet is further extended by cellular network providers, including mobile phones, radio towers, and connecting infrastructure.
It has become commonplace for people to carry mobile phones and devices at all times, and for almost all communications to be based on the internet and modern cellular infrastructure. For this reason, a great deal of evidence and legal issues are based on network communications and services. To understand modern networks and the legal issues surrounding them, it’s helpful to learn a number of fundamental concepts that we explain here.
Networking Layers
The connection of the world’s cellular carriers, ISPs, and end users as one massive system is made possible by a collection of standards called the internet protocol (IP) suite. All computers that speak IP can communicate with each other regardless of the developer and manufacturer responsible for the software or hardware. These protocols are organized as several layers. At the top layer are the applications, such as email and the web. And at the bottom are the wires and cables that carry data. In between are a series of layers that handle reliability, routing, and access control, which are all terms that we define below.
An important aspect of this design is that each layer has its own naming and addressing scheme. An address is a place on the internet that data can go to, while a name is an identifier unique to that address. For example, an email “address” is actually composed of a name (like alice) connected by an @ symbol to an address (like alice@umass.edu).
To help understand the purpose and relationship among these layers, we can make an extended analogy to the postal service. Figure 2 illustrates the five IP
25. United States v. Sheppard, 3:20-mj-70996 (N.D. Cal. 2020), https://perma.cc/5NSR-7QD3.
layers. At the top is the application layer, which consists of protocols that operate between two instances of the same application running on different desktops, laptops, or smart phones. These different devices at the edge of the internet are often called end-hosts. Email clients, web browsers, messaging programs, social media applications, and online multiplayer games and other applications each send data across the network in their own way. Application-level content very rarely is examined or modified by devices on the network. One of the reasons the internet has been able to grow to a world-wide system is that what happens on these end-hosts is largely separate from the core infrastructure. In our postal service analogy, the application layer is like letters and magazines that are mailed: although the content is important to the sender and receiver, the actions taken by the postal system are not affected by the specific words, images, or other content within the letters, and the postal system generally does not examine the content.
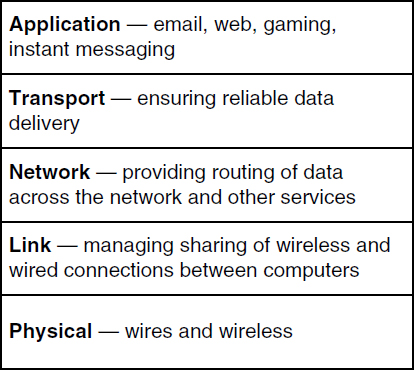
Below is the transport layer, which also operates across the network between the two end hosts. The transport layer corrects problems and errors that are caused by the layers below so that applications see a consistent stream of data. The specific transport-layer protocol that performs these functions is called the Transport Control Protocol (TCP). In our analogy, TCP is like one of the special services that can be purchased from the post office, such as a delivery acknowledgment. For an important letter, you might make a copy of the letter and then send the original. If you don’t receive a delivery acknowledgment after a time, you’ll send a new copy of the letter and reset your timeout for the delivery acknowledgment; at its core, the algorithm providing reliable delivery of data operates the same way.
Next, going downward, is the network layer, which is the first layer that operates on the core devices that form the internet. Whenever information leaves an end host, it is handed off to a router. Just like desktops, routers are computers. The only difference is that they are not computers that are used to run just any program; they are specialized to operate programs that route data from one end host to another end host across a building or across the world. The entire internet is composed of routers that communicate in an unbroken mesh.
Most routers have more than one or two neighboring routers, and so just like roads that intersect with other roads, routers have to be navigated from a starting end host to a destination end host. A series of protocols determine for routers which of its neighbors most quickly leads to a destination. In our analogy, routers are like post offices. When a letter leaves a home, it travels from one post office to the next, until it reaches a final post office that delivers the mail to the destination home. The network layer is responsible for assigning an IP address, and it is often critical to attributing evidence in an investigation.
The link layer manages the connections between routers (and between hosts and routers). For example, the link between a host and its wireless access point can be managed by a Wi-Fi protocol. Stretching our analogy to almost its breaking point, links are like the postal workers that are the conduits for managing the many letters at a time that go from a home to the neighborhood post office, as well as transfers along a sequence of post offices on route to the destination.
Finally, at the bottom, physical layer protocols allow hosts to send data via some physical medium, including wireless, optical fiber, or coax wire. To complete our analogy, the vans, trucks, trains, and airplanes used by the post office are the physical objects that move mail from one point to another.
IP Network and Link Layer Addresses
The two most important computer addresses that are used to move a user’s data across the internet are a computer’s IP address and the address of a computer’s network interface.
IP addresses are assigned by the local network administrator at an internet service provider (ISP). Before data can be transferred by a computer, it must obtain an IP address. They can be assigned once and remain static for the lifetime that the computer uses the ISP. Or, more typically, IP addresses are assigned dynamically by the internet service provider using the Dynamic Host Configuration Protocol (DHCP).
Network interface addresses are assigned at the factory that manufactured the radio card or Ethernet card, and they are typically 48 bits long. They are often written as colon-separated hexadecimal strings: e.g., 00:17:F2:40:F9:B2. The first 24 bits are a prefix that should identify the manufacturer; the second half should uniquely identify the hardware across the world. This value is easily
changed by the user, as we explain below. The link-layer protocols that make use of network interface addresses are called medium access control (MAC) protocols, and so most often the 48-bit values are called MAC addresses.
A person can take their laptop from one ISP to another. For example, a laptop may move from a person’s home ISP to their work ISP, and then to an internet café afterwards, all in the space of one day. Each move will cause the computer to be assigned a new IP address—however, the MAC address will stay the same throughout. A computer’s MAC address is never sent farther than a router or host one hop away, to the neighboring link-connected computers. Across the internet, it will be impossible to learn that one MAC address is behind all three IP addresses at different times.
Typically, a DHCP IP address assignment is logged, including the date and time, network interface address, and assigned IP address. The Communications Assistance for Law Enforcement Act (CALEA) asks ISPs to keep DHCP logs for 90 days, but this is not a requirement under the law. Some ISPs keep information for hours, some for longer than 90 days. Many law enforcement investigations involving a network are led by a search for the computer (and home) that has been assigned an IP address that was observed online. The ISP that assigned the computer needs to be found first, so that the DHCP logs can be requested via legal process.
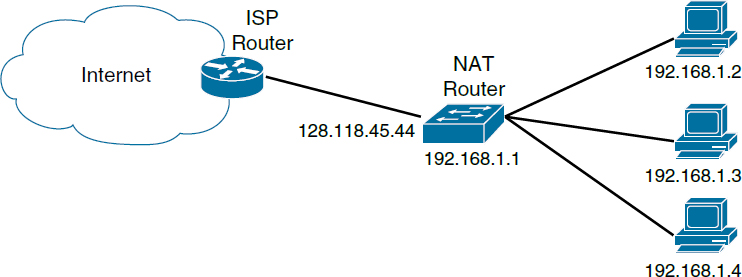
Sometimes an IP address is not a completely unique identifier. There are only 3.7 billion of the shorter (version 4) IP addresses for the entire world, and they are assigned in large blocks by Internet Assigned Numbers Authority (IANA). Given the number of computers in the world, addresses are scarce. Some organizations have tens of computers yet are assigned only one address by their ISP. To get around this problem, many organizations (and home routers) make use of network address translation (NAT) boxes, which allow many computers inside a network to share a single external IP address. Figure 3 illustrates this operation.
Cloud Computing and Serverless Systems
The term cloud computing refers to a popular approach to supporting online computer services. When the web and online services first started gaining popularity, it was common for businesses to operate a computer to serve online customers on their own premises. As the customer base grows, the business would not only require more powerful computing hardware, but investments in air conditioning, physical security, electrical power, redundant hardware, and more. Further, for some businesses, demand might be extraordinarily high for one day and not most of the year; it can be challenging to expand infrastructure for that one day.
Cloud computing addresses these issues for businesses. Cloud providers build large data centers that provide power, network access, and cooling for many thousands of computers. Typically, there are staff onsite to provide security and help deal with hardware problems. The computers used in these centers are different than laptops and desktops. Called rack servers, they are shaped more like elongated pizza boxes so they can stack neatly, as shown in Figure 4. They often include remote management interfaces so that they can be configured and operated across the network without a human needing to be present, but humans are required to address hardware problems.
 Source: Provided by the U.S. Department of Energy’s National Energy Technology Laboratory, https://perma.cc/VGR4-URGD.
Source: Provided by the U.S. Department of Energy’s National Energy Technology Laboratory, https://perma.cc/VGR4-URGD.When the notion of cloud computing was introduced, it was common to lease a complete virtual machine above, and this is still done. More recently, cloud providers realized that they could charge for hosting a specific program. For example, the program might accept a photographic image as input and return the text that appears in the image as output. This approach, called serverless computing, allows the cloud customer to avoid paying for an idle virtual machine. Instead, they pay for each execution of their program. The cloud provider ensures that as demand ebbs and flows, the execution of the program remains performant and reliable. Large providers of such services include Amazon Web Services, Google Cloud, and Microsoft Azure. Businesses can lease computing power from the provider and scale up or down quickly as demand for their product changes.
Cloud services are a good example of what is defined as a remote computing service (RCS) in federal law.26
Wireless Networking and Mobile Devices
Wireless networking is commonly of two primary types. Cellular networks support long-range communication between a user’s mobile device (e.g., a smart phone) and radio towers that can be miles away. Wi-Fi networks support short-range communication between a user’s mobile device and access points (AP) that can be hundreds of feet away. Bluetooth networks are similar to Wi-Fi but typically operate over an even shorter range. There are many other types of wireless networks, including satellite-based communication, that we do not discuss here.
Wireless communications are typically broadcast in nature and based on radio waves. The physics of the radio frequencies involved and the expense of the equipment determines whether the signals can permeate walls or travel long distances. For example, cellular networks are based on very large antennas situated on very large towers. Wi-Fi networks are based on small antennas affixed to boxes placed on shelves in homes. The difference explains the large geographical ranges that cellular networks can traverse compared to Wi-Fi networks. Given that wireless signals will be received by anyone within range, cryptography is typically used to keep communications confidential between the two parties communicating over the wireless channel.
26. See the definition of remote computing service, 18 U.S.C. § 2711(2).
Cellular Networks
Cellular networks are deployed across large geographic areas to allow for a user to be mobile and stay connected. Originally, cellular networks were deployed to support voice phone calls. Over time, the networks have evolved to support the data connections required by internet-enabled apps and services common on smart phones.
To enable cellular service, towers or other installations with antennas are connected to the provider’s network over backhaul connections that go over cable, fiber optic, or microwave links. Each tower that a cellular provider deploys covers a geographic cell in which users have connectivity. The towers are often called cell sites. The towers are connected to a complex set of systems that route data to users and ensure that only paying, authenticated customers have access. Commonly, a subscriber identity module (SIM) card is issued by the cellular provider and inserted into the user’s mobile device. The SIM card uses cryptography to authenticate the user’s subscription. Records held by the cellular provider link the user’s identity and billing information to the SIM card. The mobile device has an International Mobile Equipment Identity (IMEI) assigned to it.
