Census Data Field Guide for Transportation Applications (2025)
Chapter: 7 Differential Privacy

CHAPTER 7
Differential Privacy
The Census Bureau is bound by Title 13 of the United States Code. These laws not only provide authority for the work the Bureau does but also provide strong protection for the information the Bureau collects from individuals and businesses. To allay the concerns of respondents, census products are reviewed by the DRB to ensure that no identifiable information is released. Until the 2010 census, the Bureau would “disclosure proof” the data using suppression and swapping techniques. In swapping, entire households are moved from one census block to another to eliminate the possibility of identifying unique households. Figure 7.1 shows the evolution of disclosure avoidance techniques over time.
The increasing availability and use of data from big data sources and sources such as credit bureaus and smartphone applications along with increasing computing power, makes it possible, with some effort, to reconstruct the identity of a respondent. Therefore, the Census Bureau identified differential privacy as a means to enhance disclosure avoidance starting with the 2020 decennial census.
Differential privacy aims to prevent accurate reconstruction attacks while making certain that the data are still useful for statistical analyses. Differential privacy does so by injecting a controlled amount of uncertainty in the form of mathematical randomness, also called noise, into the calculations that are used to develop data products. The range of noise can be shared publicly because an attacker cannot know exactly how much noise was introduced into any particular table. With differential privacy, it is still possible to reconstruct a database, but the database that is reconstructed will include privacy-ensuring noise. In other words, the individual records become synthetic byproducts of the statistical system.
There are different ways to build a system to protect the confidentiality of census data under differential privacy. Two of these are the Laplace mechanism, which adds noise to the data using a Laplace distribution, and randomized response where the response is unobserved by the interviewer. By introducing random noise, the method conceals individual responses and protects respondent privacy.
The issue with these approaches is that they do hold certain values as invariant—data that cannot be altered, such as state population. The 2020 census implementation is the largest deployment of differential privacy using the trusted-curator (centralized) model, with the highest stakes of any deployed formal privacy system because decennial census data are used for apportionment, redistricting, allocation of funds, public policy, and research.
The TopDown Algorithm (TDA) is the name given to the differential privacy mechanisms, optimization algorithms, and associated post-processing that are used for research and production. The TDA generates confidentiality-preserving, person-level, and housing-unit-level data called microdata detail files with demographic and housing-unit information from the resident
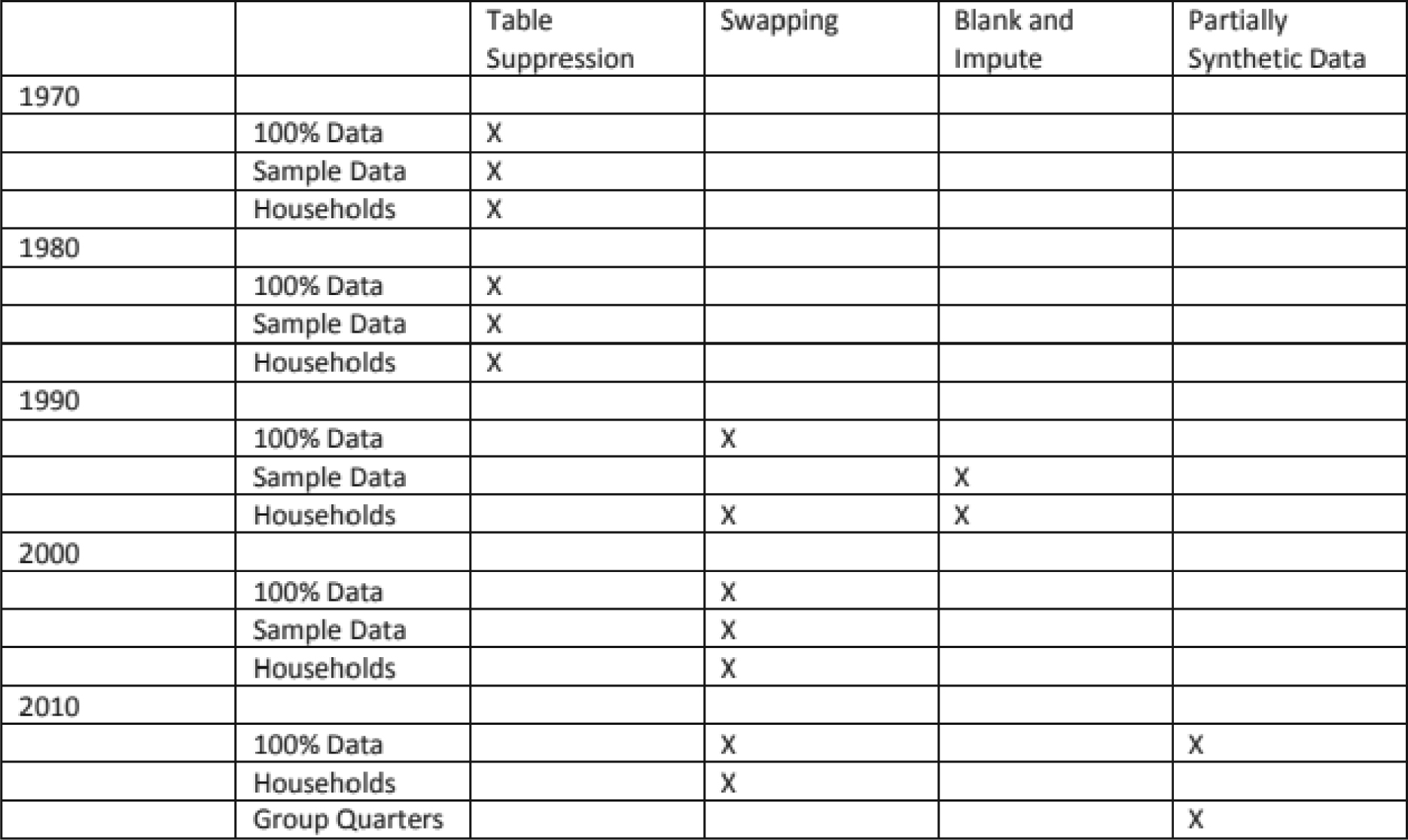
Source: McKenna 2018.
Long Description.