As cellular networks have advanced in terms of range and available bandwidth, they have changed names, including 2G, 3G, LTE, and 5G. These names represent a combination of changing technical specifications and marketing efforts. The basics have remained the same even if internally the industry has changed its terminology continually. Therefore, we will describe these basics in high-level terms.
When a user powers on a mobile device, the device seeks out a nearby cell site. Using the credentials held in the SIM card and via a well-defined signaling protocol, the device authenticates to the cellular provider. As the user moves, the device will associate to a new tower with a stronger wireless signal. Voice calls and data are routed to the tower the device is associated with. Typically, the provider stores a record of these associations called cell site location information (CSLI). If a device is in range of three or more towers, the device’s geographic position can be estimated from the signal strengths. This estimation can be performed after the fact if the signal strengths are recorded, or it can be performed in the moment and the estimation stored in a record. Alternatively, if the mobile device contains Global Positioning System (GPS) functionality, it can tell the cellular provider of its location. Geographic location is not required to provide wireless communications; it is required to assist with calls to emergency 911 services.
The internet includes mobile devices attached to cellular networks. These devices typically are assigned an IP address via the cellular provider’s NAT gateway. Some cellular providers keep records of these NAT assignments; some do not. The amount of time these records are kept by providers also varies.
Wi-Fi
Wi-Fi is a commercial term for a series of industry standards for short-range wireless communication among computers and mobile devices. Wi-Fi networks are inexpensive for consumers to deploy to cover part of a living area with one central access point (AP). With several coordinated APs, a large home can be covered. The same technology can be scaled up to cover a large building or campus. Typically, the Wi-Fi AP includes NAT and security functionality.
Many consumer devices are available that serve a single purpose and are designed to connect to the user’s Wi-Fi network. These so-called internet of things (IOT) devices include services such as monitoring and adjusting temperature and lighting, controlling door locks and entryway cameras, and managing smoke alarms and other sensors. Some IOT devices connect to each other, smartphones, and desktop computers via Bluetooth wireless technology. Bluetooth was designed to allow for very short-range connections between devices, replacing short cables. Bluetooth operates very differently than Wi-Fi internally, but it includes the same concepts, such as a MAC address and broadcast radio waves.
Network Architectures
The classic architecture used for coordinating the communication of a large set of computers over a network is called client-server. A single server acts as the single point of coordination of all communication, and the multiple clients never transmit data to one another. The burden of work is on the server, which must be a machine that is provisioned with significant network bandwidth, disk storage, and processing. However, the reliance on a single point of coordination results in a system that is easier to control and manage, i.e., there is little complexity to the clients’ operation and design. Figure 5 illustrates this architecture.
Peer-to-peer (p2p) network systems are possible because home computers have sufficient resources, having access to high-bandwidth home internet connections. Peer-to-peer systems allow a group of clients to pool their resources and offer a networked service to each other, even though no single client has sufficient resources to act as a server. The disadvantage of peer-to-peer is an increase in complexity at each peer: each plays the role of a client and a server. The details of how a particular peer-to-peer network operates can be complex for that reason. Figure 6 shows a possible p2p architecture.
Peer-to-peer applications are a popular way of sharing content with other users without relying strongly on a centralized server. Because there often appears to be no central computer in charge, many users of p2p applications believe that they have relative anonymity. While it is more difficult for investigators to examine these systems, they are not anonymous, as the efforts of the recording
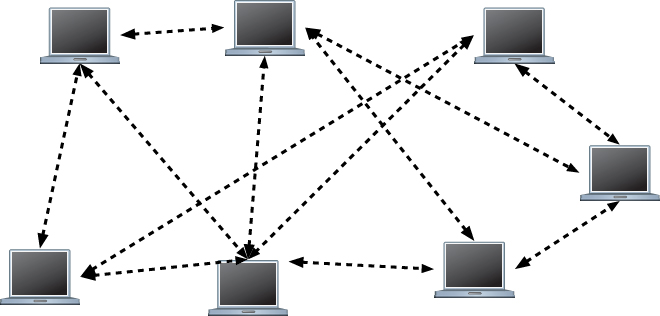
industry have shown.27 We discuss applications specifically designed to provide anonymity on the internet, including Tor, below.
Peer-to-peer applications are widely instrumental for the sharing and distribution of files containing copyrighted music, videos, and software, as well as child sexual abuse material (CSAM). BitTorrent is the primary p2p file-sharing
27. A&M Records, Inc. v. Napster, Inc., 239 F.3d 1004 (9th Cir. 2001).
application in use on the internet today. Others include eMule (also called eDonkey), Ares, and Gnutella.
Anonymity and Obfuscation
Whenever a computer uses the internet to directly connect to another computer, its IP address is revealed. To obfuscate their address, one of the senders could use a third party. For example, Alice may communicate to Carol with the help of her friend Bob as an intermediary. In this subsection, we explain the most prominent methods used for obfuscating IP address information.
Open-Access Wi-Fi
The simplest method of obfuscating one’s real IP address is to make use of open-access internet connections, such as free Wi-Fi offered by cafés and other businesses, or by libraries and other municipal services. Free Wi-Fi is almost always provided using network address translation (NAT); see section titled “Network Address Translation,” above. An inexpensive Wi-Fi access point providing the connection and the NAT service that might be used by a small business or home typically do not have logs of the device that was provided service. For someone seeking obfuscation from free Wi-Fi, the disadvantage compared to other mechanisms is that they must be in physical proximity of the Wi-Fi. Their image or their vehicle’s image may have been caught on security cameras. And some Wi-Fi services require registration via an email address, which can be a lead to start an investigation of illegal activity.
Virtual Private Networking (VPN)
Virtual Private Networking (VPN) services work similarly to hide IP addresses. In this example, we describe how entities can communicate while hiding their IP address. We do this in a manner common to computer science, where entities referred to as “Alice” and “Bob” and others participate in communications.
Alice can hide her IP address from Carol’s computer if she sends her communications through Bob’s VPN service. Alice’s computer connects to the VPN endpoint (also called a VPN concentrator) administered by Bob, and all traffic she sends is encrypted so that it cannot be read or altered by others. Many businesses make use of VPN connections to allow their employees to work remotely. In these scenarios, “Bob” is the company that “Alice” works for. A VPN connection from an employee’s home computer to systems administrated by the business ensures the communications over the internet are confidential. Furthermore,
such connections can involve credentials that are issued only to the employees, ensuring the connections are authorized.
In other scenarios, “Bob” is a company that sells VPN services as a proxy that offers privacy to users like “Alice” who pay for the service. When Bob’s VPN endpoint receives Alice’s communications, he sends it to Carol’s computer with his own IP address as the sender. Thus, Carol learns the IP address of Bob and not Alice. In these scenarios, Alice trusts Bob with the knowledge that she is communicating with Carol. While Alice has an active communication with Carol, Bob’s VPN endpoint has to keep track of the connection so that return traffic from Carol can be routed to Alice. Once the communication is over—for example, after a single web page is retrieved—the record of the connection can be disposed of. Many commercial VPN service providers advertise a “no logs policy,” which means that the record of past communications is not kept by the VPN service provider. Bob is providing a more secure service for Alice by erasing logs that might be discovered by third parties that seek to monitor Alice’s communications. If Alice’s interest in Bob’s services is to obfuscate her illegal activities, then a no logs policy is similarly advantageous. For example, VPN services are known to be hurdles for investigations into child exploitation.
Anonymous Communication Systems
Several services on the internet were designed to provide stronger obfuscation than free Wi-Fi and VPN services. The Tor Project has created software that is used by volunteers on thousands of computers worldwide. Each computer is called a relay. This peer-to-peer network of relays is called the Tor Network and supports two systems for anonymous communication. The first is Tor Browser,28 which is by far the most prominent system that can be used to browse internet websites without revealing the client’s IP address. The second is Tor onion services, and it is used to prevent disclosure of a server’s IP address. A variation of the approach used by the Tor Project is employed by the Invisible Internet Project (i2p), though it is less popular than the Tor Project. The i2p system comprises a set of relay computers that are distinct from the Tor Project. Freenet is another lesser-used obfuscation service that operates differently from the Tor and i2p systems.
The term “darknet” or “dark web” is often used by popular media to describe services that obfuscate a user’s IP address, but it is a poor word choice.29 The term
28. Roger Dingledine, Nick Mathewson, & Paul Syverson. Tor: The second-generation onion router, in Proc. Conf. on USENIX Security Symposium, 2004.
29. This text based in part on “Increasing the Efficacy of Investigations of Online Child Sexual Exploitation: Report to Congress,” Brian Levine, May 2022. NCJ Number 301590, https://perma.cc/WA8J-SURQ.
darknet originally referred to the fact that the content made available by these services is not indexed and made searchable by sites such as Google and Bing, hence the content is “dark” and not easily found. It is more instructive to consider the purpose and structure of the services. The Tor Network is designed to thwart the ability to attribute the content of traffic from the user. VPNs, which we describe above, are single-proxy systems for obfuscation. Tor and Freenet are multi-proxy anonymous systems for IP address obfuscation (anonymous systems, for short). Tor and Freenet are peer-to-peer networks, and they are possible because volunteers operate internet-connected computers running the software. Software for Tor and Freenet is free and does not require users to register or identify themselves with a central authority. Consider that in contrast to using a VPN where users typically register with a VPN service provider, likely submitting a form of payment such as a credit card number.
Tor Browser is similar in function to a single-proxy VPN service in that a remote web server can be contacted without revealing the IP address of the Tor user’s computer, as illustrated in Figure 7. Unlike a VPN service, Tor Browser uses three Tor relays in sequence. Communication is encrypted in layers so that each relay knows only the previous and next steps in the chain. The clear internet destination of the communication is known to only the last relay, called an exit node while the exit node does not know the IP address associated with the initial sender. The destination web server is unable to learn the IP address of the user. The guard node does not know the destination’s IP address; the exit node does not know the user’s IP address; the guard and exit are separated by the middle node. Tor relays do not keep logs about the connections formed, and because the service is operated by volunteers it is free. Tor Browser provides anonymous internet connectivity in that it hides the IP address of the user’s computer but does not modify the content sent.

Tor onion services, previously called “hidden services,” allow for a website (or any server) to hide its IP address from users that communicate with it. The site is behind three relays, awaiting web requests. As illustrated in Figure 8, the requests can come from Tor Browser users only. (A version of onion services is present in i2p, and they are referred to as eepsites.)
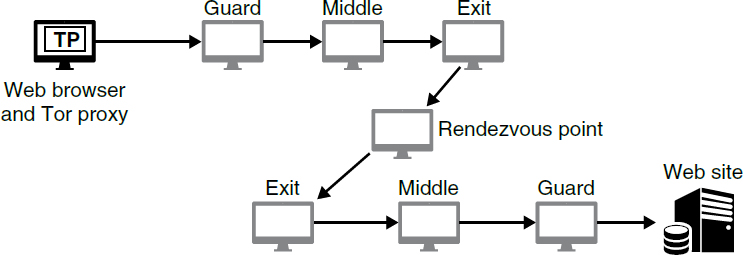
Freenet30 is much less popular than Tor, but it is used daily by thousands of users. Freenet provides an anonymous service where users can publish and retrieve files. It cannot be used like Tor Browser or a VPN service to connect to the clear internet. Freenet can only retrieve content that has been previously inserted in Freenet’s system by other users, and in that sense, it is akin to Tor onion services. Freenet attempts to prevent attribution of downloads using an approach that is different from Tor; we do not detail its operation here.
Network Identifiers and Third-Party Data Collection
All told, a tremendous number of layered mechanisms allow for the internet, mobile communications, and modern apps and websites to work seamlessly and reliably. Each layer typically makes use of various network names and addresses that uniquely identify a device or its user. The IP address of a device is the most obvious example, but many more are present and often contribute to the evidence in a case. Below we provide a glossary of the more common identifiers.
IP addresses used on the public internet are attributable to a particular internet service provider (ISP) via public records. ISPs are given a contiguous range of addresses in a block, which they can assign to their customers. As described above, it’s possible that one address can be shared among many users as part of a NAT setup, whether within a home or business. Often IP addresses are associated
30. Ian Clarke et al., Freenet: A distributed anonymous information storage and retrieval system, in Designing Privacy Enhancing Technologies, pp. 46–66, 2001, https://doi.org/10.1007/3-540-44702-4_4.
with a billing record that has a street address and credit card information. Logs of the assignment of an address to a customer usually exist, but no law requires that they be stored or retained. For example, many VPN providers do not keep records.
Email addresses are one of the oldest identifiers on the internet. Typically, email addresses are secured by an email provider with a password, and logs of access to the account often exist. It is a challenge to authenticate the true sender of a received email from the email alone. A log of the sending of the email or a copy on the sender’s computer is stronger evidence.
Cellular phones have a series of identifiers. These include the following: unique phone numbers, which are assigned by the provider; International Mobile Equipment Identity (IMEI) that uniquely tag a hardware device; and the International Mobile Subscriber Identity (IMSI) that uniquely tags a particular SIM, which is a small card containing tamper-proof electronics issued by the cellular provider and inserted in the mobile device. Typically, providers keep track of all three values (and more) and the calls and connections to cell tower base stations for each device.
Almost all computers are connected to the internet via a shared network at the link layer (see section titled “Networking Layers,” above). Wi-Fi and cellular connections are almost always shared with other computers. Wired Ethernet connections are also typically shared. In all these cases, each device on the shared wireless or wired medium is identified by a unique medium access control (MAC) address. While usually globally unique, a MAC address can be changed quite easily by the user and is often not shared beyond the local network.
As users browse the web, the websites they visit store small amounts of information within their browsers. Generally, this information is called a cookie, and more broadly there are many ways for a website to store data on a user’s device. The stored information can be useful for the website to reidentify visitors and store preferences. Some mobile phones and some desktop devices are assigned unique advertising IDs (AdIDs) and other identifiers that identify the user’s devices across different apps. These values can be cleared easily by the user, but many users do not.31
Within some systems, there may be other identifiers that are stored internally to track user activity. For example, web-based systems that require users to log in typically assign each user an internal identifier. The identifier is often a number that is used to look up the user’s information in a database. Each action the user takes, which can vary by system, is linked to this identifier. For example, posts in social media systems will be linked to this identifier. The identifier is typically logged each time users perform an activity, from creating the account
31. Keen Sung et al., Re-identification of mobile devices using real-time bidding advertising networks, in Proc. ACM International Conference on Mobile Computing and Networking, September 2020, https://doi.org/10.1145/3372224.3419205.
to each time they log in, and each post or comment they make. Given some information about the user, a site administrator should be able to retrieve the business information they have collected on the user. The resulting data will vary by what each site has determined to collect and keep.
Most of the identifiers above are assigned or stored by third parties (e.g., advertisers and app platforms), as their purpose is to globally distinguish the user or their device. Thus, it can often be key information in both civil and criminal cases. It is common for these values to be both stored on a device and with a third party. The legal process required to obtain the information of course depends on many factors, including who holds the information sought, whether the information is provided in real time during transit or if it is stored prior to disclosure, and how the information is categorized by law (e.g., content, subscriber information, or other records). Several statutes may come into play here, including the Stored Records Act (18 U.S.C. §§ 2701–2710); Pen Register and Trap & Trace statute (18 U.S.C. §§ 3121–3126); and the federal wiretap act known as Title III (18 U.S.C. §§ 2510–2522). The Department of Justice’s Guide to Searching and Seizing Computers32 is a good resource to step through the application of these laws to obtain the various forms of identifying information discussed here.
Geographic information is a part of many networking systems and apps at various levels of granularity. Global Positioning System (GPS) information is the most accurate type of information. GPS coordinates are determined by devices based on signals received from orbiting satellites. The accuracy of a position can be within tens of feet under perfect conditions. However, tall buildings and other occlusions can reduce the accuracy.
Not to be confused with GPS is the concept of IP address geolocation, which is a method by which the geographic location of a device is estimated by its IP address. Geolocation accuracy varies widely depending on many factors. It can be accurate for IP addresses assigned for a long duration of time to places with a fixed location, for example the IP address assigned by an ISP to a home. IP address geolocation can be inaccurate and misleading if used incorrectly,33 and it is inherently inaccurate for devices on cellular networks or connected to a VPN service.
The geographic location of a mobile device might be discovered via cell site records kept by cellular providers. As devices roam the cellular network, they attach to radio towers (also called cell sites) that have the strongest signals. Since the towers are in fixed locations, knowing the tower a device was attached to provides information about the device’s location. If several towers are within range of a device, then it is possible to estimate the location more accurately. Specifically, a device’s location can be triangulated among three or more towers. To do
32. Available at https://www.justice.gov/criminal-ccips/ccips-documents-and-reports.
33. Cyrus Farivar, Kansas couple sues IP mapping firm for turning their life into a “digital hell,” Ars Technica, Aug. 10, 2016, https://perma.cc/MUZ4-YMFM.
so requires the signal strength information from the towers, either in real time or as part of a stored log.
It can be instructive to consider the context of each of these identifiers and other information that is a part of typical computer use and internet communications. Dialing, routing, addressing, and signaling information is abundant in network communications. When real-time dialing, routing, addressing, and signaling information is collected, the Pen Register and Trap and Trace Statute may be implicated. See 18 U.S.C. §§ 3121–3126. While IP addresses may be considered routing information, many identifiers addressed here are not.
Putting It All Together
A short example can illuminate how many of the technologies detailed above fit together to leave a trail of evidence about a user’s actions.
Alice begins her day by checking her mobile phone. She unlocks her phone with a biometric (such as her face scan or fingerprint). She realizes that her phone is disconnected from her home’s Wi-Fi and her cellular provider. She connects to her home Wi-Fi (but not her cellular provider) and immediately several apps are active. Her email client retrieves new email messages sent overnight. Other apps send and receive notifications related to social media messages, sales, and promotions. A device worn on her wrist has already synchronized information about her sleep duration with her mobile phone via Bluetooth. From these actions, several companies around the world may have stored records that associate her user accounts with activity from her home’s IP address at a specific time. Notably, Alice’s home ISP has not changed her IP address in many months.
Before she leaves home, she browses social media and reads the news. Advertisements make note of the device’s AdID and IP address. She has allowed her weather app access to her geographical location and both her location and AdID are relayed to hundreds of third parties who bid to show her an advertisement.
As she leaves home to go to the store, she realizes that she needs to connect to her cellular provider and turns on the cellular connection, possibly by turning off airplane mode, which disables the cellular connection for flights. A record now exists of her device’s association with a specific cell site. As she drives to work, the series of cell sites that her mobile device connects to is recorded by her provider. Her navigation app shows her more advertisements; the AdID is the same as when she was home even though her IP address has changed.
She enters a store, and her phone connects to the Wi-Fi. She purchases some items on credit cards stored on her phone and Bluetooth.
During this short excursion, she was captured in videos taken by her own front door camera and the store’s cameras. A neighbor down the street has a camera that captures her car drive by. Her financial transactions are stored on her phone, at the store, and with the credit card company. She has sent text messages
on several apps providing some context to her trip; these messages are on her phone, stored in the cloud, and on friends’ phones. A fitness device captures aspects of her movements.
Because she shares access to her mobile device with no one, there is reason to believe the messages are truly authored by her, and that other aspects of the records are accurate. The fact that the records are stored by many third parties also speaks to their accuracy and integrity.
Investigating Network Traffic
Investigators can acquire evidence relevant to civil or criminal litigation by examination of network traffic. In some cases, investigators can, with permission from a court, directly monitor the traffic being sent over a wire or a radio link and capture a recording. In others, they participate in ongoing network communications and, as participants, receive the network traffic shared among all participants.
Network engineers and administrators sometimes need to observe network traffic to help understand and debug network issues. For this, they use one of many tools that can read, record, and interpret all traffic coming across some communications link. One such tool is named Wireshark, which is freely available and commonly used. Wireshark can collect packets traversing a link, record them in a commonly used format known as a packet capture (or pcap) file, then analyze the traffic contained in the file. This collection provides a complete record of what was sent and received, including the participant addresses and data within the packets.
Investigators gathering information on network communications can use the same tools and methods to record and analyze network traffic. Given access to a network link, investigators can record the network traffic and then analyze it to determine what communications took place during the observation period. This can reveal the addresses of the parties that were using the link for communication and the data that were being sent between them. Such collection may be lawfully done when an investigator is a party to the communication. In such cases the investigator can record all network communications sent to their device, as they are one of the intended recipients. This is known as consensual monitoring.34 Another relevant exception to the federal wiretap statute that authorizes the collection of network traffic without a wiretap order is known as the computer trespasser exception, which authorizes law enforcement to collect the communications of a computer trespasser transmitted to, through, or from the protected computer if the owner or operator of the protected computer authorizes the collection.35
34. See 18 U.S.C. § 2511(2)(c) & (d).
35. Id. § 2511(2)(i).
Investigating Peer-to-Peer File-Sharing Systems
As described above, investigators can gather evidence from public activity conducted on peer-to-peer networks. Different p2p networks have different utility to users; some, for example, exist to share files between users, others to facilitate cryptocurrency operations. In general, anyone can choose to join a p2p network, and the network makes use of their computer’s computational power and network bandwidth and includes it in the operation of the network. As part of the network, each computer processes data voluntarily sent by other computers in the network. Often, the data can include evidence of illegal activity.