The table presents disclosure avoidance techniques used from 1970 to 2010. The techniques include Table Suppression, Swapping, Blank and Impute, and Partially Synthetic Data. Each row is organized by decade and type of data, such as 100 percent data, sample data, households, and group quarters. In 1970, Table Suppression was used for 100 percent data, sample data, and household data. In 1980, again, Table Suppression was used for 100 percent data, sample data, and household data. In 1990, Swapping was used for 100 percent data. Blank and Impute was used for sample data. Swapping and Blank and Impute were used for household data. In 2000, Swapping was used for 100 percent data, sample data, and household data. In 2010, Swapping and Partially Synthetic Data were used for 100 percent data. Swapping was used for household data. Partially Synthetic Data was used for group quarters data. The table summarizes when and how different data protection techniques were applied over five decades.
populations of the United States and Puerto Rico. The system that carries out the TDA is referred to as the 2020 census disclosure avoidance system (DAS). The DAS is the collection of computer programs that implements statistical disclosure limitation for the Census. It replaces the record-swapping system used from 1990 to 2010 for decennial censuses (see Figure 7.2 for an explanation of how the TDA works).
The Census Bureau opted to focus on a top-down approach to maximize utility for redistricting and funding allocation (boyd 2019). By understanding how data users might cross tabulate variables or otherwise conduct statistical analyses, noise could be added to cells in the tables to make it difficult to discern individuals. To do this well requires a good understanding of how different statistical tables interact with each other. A top-down approach can produce more tailored statistical tables because noise is injected in ways that preserve the most important statistical efforts. If race is the most important variable, more noise can be introduced to the age variable to preserve the accuracy of the race variable. If one table is more important than another, more noise can be provided to the less-frequently-used table than the one that is more essential. While this control is an asset, it also introduces significant governance and policy implications.
The purpose of introducing noise to statistical tables is to reduce the amount of leaked information. While constructing a differentially private system, it is necessary to make tradeoffs about how much noise is tolerable and how much risk, or total privacy loss, is acceptable. The creators of a differentially private system set a maximum cumulative privacy-loss budget. This is defined by the variable epsilon. Details of how epsilon works and its implications are provided by boyd (2019):
Epsilon can be conceptually understood as a set of knobs. Dialing the knobs one way creates higher levels of noise but lower levels of confidentiality risk. Dialing the knobs the other way results in more accurate data, but increases the risk to confidentiality (and, therefore, “privacy loss”). The system has a global privacy-loss budget, but each geographic level and table also has a local privacy-loss budget that must

Source: U.S. Census Bureau 2021. https://www2.census.gov/library/publications/decennial/2020/2020-census-disclosure-avoidance-handbook.pdf.
Long Description.
The document explains how the TopDown Algorithm works in five steps. Step 1 states that after the confidential Census Edited File is input into the Disclosure Avoidance System, the TopDown Algorithm takes many differentially private noisy measurements. Step 2 says the algorithm uses these measurements to make privacy-protected microdata records for the whole nation. Step 3 says the records include every level of geography in the Census Bureau’s hierarchy. The records are based on the noisy measurements taken at each geographic level and follow population rules and constraints. Step 4 says the microdata records are used in the tabulation system to make redistricting data products. Step 5 says the final data reflect privacy guarantees from the privacy-loss budget for the 2020 Census. These data hold the highest uncertainty at the census block level and provide more accurate population data at higher geography levels. A footnote defines the 2020 Census Edited File as the individual census responses that have been processed through quality control steps like filling in missing data.
be managed to ensure that the interaction of all tables does not result in leakage that exceeds the global amount. The actual local budget is a combination of the particular table and geographic level. Because of these locally defined epsilons, it is possible to introduce more noise to a specific variable (e.g., sex) than others (e.g., race).
Per boyd (2019), differential privacy implies a set of interconnected tradeoffs. The lower the amount of noise injected into one particular table, the greater the accuracy of that table. Greater accuracy of one table means that less accuracy is available for other tables because the total epsilon, or privacy-loss budget, is fixed. Once the privacy-loss budget is determined, the available accuracy must be shared among all the published tables. Increasing the accuracy of some tables without reducing the accuracy of others can only be accomplished by increasing the total privacy-loss budget and, therefore, increasing the risk of confidentiality violations. New tables do not inherently increase the privacy loss. For example, the first large file that the Census Bureau produces (the PL 94-171) is going to leak a lot of information. But if a new data product has significant overlap with this data file and just introduces one new variable—say, sex—the amount of leakage introduced by the second data product is not as high.
Setting epsilon as a mathematical variable requires making a numerical choice between approximately zero (∼0) and infinity. Technically, this decision could be revised over time to reduce the noise if that becomes important. De facto, all census data are made available 72 years after the census, when the data become public by law. Once the global epsilon is set, decisions need to be made about how to “spend” that budget based on the privacy loss of every statistical table that will be produced. These decisions have significant consequences because they govern

Source: boyd 2019.
Long Description.
The flowchart shows the data collection and processing pipeline used in the 2000 and 2010 censuses. The first step is raw data from respondent, labeled as Decennial Response File. The next step is selection of output variables, labeled as Census Unedited File. This is followed by the edit and imputation stage, labeled as Census Edited File. Next is the confidentiality edits step, for instance using a swapping process, and tabulation recodes, labeled the Hundred-percent Detail File (HDF). From this point, the flow splits into two outcomes. One path leads to pre-specified tabular summaries, including PL 94-171, SF 1, SF 2, (SF3, SF4,.. in 2000). The other path leads to special tabulations and post-census research.
the tradeoff between confidentiality and accuracy, which affects data utility. The data must be fit for purpose and determining those purposes must be done up front to define the level of accuracy and noise in individual census products.
The differences between the 2000/2010 census and the 2020 census can be seen in a comparison of Figure 7.3 and Figure 7.4. In 2020, the new approach started following the development of the Census Edited File, when the DAS was introduced along with the supporting concepts of accuracy decisions and the privacy-loss budget.
To implement differential privacy, two major questions must be answered before the DAS is run: the global privacy-loss budget (or global epsilon) and the allocation of the budget across all of the tables and features (local privacy-loss budget allocation). This means determining in advance all of the data products that will be produced. Further, certain data (such as state population) have to be kept invariant, which further constrains the data that will be released.