For example, p2p file sharing networks allow users to exchange copies of files; in some cases, they support searching for particular files as well. Well-known p2p file sharing networks include BitTorrent and Gnutella. Commonly, the files being shared are subject to copyright. In other cases, the files being shared can contain child sexual abuse material.
Civil or criminal investigations on these networks are aided by the fact that normal operation of the p2p network results in peers sharing information voluntarily with other peers. Any investigator who connects to a p2p network as a user will thus be able to see some of the activity that is happening on the network. For example, peers often publicly advertise the files they are sharing or seeking to obtain. Often files are identified on file sharing networks by the hash value associated with the file. The file sharing network is designed to allow a user to then download the shared file. When an investigator has joined the file sharing network as a user, they can then download that file directly from a particular peer to confirm possession and sharing of that file. As part of that download, the investigator’s computer will see the network address information, which can be used to later identify the user.
All this activity occurs publicly as part of the normal operation of the network. No special access is required by the investigator. Courts considering civil or criminal cases involving p2p networks have consistently held that the information shared on the p2p network is publicly available, including but not limited to the user’s IP address and shared files.36
Investigating Anonymous Communication Systems
Anonymous systems were designed with the intention of providing privacy for persons who are vulnerable and require protection, such as journalists. However, for decades, anonymous systems have been heavily leveraged by those who
36. See, e.g., United States v. Borowy, 595 F.3d 1045 (9th Cir. 2010).
commit crimes such as child sexual exploitation,37 creating malware botnets,38 and selling illegal drugs.39 Investigations of anonymous systems make use of a variety of techniques that are tailored to the operational details of each system.
Users associated with criminal Tor onion services have been identified by law enforcement when the criminal sites and information contained on those sites were seized by law enforcement. For example, in 2015, the FBI obtained a search warrant to install computer code on the seized child exploitation onion service named “Playpen.” When users visited the site, the computer code inserted and executed code on the visitor’s computer, which then conducted a remote search of the user’s computer then sent the true IP address of the user to the FBI (see section titled “Legally Authorized Intrusions,” below).40 In 2017, the Dutch National Police obtained judicial authority to seize and take control of the “Hansa marketplace,” an onion service operating as a marketplace for illicit goods and services including drugs, firearms, and cybercrime malware. While operating the online marketplace, law enforcement was authorized to monitor the criminal activity occurring there, which led to the collection of information on high-value targets and delivery addresses for tens of thousands of orders.
Investigations of users of the Freenet anonymous network are based on the network traffic that travels between neighboring Freenet peers.41 As described in the section titled “Network Architectures,” above, Network Architectures, users of the Freenet system can retrieve content that has been previously uploaded by others into the network. Users direct their Freenet software to request a desired file from neighboring peers, one piece at a time. Neighbors of the original requesters either provide the requested file piece, or they relay the request to one of their neighboring peers. The relayed request contains information about
37. Elie Bursztein et al., Rethinking the Detection of Child Sexual Abuse Imagery on the Internet, in The World Wide Web Conference 2601–07 (May 2019), https://doi.org/10.1145/3308558.3313482; Rebecca Sorla Portnoff, The Dark Net: De-Anonymization, Classification and Analysis (March 2018) (Ph.D. dissertation, U. Cal. Berkeley); Clement Guitton, A review of the available content on Tor hidden services: The case against further development, 29 Computers in Human Behavior 2805–15 (Nov. 2013), https://doi.org/10.1016/j.chb.2013.07.031; U.S. Dept. of Justice, The National Strategy for Child Exploitation Prevention and Interdiction: A Report to Congress (April 2016); Brian Neil Levine, Report to Congress: Increasing the Efficacy of Investigations of Online Child Sexual Exploitation (National Institute of Justice) (May 2022), https://www.ojp.gov/library/publications/increasing-efficacy-investigations-online-child-sexual-exploitation-report.
38. Gareth Owen & Nick Savage, Empirical analysis of Tor Hidden Services, 10(3) IET Information Security 113–18 (May 2016).
39. Press Release, U.S. Dept. of Justice, AlphaBay, the Largest Online “Dark Market,” Shut Down (July 20, 2017), https://perma.cc/8KFQ-R3PS.
40. See Press Release, U.S. Dept. of Justice, Florida Man Sentenced to Prison for Engaging in a Child Exploitation Enterprise (May 1, 2017), https://perma.cc/82U9-NQRU.
41. Brian N. Levine, et al., A forensically sound method of identifying downloaders and uploaders in freenet, in Proc. ACM Computer and Communications Security (Nov. 2020), https://doi.org/10.1145/3372297.3417876.
what is being requested along with other distinct signaling information necessary to operate the network as designed. Careful statistical analysis can be done to distinguish whether a neighboring peer requesting content is the peer that made the original request or merely a relayer.42 When law enforcement joins the Freenet network, it receives requests for illicit material just as any other user of the Freenet network would. (Notably, as the investigator is the intended recipient of all information used in the analysis, the investigation is not similar to the techniques and legal authorizations relevant to the Playpen cases described above.) Using statistical analysis, law enforcement can then calculate the probability the neighboring peer sending the request for illicit material is the original requester and can move forward with an investigation.
Computer and Network Security
In this section, we provide an overview of computer and network security principles to help judges understand the nature and extent of cybercrime, including hacking, malware, and other types of cyberattacks. We provide an overview of privacy issues to aid judges in determining whether data breaches are the result of insufficient security measures and, if so, whether they constitute a violation of data privacy laws. These principles might also arise in intellectual property cases when considering the theft of trade secrets or other work, or in national security matters to understand how attacks on critical infrastructure can threaten the nation.
The classic definition of security has three aspects: confidentiality, integrity, and availability. Confidentiality refers to preventing access to information by those who are not allowed to see it or know it. Integrity refers to the reliability of data. In some cases, this refers to ensuring that the accuracy of data is maintained; it can also refer to digital data not being altered by those who are not allowed to do so. Availability means that we can access systems and data when required and that data cannot be destroyed by those not allowed to do so.
Each of these fundamental aspects relates to some policy that defines who is allowed to perform some action, like accessing, changing, or deleting data. An important aspect of digital security is therefore being able to prove who you are so that access to the appropriate actions can be granted. This is called authentication. Additionally, the idea of nonrepudiation means that users cannot deny their actions and that they can be held accountable for them.
It is worthwhile to note that the desired security aspects depend on the situation. For example, the government would like classified intelligence documents to remain confidential, unaltered, and available. Confidentiality is not required, though, for public governmental websites, though it would be desirable for them
42. Id.
to remain accurate and available. Some instant messaging programs, notably Snap-chat and Signal, have messages that are automatically deleted after some period and thereby gain confidentiality at the cost of integrity and availability.
It is common to approach assurance as a cycle with at least three steps (though more detailed models exist): systems are protected; mechanisms then attempt to detect when protections have failed; and then people respond to the event. The response can include upgrading protections, thus completing the cycle. This cycle is common in many security situations. For example, we protect our homes with locks and fences; detect when those have been bypassed by cameras, barking dogs, or alarm systems; and then recover from incidents by summoning the police, relying on insurance, or getting better locks.
It is important to be aware that detection, like protection, is an imperfect process. Most people are familiar with this in the context of car alarm systems. Almost no one responds to car alarms because most often it is a false alarm; the alarm sounds even though no one is breaking in. This is called a false positive. Similarly, sometimes cars get stolen without the alarm going off, which is called a false negative. All detection systems have some rate of false positive and false negatives.
In addition, detection systems suffer from the base rate fallacy, which occurs when the thing a system is trying to detect is very rare compared to the number of events. An example might be a system to differentiate terrorists from normal passengers on airline flights. Assume there might be 1,000 terrorists who fly every year, and we have a system that can detect them with 99% accuracy. This system can also identify normal travelers with 99.9% accuracy, and in the United States there are about 400 million travelers a year. (We note that these are exceptionally accurate systems; it would be quite difficult to reach these numbers in practice.) This system would correctly identify 990 travelling terrorists a year (1000 ∗ 0.99), but it would also falsely identify 400,000 normal passengers as terrorists (400,000,000 ∗ (1 − 0.999)). The problem is that only about 0.25% (990/(400,000 + 990)) of the resulting alerts are correct; the sheer number of misidentifications of normal travelers dominates the alerts.
The resulting low positive predictive rate, which represents what part of alarms are useful, might not be a problem depending on the circumstance; it might be this initial screen is fast and inexpensive and that a more costly test is used on the positive results. A risk, however, is that humans who monitor the alerts will become habituated to the large number of false alarms and miss correct ones.
Privacy
Privacy online differs from security because privacy is concerned with what information about you others might possess and share; security is primarily concerned with protection of your own data. The advent of online discourse and commerce has allowed a variety of entities to collect, store, and share information about users
that visit their sites. Advertisers and others are able to trace an individual across multiple sites and build a profile of that user and their preferences and interests. They can then use this profile for many purposes, including trying to identify items to promote for sale, or influencing political views and activities. There are many technical ways to identify users across sites; even sophisticated users who try not to be tracked can fail.
Online privacy is addressed in numerous laws and regulations; however, individuals often agree to the disclosure of their data to others by agreeing to the terms of use before using software, websites, or apps. Class actions have arisen when companies are accused of disclosing data in violation of their terms of use agreed upon by the users. For example, in 2022, Facebook’s parent company, Meta, agreed to pay $725 million to settle a class action privacy lawsuit where plaintiffs alleged in part that Facebook shared user data with business partners without disclosing such sharing and failed to restrict and monitor third parties’ use of Facebook users’ sensitive information.43 In addition, a company’s computer systems may be hacked, resulting in the release of private information that users never expected nor agreed to have released.
Sometimes poor cybersecurity can lead to violations of privacy laws. For example, in 2017, Equifax experienced a breach that resulted in the loss of personal and financial information for nearly 150 million people owing to its failure to fix a vulnerability in software associated with one of its databases. The Federal Trade Commission (FTC) filed suit against Equifax alleging violations of the FTC Act, 15 U.S.C. § 45, and the Safeguards Rule codified at 16 C.F.R. Part 314 issued pursuant to the Gramm-Leach-Bliley Act (GLB Act) by failing to reasonably secure the sensitive consumer personal information held in their computer networks. The parties reached an agreement resulting in a stipulated order for a permanent injunction and monetary judgment. The injunction prevented Equifax from making misrepresentations regarding the protections of personal information, ordered the creation of an information security program and third-party assessments of the information security program, and ordered prompt reporting of any future unauthorized access to a consumer’s information. The monetary judgment totaled $575 million, with the majority of this judgment used to provide direct relief to consumers by compensating for related harms and providing extensive free credit monitoring.
Authentication
An important part of computer security is accurately identifying a user so that the correct security policy can be applied to their actions. In particular, evidence
43. Facebook, Inc. Consumer Privacy User Profile Litig, 3:18-md-02843-V (N.D. Cal.).
of user actions might be stronger or weaker depending on what form of authentication was used. A password or device might be stolen and reused; biometric data might show a person was present.
What You Know (Passwords)
The most common and least expensive form of authentication is something you know, in the form of a password that is shared between the user and system. Passwords have many vulnerabilities, however. Anyone who knows a password can use it. An attacker can use an automated process to try likely passwords to gain access to accounts—and in fact do so commonly. Users also often reuse passwords across accounts. If one account is compromised and the password stolen, the same password can be tried at other sites to see if it works there. Such password reuse attacks are also common.
Some organizations use a password recovery process that has the user answer questions about themselves when the account is created. These questions are often used as an alternative to a forgotten password. The information used in questions is sometimes guessable, and an attacker with time to research their subject can often answer them. Compromising less-secure systems by guessing passwords or using such password recovery systems to gain access to a computer without authorization can amount to a crime under the Computer Fraud and Abuse Act codified in 18 U.S.C. § 1030. In 2008, a hacker used the password recovery system to gain unauthorized access to the personal email account of then–Vice Presidential candidate Sarah Palin. He was charged and convicted of violating 18 U.S.C. § 1030(a)(2).44
Passwords are also vulnerable when an attacker compromises a site and obtains the database of user passwords. In the worst case, those passwords are not encrypted and can be read directly. In other cases, the passwords are protected by hashing, hiding the original password. An attacker who acquires the hashes can try computing the hash of many different possible passwords to see if they match any of the stolen hashes; if they match, the attacker then knows the password. Using a number of graphics processing units, attackers can create billions or trillions of guesses per second. Passwords that are not sufficiently complex are thus easily obtained. There is also an attack against hashed passwords and other forms of encryption called rainbow tables. This is a method of pre computing many possible passwords or keys, which are stored in a table, reducing the time required to break passwords using brute force at the expense of the storage and pre computation.
Security experts recommend the use of a password manager. This is software that creates unique and complex passwords for every account. A user can create
44. Press Release, U.S. Dept. of Justice, Tennessee Man Sentenced for Illegally Accessing Former Governor Sarah Palin’s E-Mail Account and Obstruction of Justice (Nov. 12, 2010), https://perma.cc/XPH7-EBH3.
and remember one complex password and use that to access all the stored passwords.
What You Have (Physical Tokens)
Possession of a unique item can also identify a user. Most often, these are used in conjunction with a password so that a stolen item alone is not sufficient for identification. Common mechanisms require the device owner to provide a response to some challenge, to provide a limited-time token to log in, or to perform a computation with a cryptographic key.
Mobile phones often are used for challenge response authentication. When logging into a site, the user might be sent a text message and be required to enter the code that it contains to prove possession of the device. There are similar programs, such as Google Authenticator, that run on a phone that provide a time-based code that changes frequently; before mobile phones were common, employers often provided small, dedicated devices that displayed this changing code on a small screen to provide the same functionality. Other devices include those that contain a cryptographic key. These include USB devices or smart cards that are inserted into a computer and that perform operations on the key embedded in the device.
What You Are (Biometrics)
Users can be identified by their physical characteristics. This is called biometric identification. There are a wide variety of measurements and observations about a person that can be made to determine if they are someone who has been seen by the system before and uniquely identified on that basis. The most common methods are facial recognition and fingerprints, but many others can be used as well, including retinal or iris scans, voice recognition, and hand shape. Some systems include a liveness check to ensure that the user is alive; this limits the ability of an attacker to murder the user or steal a body part for authentication, or to use a photo or fake finger to enter the system.
Biometrics is a detection problem. The system is trying to determine if a particular user is someone known to the system. As such, it does have a false positive and false negative rate, though modern systems can be very accurate. Biometrics also have additional error rates, known as failure to capture and failure to enroll. In the first, the sensor sometimes does not obtain adequate information to make a determination. In the second, it is possible that some users may be unable to use the system. As an example, it is not rare that some people are unable to use fingerprint recognition. People who have no easily measurable fingerprint ridges either owing to physiology, accident, or manual labor can fail to register on the system.
Requiring subjects to unlock devices using biometric security is considered distinct from requiring disclosure of passwords. Courts have generally allowed law enforcement to require individuals to provide biometric identifiers such as fingerprints or facial recognition to unlock a device, as they are considered physical evidence rather than testimonial evidence.45
How Intrusions Happen
It is unfortunately common for computer security systems to be compromised and data to be accessed, modified, or stolen. A variety of actors take part in this process, each with their own motivations, goals, and abilities that affect how a breach occurs.
Types of Attackers
In the simplest case, security breaches happen because of mistakes by well-meaning but perhaps ignorant users or workers. They do not intend to create a problem, but sometimes can be enticed to do so by an attacker who uses social engineering. This is a technique that exploits human interaction to get a user to provide access to systems or information through fraud. Technical attackers have more sophisticated tools. One aspect of computer intrusion is that an expert can determine how to exploit a flaw in software and write a program to do so; one doesn’t need to be an expert to run that program. The experts who are able to write tools to exploit flaws are often referred to as system crackers or hackers. This activity is not inherently illegal unless those tools are used to commit crimes. A black hat hacker typically has malicious intent and wants to break into systems to steal information or resources, or to extort the system owner, and may be involved with organized crime. Conversely, a white hat hacker finds exploits but notifies the software developer and does not exploit them; many companies have a bug bounty that pays rewards for these exploits so they can be fixed before they are a problem. In between these is a gray hat hacker who might not always act ethically; they might sell an exploit to others to use though they do not do so themselves. There is a large market for exploits. At the time of writing, a remotely exploitable but undetectable attack on an iPhone that gave the highest level of access was worth over $1.5 million; it is unlikely that a bug bounty from Apple would prove as lucrative.
While companies like Google have dedicated white-hat teams, many of the best resourced attackers are those that are part of nation-states. Most large nations
45. State v. Diamond, 905 N.W.2d 870 (Minn. 2018).
have their own well-funded intelligence services that seek to penetrate other nations’ systems for intelligence gathering.46 These services have capabilities beyond any commercial organization, and they can exploit a variety of attacks against hardware and software in coordinated and sophisticated ways. Often, they gain access to computers and networks and can keep a presence in there even if they are discovered; these are referred to as advanced persistent threats. Smaller nations turn to commercial suppliers of online intelligence tools; these tools are still often very effective, particularly against citizens being surveilled. More recently, tech companies have started suing these companies.47
The most damaging attackers might be insiders. These are users who are given some trust within an organization and who have access to some or all internal systems, then abuse that trust to conduct attacks. Sometimes they do so after being recruited by other nations; other times they do so for financial gain or because they are disgruntled.
Types of Intrusions
There are a wide variety of ways to intrude on a computer system, most of which are outside the scope of this guide. As a general overview, though, most attacks occur through stolen authentication credentials or technical flaws in systems or software.
Attackers gain access to user credentials in a variety of ways. The easiest is to trick the user into providing credentials by getting them to visit a fake website that will capture what the user enters; hence the large volume of phishing emails and texts that are sent every day. At other times, attackers are able to find leaked user passwords that are posted online and then try them at other websites. Sometimes other credentials, such as for cloud computing services, end up stored online but without proper confidentiality settings and are later discovered and abused.
Attackers are also able to gain access to systems by exploiting flaws in the running code. A general approach for this is for the attacker to find a flaw in the system in which attacker input gets interpreted as computer code and executed, or to find input that causes an unanticipated effect. The techniques for this vary depending on what kind of software is running and what input the attacker can provide.
Locating and identifying attackers who conduct remote attacks over the internet can be challenging or impossible. These attackers can try to hide their
46. U.S. Dept. of Justice, “Two Chinese Hackers Working with the Ministry of State Security Charged with Global Computer Intrusion Campaign Targeting Intellectual Property and Confidential Business Information, Including COVID-19 Research” (Off. of Pub. Affs., Nov. 27, 2023), https://perma.cc/MJS6-QMD7.
47. Apple Inc. v. NSO Grp. Techs. Ltd., 5:21-cv-9078.
location. They might use an anonymous network service like Tor, or they might intrude on other computers and use those to direct attack traffic through; the eventual victim only sees traffic coming from these intermediate computers and not from the computer originating the attack. Botnets, described in the malware section below, are used to facilitate this.
Legally Authorized Intrusions
Not all computer intrusions are illegal. The law criminalizing unauthorized access to a protected computer includes an exception for authorized law enforcement activity (see 18 U.S.C. § 1030(f)). However, this statutory exception does not address Fourth Amendment protections. Thus, when law enforcement seeks to gain access to a computer in this manner to collect information protected by the Fourth Amendment, they often obtain a search warrant. When executing this type of search warrant, law enforcement might overcome the computer’s security using techniques similar to those a hacker might use, just as when law enforcement executes a court-authorized search of a home utilizing lock-picking tools similar to those used by a thief. Law enforcement might identify a technical flaw to which the systems are vulnerable; create or purchase an exploit that can take advantage of the vulnerability; deploy the exploit to gain access to the systems; then deploy a payload that will gather the authorized evidence; and collect that evidence at a law enforcement–controlled computer elsewhere on the internet.
When the location of the target computer is concealed through technological means, such as through obfuscation provided by an anonymous network, Federal Rule of Criminal Procedure 41 provides a court in the district where activities related to the crime may have occurred the jurisdiction to issue a warrant authorizing law enforcement to remotely search a computer located outside the court’s district. Criminal Rule 41(6)(A) was added to the federal rule governing search warrants in 2016 and eliminates the jurisdictional challenges that occurred across the nation when the FBI obtained a single search warrant in the Eastern District of Virginia for the deployment of code from a seized child exploitation website called “Playpen” operating on the Tor network. Under this search warrant, the code was deployed from the government-controlled “Playpen” website to the computers visiting the site. This code conducted a limited search and forced the user’s computer to reveal its true IP address to the FBI. Prior to this remote search provision in Rule 41, it was unsettled which court had the appropriate jurisdiction to issue such a search warrant. This question is now clearly resolved by this remote access provision to Rule 41.48
48. Some of the federal cases addressing this jurisdictional question include United States v. Henderson, 906 F.3d 1109 (9th Cir. 2018); United States v. Horton, 863 F.3d 1041 (8th Cir. 2017);
Malware
Malware is malicious software that is designed to operate without the knowledge or consent of the computer user. It is often useful to differentiate how malware gets spread or placed on a computer from what it does once it is there. There are a wide variety of mechanisms used to get malware installed, and malware can have a variety of effects, including targeted ones that are specific to a victim. For descriptions of various types and components of malware, see the Glossary of Terms.