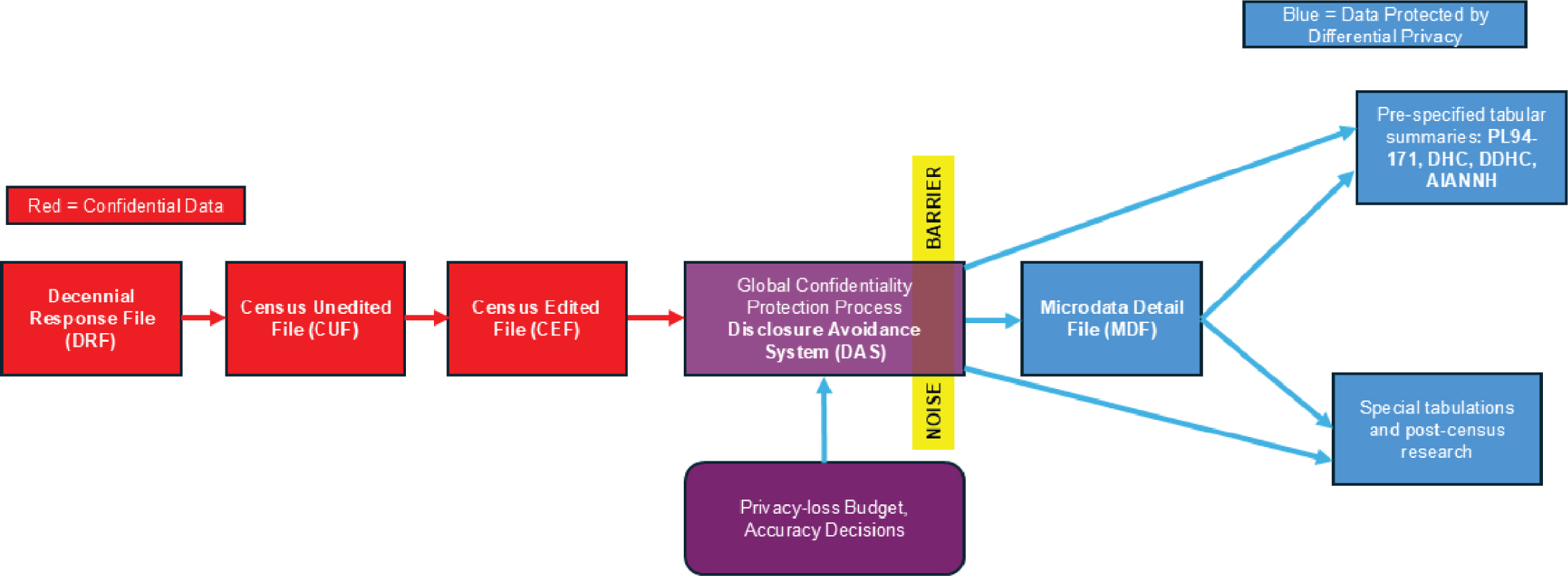
Source: boyd 2019.
Note: DHC = Demographic and Housing Characteristics File; DDHC = Detailed Demographic and Housing Characteristics File; AIANNH =American Indian, Alaska Native, Native Hawaiian
Long Description.
The flowchart presents the data collection and processing pipeline for the 2020 census. It begins with the Decennial Response File, labeled DRF. The next step is the Census Unedited File, labeled CUF. This is followed by the Census Edited File, labeled CEF . The next step is the Global Confidentiality Protection Process, also called the Disclosure Avoidance System, labeled DAS. This step receives input from a Feedback Loop for Privacy-Loss Budget and Accuracy Decisions. After this, the process outputs the Microdata Detail File, labeled M DF. From MDF, two outputs are created. One is pre-specified tabular summaries including PL 94-171; Demographic and Housing Characteristics; Detailed Demographic and Housing Characteristics ; and American Indian, Alaska Native, Native Hawaiian. The other is special tabulations and post-census research.
In addition, to prevent confusion, the DAS team has decided that all cells must contain positive whole numbers. These decisions by the Census Bureau have implications for the transportation community (discussed in Section 7.2).
7.1 Issues with Differential Privacy
Differential privacy can cause issues with data including the following:
- Data for very small demographic groups and geographic areas, such as census blocks, may be too noisy for a particular use and should be aggregated into larger geographic areas before use.
- Noise infusion results in some implausible results, such as a block with more occupied housing units than people to occupy those units.
- The complexity of the methods makes it difficult to communicate how disclosure avoidance works and what it means for data applications.
7.2 Implications of Differential Privacy for Transportation Modelers and Planners
The transportation community relies on small geography data such as TAZs, block groups, and parcels to do the analysis expected by transportation modelers and planners. If the Census Bureau decides to release data that are suppressed using differential privacy, transportation modelers and planners could lose confidence in the data. In the following, the research team considers the implications of three key decisions:
- Determining data products in advance. Because of the need for a global privacy loss budget and its allocation across all tables and features, the Census Bureau will determine what products will be produced. As a result, the transportation community may not be able to get the products it needs for analytical and planning purposes.
- Invariants. Invariant statistics for the 2020 census redistricting data are
- Total number of people in each state, the District of Columbia, and Puerto Rico.
- Total number of housing units in each census block.
- Number of occupied group quarters facilities by major group quarter type in each census block (e.g., correctional facilities, nursing facilities, college dorms, and military quarters).
- Using only positive whole numbers. Adding noise without going negative implies that small blocks will get bigger and, in turn, because the state-level number is kept invariant, the larger blocks will get smaller. This can distort the TAZs used by transportation planners and modelers and has implications for data quality and analysis results.