It is worthwhile to note that there is a market for access to computers infected with malware. Attackers will create a botnet by infecting many computers with malware that allows continuing access—these infected computers are called bots—and then install other malware on behalf of others who pay for access to the compromised computers. For example, in one case a Russian-born cyber-criminal claimed on online forums that he could control up to 500,000 infected computers at one time.49 When the threat is large and difficult for individuals to mitigate, courts have approved government efforts to enter compromised machines and remove the malware that was part of the botnet.50
It is common for computer users who are accused of a computer-related crime to claim that they are innocent of it, and that any evidence is a result of malware installed by some outside actor. This is not an impossible occurrence, especially for a nontechnical user targeted by someone more technically sophisticated. In these cases, however, a forensic examiner should be able to determine if this is likely to have occurred by looking for evidence of malware or correlating user activity with evidence about the time of the alleged criminal activity. Often, this defense is undermined by robust evidence of user interaction with the computer or evidence during the time in question.
A failure to implement reasonable security measures to protect against a foreseeable risk can lead to civil liability under a claim of negligence.51 For a plaintiff’s suit to survive a motion to dismiss, the court must consider if the complaint failed to establish one or more of the elements of a negligence claim, including causation between the defendants.52 If the complaint is found insufficient, courts will often grant leave to amend the complaint.
United States v. Werdene, 883 F.3d 204 (3d Cir. 2018); United States v. Moorehead, 912 F.3d 963 (6th Cir. 2019).
49. Press Release, U.S. Dept. of Justice, Russian-Born Cybercriminal Sentenced to Over Nine Years in Prison (July 12, 2017), https://perma.cc/6EZG-L69P.
50. Press Release, U.S. Dept. of Justice, Justice Department Announces Court-Authorized Disruption of Botnet Controlled by the Russian Federation’s Main Intelligence Directorate (GRU) (Apr. 6, 2022), https://perma.cc/PNY7-FQV5.
51. See In re Am. Med. Collection Agency Inc. Customer Data Sec. Breach Litig., 2021 WL 5937742 (D.N.J.); In re Equifax Inc., Customer Data Sec. Breach Litig., 362 F. Supp. 3d 1295 (N.D. Ga. 2019); In re Home Depot, Inc., Customer Data Sec. Breach Litig., 2016 WL 2897520 (N.D. Ga.).
52. See Aspen Am. Ins. Co., et al. v. Blackbaud, Inc., 624 F. Supp. 3d 982 (N.D. Ind. 2022); In re Sony Gaming Networks & Customer Date Sec. Breach Litig., 996 F. Supp. 2d 942 (S.D. Cal.
Forensics and Digital Evidence
As stated in the Introduction, many legal issues involve facts and evidence related to software, computers, networks, and digital information, all of which have become ubiquitous in our personal lives, as well as in commercial and government processes, products, and services. For example, digital evidence is an aspect of almost every criminal investigation.53
Forensics is the scientific investigation and formal presentation of evidence that supports or refutes an investigative hypothesis that explains an event of interest. When the investigator follows a repeatable, structured process for gathering evidence and uses strong inductive reasoning, forensics is a science rather than merely a set of techniques that recover data. A successful hypothesis has supporting evidence that explains allegations as a series of actions, events, identities, or intentions, and does not have strong countervailing evidence. Digital forensics is focused on evidence related to computer and network systems.
Evidence should be gathered following standard techniques that are defined ahead of the crime and accepted by the scientific community. The investigator attempts to identify sources of possible digital data, copy such data, and preserve its integrity; extract relevant evidence from the collected data; and report the results of the investigation.54 These stages transform identified artifacts into evidence that speaks to facts, or that link data to a scene or person through individualization or can speak to the intentionality of a person.
Recovery of Digital Evidence
A computer comprises many systems: file systems, databases, networking, and more. Each system is designed to present a simple view of a complex set of interactions.
For example, the networking system hides a large amount of work that goes into presenting a web page. Similarly, the file system presents your files to you without the details of how files are actually managed. The operations that are hidden from the user by each system are designed to operate efficiently, and often efficiency means leaving artifacts behind.
This is particularly true when files are deleted, because the quickest mechanism for the file system is to simply mark the file as deleted, then to later
2014); Heritage Valley Health Sys., Inc. v. Nuance Communications, 479 F. Supp. 3d 175 (W.D. Penn. 2020) (malware attack sponsored by Russian military—NotPetya).
53. David B. Muhlhausen, Report to Congress: Needs assessment of forensic laboratories and medical examiner/coroner offices (National Institute of Justice, May 2020).
54. Keith Inman & Norah Rudin, The origin of evidence, 126 Forensic Sci. Int’l 11–16 (Mar. 2002), https://doi.org/10.1016/s0379-0738(02)00031-2.
overwrite the file when space is needed. This process is similar to writing with a pen. It is easier to cross out mistakes from sentences in a letter than it is to recopy the entire letter’s text onto a new sheet of paper, but the old writing might still be legible.
The file system presents to the user a simplified logical view of the file system that doesn’t include all the information available to the file system itself. In fact, the goal of every system is to present a complex service as something simpler via an interface. One analogy to this process is dining at a restaurant. The menu and the waiter presented to the customer are an interface that can be used to order food from the kitchen. Most kitchens are chaotic and messy, yet the plates that arrive at the table don’t show it. It is the goal of the waiter to present such an illusion, and any computer interface is no different.
Figure 9 illustrates the user’s view of the file system. The interface allows the user to create files, and storage space is allocated accordingly. The user can issue a command to delete the file, and storage space is then unallocated. File modifications can occur through overwriting the same storage space with new data, finding space for additional data, or deleting the existing file and then creating a new file with the same name. Users have no information or influence regarding where a file is stored on the storage medium—that is a complication handled by the file system.
For forensic investigators, the life of data in storage is not so simple. Figure 9 illustrates the internal life cycle of files, data, and storage on a file system, beginning with data given to the file system by some application, such as a word processor. In Step 1, a file is written to a specific allocated block x, and we say that it contains active data. When the user or application issues the command to delete the data, the process moves to Step 2, where the storage block is unallocated. The data remains present in storage, but we say it is expired; that is, the data cannot be recovered through the file system’s interface to the user, but it is retrievable by an investigator with direct access to the disk. Finally, once the same block is allocated to new data, the overwritten portions of the old data are removed and unavailable to the investigator. For decades, forensic experts have identified and examined many other types of digital evidence available from computer systems, including desktops and laptops, smartphones, wearables, IOT devices, cloud systems, and more. The same principles as above apply: data are stored on these devices because the data’s presence increases usability, performance, and security; data are often copied between and stored on multiple systems because of interactions among parties; and such data often remain available for recovery even after deletion.
Relatedly, it is notable that courts have serious concerns when digital evidence is intentionally destroyed. For example, in Burris v. JP Morgan Chase & Co.,55 a whistleblower protection case was dismissed with prejudice because of a plaintiff’s systematic destruction of electronically stored information (ESI). The court appointed a computer forensic examiner who reviewed the plaintiff’s electronic devices and discovered evidence that ESI had been systematically deleted. In addition, two software tools that advertised their ability to overwrite free space, making it impossible to recover deleted data, were found on plaintiff’s electronic devices.
Computer Science from the Perspective of Federal Rule of Evidence 702
When considering experts for testifying on computer science matters, the factors elucidated by the Supreme Court in Daubert v. Merrell Dow Pharmaceuticals, Inc.56 and its related cases57 apply well. As the Supreme Court explained, a trial court’s evaluation of the underlying reasoning supporting an expert’s testimony and the validity of the scientific methodology they use should be “flexible . . . and its focus
55. 566 F. Supp. 3d 995 (D. Ariz. 2021).
56. Daubert v. Merrell Dow Pharms., Inc., 509 U.S. 579 (1993).
57. See also General Electric Co. v. Joiner, 522 U.S. 136 (1997); Kumho Tire Co., Ltd. v. Carmichael, 526 U.S. 137 (1999).
must be solely on principles and methodology, not on the conclusions that they generate.” The factors established in Daubert to be used in a court’s inquiry should be inclusive of:
- “whether the theory or technique in question can be (and has been) tested.” If a method is testable, then there are demonstrable, controlled scenarios where the test can result in positive and negative results.
- “whether it has been subjected to peer review and publication.” Peer review is the process by which a paper is evaluated by qualified scientists working in the same field as the subject of a submitted paper. In many fields outside of computer science, journals are peer reviewed and conferences are not. However, in computer science, not only are conferences almost always peer reviewed, but they are also often considered the most prestigious venues for publishing (implying a paper’s results have been more carefully evaluated by the reviewers).
- “its known or potential error rate and the existence and maintenance of standards controlling its operation.” Ideally the methodology supporting testimony has a quantified error rate based on data independent of the case in front of the court. Notably, there is no requirement that the error rate be at a specific level, only that it be known to the court.
- “whether it has attracted widespread acceptance within a relevant scientific community.” Methodologies are often based on known approaches that already appear in textbooks, previous peer-reviewed publications, or reports on best practices from established organizations. Evidence and facts should be based on the results of practices and protocols that are written down in lab manuals ahead of an investigation. This approach often has the advantage of avoiding the appearance of bias. The training and methodologies used by practitioners and examiners should have been developed by experts who have applied a scientific methodology.
In computer science, two international societies stand out as having a strong track record of overseeing high-quality conferences and journals: the Association for Computing Machinery (ACM) and the Institute of Electrical and Electronics Engineers (IEEE). Other high-quality publication venues and societies certainly exist.
These factors were codified in a series of amendments to Federal Rule of Evidence 702 in an effort to clarify their application.58 Assessment of admissibility of computer science evidence follows an analysis that includes the Daubert questions discussed above: Are the methods testable and have they been tested? Has peer review been employed? What is the quantified error rate? Has there been
58. For a discussion of Federal Rule of Evidence 702, see Liesa L. Richter and Daniel J. Capra, The Admissibility of Expert Testimony, in this manual.
widespread acceptance? Whether a particular witness is qualified per the expert’s scientific, technical, or other specialized knowledge—codified as Federal Rule of Evidence 702(a)—is discussed presently.
Experts in Computer Science
Overall, determining if an expert is qualified should be based on criteria specific to the case at hand. For cases involving computers and computer science, an appropriate expert is one who has experience and training relevant to the particular aspect of computer science involved. By analogy, consider a case that involves accusations of malpractice related to heart surgery—surely a podiatrist is the wrong choice to serve as an expert witness. Like medicine, computer science is a broad field and experts have specialties. These specialties are myriad: networking, security, machine learning, databases, algorithms, to name a few. Moreover, the field is both a science and an applied discipline. A person with years of research experience may not necessarily be able to speak to the complexities of a deployed production system; and likewise, years of applied experience does not necessarily imply an understanding of scientific fundamentals, nor a deep and rich understanding of the limits and consequences of applying techniques and methods.
However, speaking broadly, there are many ways to evaluate whether a particular person is a qualified expert in computers or computer science. These include asking if the candidate has academic degrees in computer science or computer engineering from well-known universities and colleges, awards for high-quality papers, advanced member grade status from professional societies (such as being a “Fellow” of the ACM or IEEE), a high count of publications in peer-reviewed conferences and journals, and a high count of citations to those papers (though citation counts vary in magnitude across subfields of computer science). Just as notable is a record of years of experience in a computer science–related role with reputable companies, government agencies, and other institutions.
Trial courts are considered the gatekeepers of expert testimony, per General Electric v. Joiner. For example, in Resnick v. United States,59 the court found there was no right to call a computer expert to rebut the government’s expert witness. In that case, the defendant missed the deadline to file notice of an intended computer expert. The court found the defense counsel’s questioning of the government computer expert sufficient and not evidence of ineffective assistance of counsel.
59. 7 F.4th 611 (7th Cir. 2021).
The Quality of Forensics and Digital Evidence
Forensic investigations are at their strongest when conclusions are drawn via inductive reasoning. In this type of reasoning, a generalization or model of what is expected to occur is created based on what has been observed in repeated observations. Ideally, these observations have been made independent of the facts of the case. Other aspects related to Daubert should also be present, as listed above: the study of observations should make use of well-known methods, and the conclusions should be published in a peer-reviewed scientific venue. The reasoning should involve a falsifiable hypothesis, and the observations should provide for a known, quantified error rate.
Inductive reasoning is strongest when hypotheses are verified by independent parties. Investigators rely heavily on validation studies that perform repeated and precise tests on equipment and software to determine what can be said with assurance about evidence. Validation reports are published by government agencies, such as the National Institute of Standards and Technology (NIST),60 by industry and academic researchers in peer-reviewed journals and conference proceedings, and by professionals who engage in testing of their tools.
Direct evidence proves a fact without inference, such as a voluntary confession would provide. Digital artifacts are often circumstantial evidence of an event or fact, but that status should not be viewed pejoratively. Direct evidence from witnesses is not always reliable. People do not have perfect perception or memory. People have personal biases and can be paid or otherwise motivated to give false testimony. Confessions can be coerced in not very subtle ways. In fact, most evidence at a crime scene is indirect evidence. For any crime for which there are not witnesses, the case must be circumstantial.
Digital evidence is typically modifiable.61 For that reason, one might conclude that digital evidence should not be considered as absolute fact when it is found—but in fact it is no weaker than other types of circumstantial evidence. DNA evidence has a similar problem: it’s easy to plant DNA evidence at a scene—a few skin cells will do it.
Further, indirect evidence can be stronger than direct evidence if there is other corroborating evidence—a notion that Locard’s Exchange Principle speaks to. For example, let’s say that it has been alleged that John committed a crime against Jane, and John claims to not know her at all. Investigators find that John’s web browser has a history of pages he has visited recently, including the text and images from those pages. Jane’s public webpage is found in that history cache, and it is used as indirect evidence that he knew Jane before the crime took place. John’s
60. NIST, Computer Security Resource Center, https://perma.cc/4UXM-B6E8.
61. Forensic practitioners record and report cryptographic hashes of collected material to help identify any modified data and as a best practice should take care not to accidentally modify any data.
browser will record when exactly John last visited Jane’s page, and such facts can be corroborated by examining the web server that hosts Jane’s webpage. Furthermore, other logs at John’s internet service provider may be able to confirm indirectly that his computer was connected to the internet at the time the page was viewed. Logs from John’s email server may indicate he checked or sent email at the time when the webpage was retrieved; if he admits to keeping his account and password secret from others, then the email server logs indicate he was at the keyboard at the time.
E-Discovery
Digital forensics is often part of an adversarial investigative process in which an investigative hypothesis about a user’s actions is confirmed or refuted based on evidence collected from electronic devices. The assumption is that an individual under investigation might try and conceal data about their actions and authorities need to act to collect data before it is lost or destroyed.
E-discovery differs from forensics in that it is part of a civil discovery process. While forensics techniques might be used in some specific circumstances, such as making a preservation request for a particular user’s devices to obtain data and metadata from them, in general e-discovery will require parties in a civil action to produce relevant material they already have in an electronic form to allow faster and less expensive review. Normal discovery rules apply; each party is bound to produce material responsive to the case, but each party decides what materials are responsive rather than the other party having access to all data and making that determination, which can clearly be intrusive.
E-discovery allows for faster and cheaper review than paper. Documents can be searched using a text retrieval system that allows searching for terms. Additionally, supplying documents electronically allows the document metadata to be used. This can include dates when documents were created; dates and times for emails and other messages; and other relevant information that can be searched as well.
There are a variety of commercial solutions for uploading, managing, and reviewing documents. The Sedona Conference has published documents to help guide judges through the e-discovery process.62
62. The Sedona Conference, Resources for the Judiciary, https://perma.cc/Z3AJ-UZMC.
Glossary of Terms
This section contains definitions of terms from the text and others that might be legally relevant.
access point (AP). A hardware device that provides wireless internet access to nearby devices over Wi-Fi.
advanced encryption standard (AES). The U.S. government standard for shared-key or symmetrical encryption for all except classified information. This protocol replaced DES in 2005. It allows use of keys of 128, 192, and 256 bits, which are large enough to resist brute-force attacks.
advanced persistent threats (APT). A sophisticated and targeted cyberattack carried out by highly skilled and well-resourced attackers who seek to gain unauthorized access to a network or system for an extended period of time.
adware. A term for legitimate software that is supported by advertisers; can also be malware that illicitly serves advertising to computer users. Unscrupulous attackers get paid by an often-unsuspecting advertiser for what appear to be legitimate ad views. Instead, the ads either replace legitimate ads on a webpage, are added to webpages, or are never shown to a user but are charged for.
algorithm. An ordered series of steps used to accomplish a task. A program is a representation of an algorithm that a computer can execute.
application. See program.
authentication. The process of verifying a user’s identity in a secure way to provide access to a system.
availability. The security design goal of ensuring that data and systems are available when needed.
backdoor. A mechanism that is installed to allow future access to the computer that bypasses the normal login mechanism. This is used either to access the computer later in case the installed malware is removed, to gain entry to the machine while bypassing the normal logging mechanism, or both.
base rate fallacy. A problem with detection systems in cases where the thing being sought is rare compared to the number of items to examine; it results in most alerts being false positives, degrading the effectiveness of the system.
Big-O or Big- Ω. Terms used by computer scientists to measure the efficiency of an algorithm in terms of the number of computational steps needed to solve a problem given an input of size n, the number of input items. Big-O (“big oh”) notation describes the worst-case running time for an algorithm; this is the most steps it will ever take to compute the algorithm. Similarly, Big-Ω (“big omega”) notation is the best possible case for the number of steps needed and supplies a lower bound.
binary encoding. The representation of a value (a number or character) in base 2, i.e., using only ones and zeros.
biometric. A measurement of some physical aspect of a person used in authentication processes to determine identity.
birthday attack. This term is a reference to a type of cryptographic attack where a match is found between any two pairs of items in a set. This type of match is easier to find than fixing one item in the set and looking for a match among the remaining items. The reason the birthday attack is easier is that there are more pairs of items in the set than there are remaining items after selecting one; for example, in a set of 10 items, there are 45 pairs; but if we select one item, only 9 remain. The name of the attack refers to the high chance of finding two persons with the same birthday from among a relatively small group.
bit. A single binary digit that is a 1 or 0.
black hat. A computer attacker/hacker who has malicious or criminal intent.
blockchain. A distributed and decentralized digital ledger that records transactions in a secure and tamper-evident way.
boot sector. The first sector of a storage device, such as an SSD, that contains information about the file system including where code to boot the operating system lies.
bots/botnet. Attackers sometimes take over computers to be part of a wider distributed network that participates in a variety of activities; the computers that are forced to participate are known as bots and the entire group a botnet. Botnets are often used for sending spam emails or text messages; they can also be used as part of a distributed denial-of-service attack, where the bots send large amounts of garbage traffic that overwhelms the internet or a targeted computer.
browser hijacker. Software that infects a user’s web browser to automatically click on ads or to redirect traffic to particular webpages that contain ads.
bugs. Errors or defects in software code that can cause unexpected or incorrect behavior in a program.
buses. Electronic interconnections in a computer that move data between its components
byte. Eight bits together; typically, the smallest commonly used measure of data. Measuring bytes commonly includes prefixes, like kilo- for 1,000, mega- for 1 million, giga- for 1 billion, and tera- for 1 trillion.
caches. Small but fast repositories of memory used to store data and speed computation in a CPU. (A CPU cache is just one type, and other caches appear elsewhere in a computer system.)
cell site location information (CSLI). A system that can be used to triangulate the location of a cell phone based on receiving a signal at several different cell towers.
central processing unit (CPU). The primary component of a computer that performs the majority of the processing and controls the other components.
certificate. A cryptographic credential used to verify the identity of websites or the creators of software. A root certificate is a credential that comes with or is installed in an operating system or internet browser that is used to verify the ownership of other certificates.
ciphertext. Text that has been encrypted to be unreadable without the appropriate key.
client-server. A computing communications model in which a centralized system, known as a server, interacts with many subordinate clients.
closed-source. A type of source code that is maintained privately by the creator; contrast with open-source.
cloud computing. A large-scale computing model in which programs are run on computers elsewhere in the network; often these computers are rented out by large cloud providers.
code. See source code.
compiler. A computer program that takes human-readable computer source code and translates it into a binary form executable by a computer; this binary form is referred to as having been compiled.
computational core. The portion of a CPU that executes a program; many CPUs now contain multiple cores.
confidentiality. The security goal of keeping information secret from those who are not authorized to access it.
cookie. A small piece of information recorded in a web browser that is set by and shared with individual websites. Used for authorization, advertising, and to track the user’s actions across a site.
copyleft. A type of licensing agreement used for software that allows for the free use, modification, and distribution of the work under certain conditions. The copyleft license requires that any modified or derived work from the original must also be licensed under the same terms as the original work.
cores. See computational core.
crackers (or hackers). Technologically sophisticated attackers who are able to breach computer security measures.
crypto jacking. Many cryptocurrencies require that computers called miners participate to allow transactions to proceed; miners occasionally get rewarded for their work. Attackers install malware that acts as a miner on the user’s
computer. This is called crypto jacking, and it allows the attacker to earn some cryptocurrency at the user’s expense.
cryptographic hash. An algorithm that takes input of any size and produces a fixed-size output that represents a unique fingerprint of the original input. This output is also referred to as a hash value, message digest, or checksum.
cryptographic signature. Data that authenticate both the author and contents of a message in a manner that is mathematically provable to someone who knows the following: the algorithm used to sign the message; the message; and a cryptographic key created by the signing author.
darknets. A type of network that is intentionally hidden and can only be accessed using special software; often access is limited to authorized users.
data center. A physical location that hosts a large number of computers. Typically, these locations provide physical security, electricity, cooling, and network access.
database. A specialized system that stores data in a relational format and offers a method of querying and processing the stored data.
decompilation. A method of transforming a compiled program back into human-readable source code. Often the decompilation process is not perfect, as information is lost during compilation.
decryption. The process of converting ciphertext into plaintext by applying an algorithm and the appropriate key.
denial of service (DOS). An attack against computer or network systems with the intent of making them unusable or unreachable.
dictionary attack. An attack against password systems where the attacker encrypts large numbers of possible passwords to see if they match an unknown encrypted or hashed password.
digital signature. A cryptographic technique that provides authenticity, integrity, and non repudiation to a digital document by encrypting the document or its hash with the signer’s private key.
drive-by downloads and watering hole attacks. A drive-by download exploits internet web browsers that have errors that allow websites to force installation of software on computers that visit the site. To find victims, attackers can choose sites that are close in name to a real site and hope that users make a typo when entering the address. They might also place ads that carry malware on internet advertising networks. In a watering hole attack, an attacker might create or compromise a website that appeals to some population they want to attack, like systems administrators, so that malware will be more likely to reach that group.
dropper. The most common item installed through malware, a dropper is software that allows the attacker to install other software. There are underground
markets where attackers pay to access computers that are already infected with droppers so they can install additional malware.
electronic communication services (ECS). Any service that provides users the ability to send or receive wire (voice) or electronic communications. See 18 U.S.C. § 2510(15). Some examples include email providers, chat sites, websites that provide direct messaging services, and texting apps.
encryption. An algorithm that uses a key to transform data so that it appears random and protects confidentiality.
end user license agreements (EULAs). Legal agreements between software providers and users that outline the terms and conditions of use.
Ethernet. A hardware computer network protocol used to transfer data over wired local area networks (LANs).
executable. An executable file containing binary instructions that can be run directly by a computer’s processor.
file system. The portion of the operating system that structures data and organizes files and directories on a computer’s storage device.
flash memory. Non volatile computer memory that can be electronically erased and reprogrammed.
free and open source (FOSS). Software that is licensed in a way that allows users to freely use, modify, and distribute the source code.
Freenet. A peer-to-peer network designed to provide secure and anonymous file sharing.
functions (methods, or procedures). Self-contained blocks of code that perform some algorithm and can be called from other parts of a program.
geolocation. The process of determining the physical location of a device or user, often based on IP address; this can be inaccurate.
GNU public license (GPL). A FOSS license that grants users the freedom to use, modify, and distribute software as long as any derivative works are also licensed under the GPL.
graphics processor unit (GPU). A computer component with many weaker processing cores, primarily useful for rendering images and video but also useful for machine learning and cryptocurrency.
hackers. See crackers.
hard disk. A storage device used to store and retrieve digital information using magnetic technology.
hash. See cryptographic hash.
International Mobile Equipment Identity (IMEI). A unique identifier assigned to mobile phones and other cellular devices.
internet of things (IOT). Physical devices with sensors, software, and network connectivity that exchange data with other devices and systems over the internet.
internet protocol (IP). The portion of the internet software and protocol stack that handles delivery between computers on different networks.
internet service providers (ISP). Companies that provide customers with access to the internet.
interpreted languages. Programming languages that are executed by an interpreter as they run rather than being compiled into machine code, which is run separately.
interpreter. A program that reads and executes code written in an interpreted programming language.
IP address. A numerical identifier assigned to each device connected to the internet; this address may not be unique to a particular system owing to NAT and other mechanisms.
keylogger. A form of spyware that monitors what the user types, and sends it to the attacker or saves it in a file for the attacker to recover later. This can be used to capture passwords, emails, or other things that the user types.
library. A collection of prewritten functions that can be used by a program to perform common tasks.
link layer. The portion of communication software responsible for communication between devices on a local area network (LAN), such as devices on Ethernet or Wi-Fi.
machine learning. An area of artificial intelligence that enables computers to learn from and make decisions based on data without needing a human creating a particular algorithm.
malware. Software intended to cause harm to or violate the security of a computer system.
medium access control (MAC). A portion of the link layer in the networking stack that controls access to the physical medium of a network.
memory (non volatile). Computer memory that retains data even when the power is turned off, such as flash memory or hard disk drives.
memory (random access, volatile). Computer memory that can be accessed randomly and quickly, but loses its data when the power is turned off (such as RAM).
metadata. Data that describes other data, such as the author, date, and file type of a document.
mining. The process of verifying and recording transactions on a cryptocurrency blockchain by solving complex mathematical problems with dedicated computers.
motherboard. The main printed circuitboard in a computer that connects all of the other components and peripherals.
network address translation (NAT). A technique used to remap one IP address space into another by modifying network address information in the IP header of packets while they are in transit across a traffic routing device.
network interface. The physical or virtual connection point between a computer and a network.
network layer. The layer of the networking stack responsible for routing packets between networks.
open source. See free and open source (FOSS).
operating systems. Software that manages computer hardware resources and provides common services for computer programs as well as a user interface.
optical media. Storage media that uses optical technology to read and write data, such as CDs, DVDs, and Blu-ray discs.
packet capture (pcap). A file format used by Wireshark and other programs to capture and store network traffic for analysis and debugging purposes.
phishing and spear phishing. The act of an attacker who wishes to target a specific individual or group by sending an email, text, or other messages that contain a link to malware or to a site that can install it; when sent widely, this is referred to as phishing. Spear phishing is a more targeted technique in which the attacker learns about the victim through social media or web presence and then forges email from someone the victim would trust. Spear phishing is also frequently used in computer fraud—for example, altering an account number where funds are to be transferred during a transaction so that the funds go to the attacker instead of the intended recipient.
physical layer. The lowest layer of a network software stack that handles the physical transmission of data over a communication channel.
port numbers. Numbers in internet connections used to associate a network connection with a particular process that is sending or receiving data.
program. Computer executable instructions that perform a specific task on a computer system.
programming language. A formal language used to write human-readable algorithms that can, through interpretation or compilation, later be executed by a computer to perform a specific task.
public-private key pair. A set of cryptographic keys that are used to encrypt and decrypt messages and to verify the digital signatures of digital certificates.
rainbow tables. A method of pre computing and storing many possible passwords or keys to reduce the time required to break a password or key compared to brute force computation alone.
random access memory (RAM). Circuitry that holds working data while the computer is running. RAM is volatile, meaning it needs power to continue storing information.
ransomware. Malicious software that encrypts user files, then supplies an apparent route to recover them through paying the attacker—this type of software has become a significant risk. Organized criminal gangs have started targeting larger organizations that are dependent on data, such as banks, universities, and hospitals; cryptocurrency has provided a mechanism for criminals to receive their ransom while concealing their identity and location. One method deployed by law enforcement to fight this criminal activity is to gain control over the servers and websites used to communicate and control its victims.
remote access tool. See spyware.
root certificates. A file containing the public key of a trusted authority. The public key is used to digitally sign the public key certificates of its customers, ensuring they are authentic.
root kit. Malware that subverts the normal operating system observability tools in order to hide the existence of the malware.
router. A specialized computer that connects and transfers data among multiple computers. The router is able to make decisions about which of several possible next “hops” the traffic should be sent to, ensuring that the shortest path to the destination is taken.
scareware. Attackers often try to frighten users into sending money with scareware. One form of scareware is software that produces fake antivirus warning messages that request the user pay for a software upgrade to remove a non existent threat.
serverless computing. See cloud computing.
shared key. See symmetric key.
social engineering. A process by which attackers gain access and information by convincing a user to provide access to systems or information through fraud.
software. A set of instructions that can be executed by a computer.
solid state drive (SSD). A high-capacity, non volatile storage device to retain data.
source code. The set of files written in a programming language that are used to create a program. Might also refer to a production of these files along with additional files relating to the design and construction of the program.
source code control. A system used by software engineers to track changes made over time to source code. Typically, the source code (and the log of the changes) is said to reside in a repository.
spear phishing. See phishing.
spyware. A general term for software that can monitor user actions and data on a computer. In terms of malware, this might be a remote access tool (or RAT) that provides complete remote control of the computer, including the ability to access files on the system, add files to the system, or activate a camera and/or microphone.
subnet. A smaller network that is part of a larger network.
subscriber identity module (SIM). A small, removable card used in mobile devices to identify and authenticate a subscriber on a cellular network. Newer phones use eSIMS, which are not physical but are stored as information on the phone.
symmetric key. An unguessable value shared as a secret by two participants exchanging encrypted data via a symmetric-key encryption algorithm. The same key is used to encrypt and decrypt.
tape. A data storage medium that uses magnetic tape to store digital information, most often for long-term data storage and backup purposes.
Tor Browser. Free, open-source software from the Tor Project that enables a user to join a network of other users volunteering as network relays. All traffic from the user is sent through the relays such that the website (or other destination) the user is contacting cannot link the received traffic to the user’s real IP addresses. Tor Browser provides a service that is similar to a VPN but is more secure in some ways.
transport control protocol. The portion of the internet software and protocol stack that ensures data is delivered in a reliable manner from one computer on the internet to another.
Trojan or Trojan horse. A program that promises, appears to, or really does supply some useful functionality while secretly performing harmful actions.
USB (universal serial bus) drive. A portable storage device that uses flash memory to store data.
user datagram protocol (UDP). A transport layer protocol that provides an unreliable but low-latency network connection.
version control software. A program that serves as a repository for source code and other documents that is able to track and revert changes.
virtual machines (VMs). A software program that pretends to be computer hardware while running on a host’s real hardware so that other programs or operating systems can be run while isolated from the host computer.
virtual private network (VPN). An encrypted connection that forwards data across other networks that can only be decrypted and read at the endpoint; this endpoint might forward the received data, making it appear as if the endpoint is where the initial computer resides.
virus. A program that can copy itself by inserting its code into other programs. The infected program then finds other programs that it can infect and adds the virus there. It is common for viruses to spread when files and programs are shared. Designers often take steps to obfuscate what the virus is doing. They might repack their code, which keeps the same functionality but changes the appearance of the code. They might encrypt much of the functionality and decrypt it only as needed. Both techniques and others can be used so that the virus is different on each infected system; this is an example of a polymorphic virus. Viruses also attempt to elude detection, possibly by starting before the operating system; boot sector viruses are an example of this approach.
VPN concentrator. The device a computer will connect to send data through a VPN.
watering hole attack. See drive-by download.
white hat. An ethical hacker who works to improve computer security (see also black hat).
Wi-Fi. A commercial term for a series of industry standards for short-range wireless communication among computers and mobile devices.
Wireshark. A packet capture tool used to monitor, log, and/or debug network traffic.
worm. A computer worm is a self-executing program that runs on its own, unlike a virus. A worm spreads across a network by taking advantage of security vulnerabilities on other network-connected systems. A worm can spread shockingly fast in some cases; it might be possible to infect all vulnerable systems worldwide in under 15 seconds in some cases. A major worm spreading is an uncommon and often newsworthy event as it typically causes large network congestion and outages.
This page intentionally left blank.







































































